

Apache Kafka is an Open-source Stream Processing and Management Platform that receives, stores, organizes, and distributes data across different end-users or applications. As users can push hundreds and thousands of messages or data into Kafka Servers, there can be issues like Data Overloading and Data Duplication. Due to these problems, data present in the Kafka Servers often remains unorganized and confounded.
Consequently, consumers or end-users cannot effectively fetch the desired data from Kafka Servers. To eliminate the complications of having messy and unorganized data in the Kafka Servers, users can create different Kafka Topics in a Kafka Server.
It allows users to store and organize data according to different categories and use cases, allowing users to easily produce and consume messages to and from the Kafka Servers.
In this article, you will learn about Kafka Topics and follow step-by-step instructions for creating them within a Kafka Server. Read on!
Table of Contents
What is Apache Kafka?

Apache Kafka is an Open-Source and Distributed Stream Processing platform that stores and handles real-time data. In other words, Kafka is an Event Streaming service that allows users to build event-driven or data-driven applications.
Since Kafka is used for sending (publish) and receiving (subscribe) messages between processes, servers, and applications, it is also called a Publish-Subscribe Messaging System.
By default, Kafka has effective built-in features of partitioning, fault tolerance, data replication, durability, and scalability. Because of such effective capabilities, Apache Kafka is being used by the world’s most prominent companies, including Netflix, Uber, Cisco, and Airbnb.
What is a Kafka Topic?

Kafka topic is a category or feed name to which records (messages) are published by producers. Topics allow Kafka to organize and stream vast amounts of real-time data. In simpler terms, topics act like channels for different data streams within Kafka. Each topic in Kafka should have a unique and identifiable name to differentiate it across various Kafka Brokers in a Kafka Cluster.
Key Points:
- Use Case- Topics in Kafka are used to categorize and organize events within a Kafka cluster.
- Kafka Partitions- A topic is divided into partitions, which allow the topic to scale horizontally across multiple Kafka brokers. Partitions enable parallel data processing and ensure the system can handle high-throughput workloads.
- Append-only mode?- Whenever a new message is found, it is added at the end of the topic, thereby creating a Log File.
- Consumer/Producer Relationship: Producers push messages into the tail of the newly created logs while consumers pull messages off from a specific category, facilitating the data flow.
- Logical Segregation: Users can perform logical segregation between Messages and Events, which works the same as the concept of different tables having different types of data in a database.
Hevo Data offers seamless integration with Apache Kafka, enabling you to automatically extract, process, and move streaming data from Kafka topics to a wide range of destinations like data warehouses, lakes, and BI tools.
What Hevo Offers?
- Automated Schema Mapping: Hevo automatically detects and adjusts schema changes, ensuring a smooth data transfer from Kafka to the destination.
- No-code Integration: Connect Kafka with Hevo easily, without needing to write code or manage complex configurations.
- Real-time Data Sync: Stream data from Kafka in real-time to destinations like Snowflake, BigQuery, or Redshift for instant analytics.
Examples of Kafka Topics
Kafka topics are used to store different types of data. Here are a few examples:
- orders: Stores order-related information
- website_clicks: Captures data on website interactions
- network_events: Records network event data
- customers: Holds customer-related details
- temperature_readings: Stores data from temperature sensors
- vehicle_location: Tracks GPS locations of vehicles
What Is Kafka Topic Partition?
Apache Kafka’s single biggest advantage is its ability to scale. If Topics were constrained to a single Machine or Cluster, this would be its biggest hindrance to scaling. Luckily, Apache Kafka has a solution for this.
Apache Kafka divides Topics into several Partitions. For better understanding, you can imagine Kafka Topic as a giant set and Kafka Partitions to be smaller subsets of Records that belong to the topic. Each Record holds a unique sequential identifier called the Offset, which gets assigned incrementally by Apache Kafka. This helps Kafka Partition to work as a single log entry, which gets written in append-only mode.
The way Kafka Partitions are structured gives Apache Kafka the ability to scale with ease. Kafka Partitions allow Topics to be parallelized by splitting the data of a particular Topic across multiple Brokers. Each Broker holds a subset of Records that belongs to the entire Kafka Cluster.
Apache Kafka achieves replication at the Partition level. Redundant units in Topic Partitions are referred to as Replicas, and each Partition generally contains one or more Replicas. That is, the Partition contains messages that are replicated through several Kafka Brokers in the Cluster. Each Partition (Replica) has one Server that acts as a Leader and another set of Servers that act as Followers.

A Kafka Leader replica handles all read/write requests for a particular Partition, and Kafka Followers imitate the Leader. Apache Kafka is intelligent enough, that if in any case, your Lead Server goes down, one of the Follower Servers becomes the Leader. As a good practice, you should try to balance the Leaders so that each Broker is the Leader of the same number of Partitions.
When a Producer publishes a Record to a Topic, it is assigned to its Leader. The Leader adds the record to the commit log and increments the Record Offset. Kafka makes Records available to consumers only after they have been committed, and all incoming data is stacked in the Kafka Cluster.
Each Kafka Producer uses metadata about the Cluster to recognize the Leader Broker and destination for each Partition. Kafka Producers can also add a key to a Record that points to the Partition that the Record will be in, and use the hash of the key to calculate Partition. As an alternative, you can skip this step and specify Partition by yourself.
Let us look at an example to understand Kafka topics with its partitions.

Kafka Topics
Consider a topic with three partitions labeled 0, 1, and 2. Each partition possesses distinct offset numbers, distributing data across each offset within the respective partition. Notably, the data in offset 1 of Partition 0 is unrelated to the data in offset 1 of Partition 1. However, there is interdependence between the data in offset 1 of Partition 0 and the data in offset 2 of Partition 0.
Brokers

In this context, Apache Kafka plays a crucial role. A Kafka cluster consists of one or more servers known as brokers or Kafka brokers. Each broker, identified by an integer ID, acts as a container holding multiple topics with their corresponding partitions. Brokers are also referred to as Bootstrap brokers because connecting to any one broker establishes a connection with the entire cluster. Although a broker doesn’t store the entire dataset, each broker in the cluster is aware of other brokers, partitions, and topics.
Example
Imagine a Kafka cluster comprising three brokers: Broker 1, Broker 2, and Broker 3.
Broker Setup

Each broker hosts a topic, say Topic-x, with three partitions (0, 1, and 2). It’s important to note that partitions are distributed among brokers, and a broker may contain partitions from various topics. Broker 1 and Broker 2 also possess another topic, Topic-y, with two partitions (0 and 1). Broker 3, however, does not store any data from Topic-y. It’s worth emphasizing that there is no inherent correlation between broker numbers and partition numbers.
How to Create Apache Kafka Topics?
Here are the simple 3 steps used to Create an Apache Kafka Topic:
- Step 1: Setting up the Apache Kafka Environment
- Step 2: Creating and Configuring
- Step 3: Send and Receive Messages
Step 1: Setting up the Apache Kafka Environment
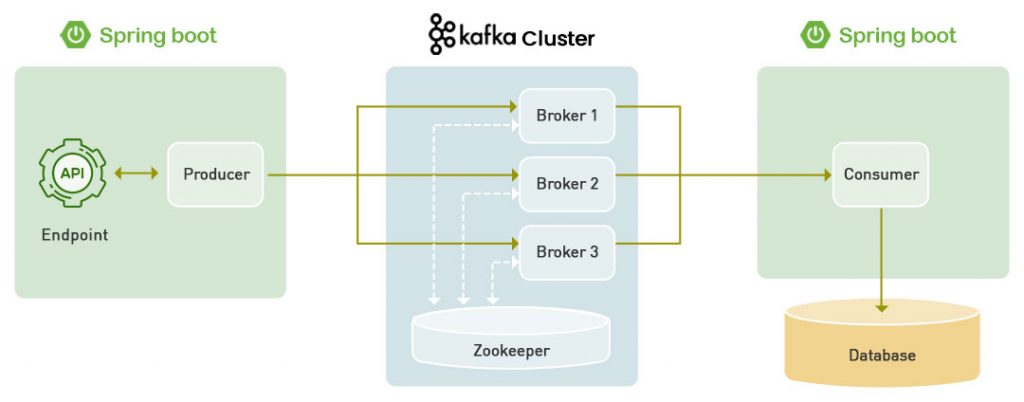
In this method, you will be creating Topics using the default command-line tool, i.e., command prompt. In other words, you can write text commands in the command prompt terminal to create and configure Topics.
Below are the steps for creating and configuring the newly created topics to send and receive messages.
- To begin, you must start and set up the Kafka Environment. Before that, make sure that Kafka and Zookeeper are pre-installed, configured, and running on your local machine. You must also ensure that the Java 8+ Version is installed and running on your computer. Then, configure the file path and Java_Home environment variables to enable your operating system to locate the Java utilities.
- To start Apache Kafka, open a new command prompt and enter the below command:
.binwindowskafka-server-start.bat .configserver.properties- To start Zookeeper, open another command prompt and enter the below command. Generally, Apache Kafka uses Zookeeper to manage and store all the Metadata and Cluster Information. As a result, you have to run the Zookeeper Instance along with Kafka during message transfer.
zookeeper-server-start.bat .configzookeeper.propertiesNow, Kafka and Zookeeper have started and are running successfully.
Step 2: Creating and Configuring
- In the further steps, you will be seeing how to create Kafka Topics and configure them for efficient message transfer.
- For creating a new Topic, open a separate command prompt window:
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test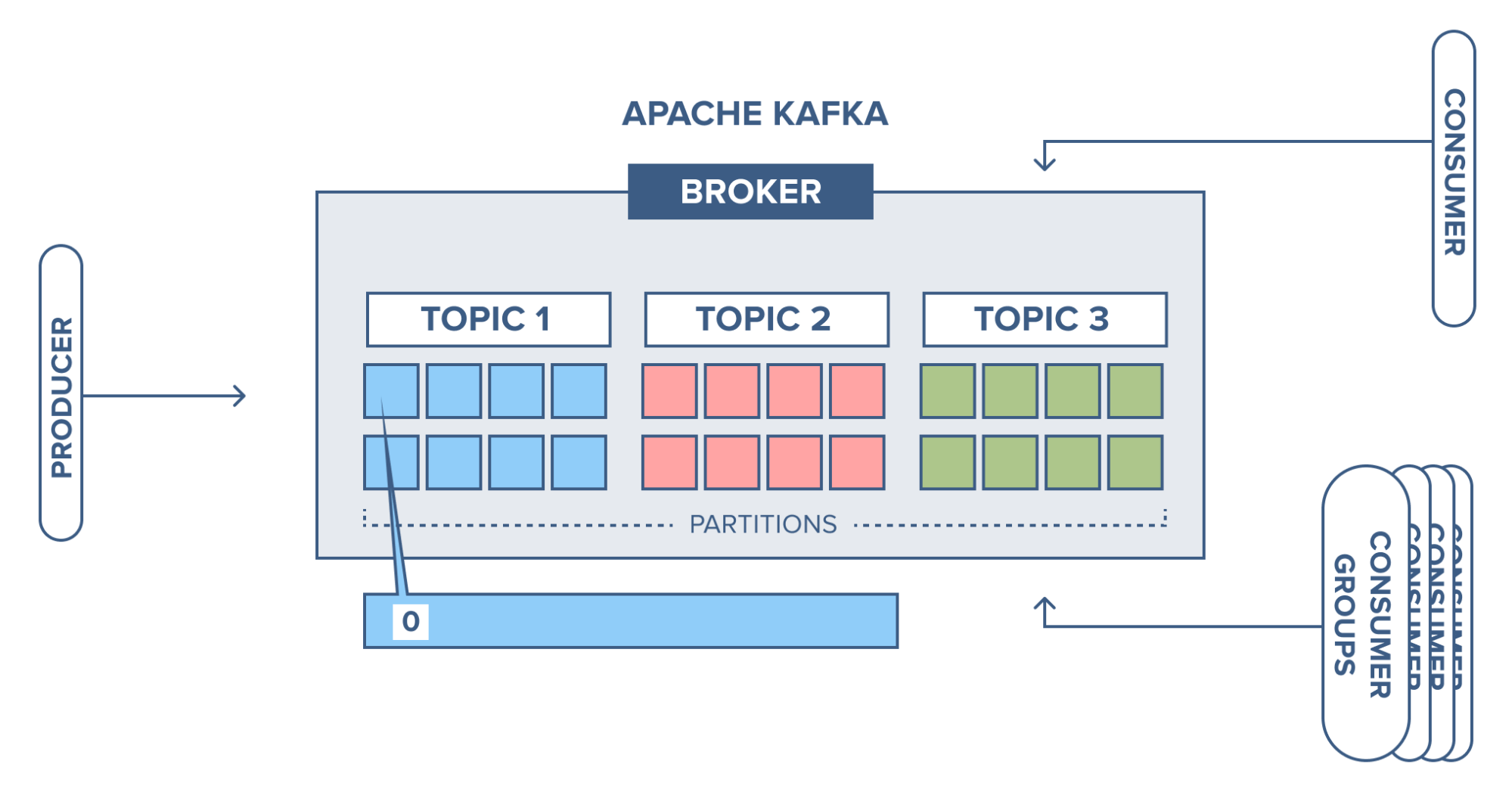
When the above command is executed successfully, you will see a message in your command prompt saying, “Created Topic Test.” With the above command, you have created a new topic called Topic Test with a single partition and one replication factor.
The command consists of attributes like Create, Zookeeper, localhost:2181, Replication-factor, Partitions:
- Create: It is a basic command for creating a new Kafka topic.
- Partitions: The newly created Topics can be divided and stored in one or more Partitions to enable uniform scaling and balancing of messages or loads. In the above-mentioned basic command, you will be creating only one Partition. When a Kafka Server is handling or streaming large data, you can even have Ten Partitions for a single Topic and 10,000 Partitions per Kafka Cluster.
- Replication Factor: The Replication Factor defines the number of copies or replicas of a Topic across the Kafka Cluster. If you give the Replication Factor as 1, you are making one copy or replication of your newly created Topic. Similarly, when you provide the Replication Factor as 2, you make two copies for the respective Topic. This Replication feature ensures the Kafka Server to be highly fault-tolerant. Since it replicates and spreads the topics across other Kafka Servers, if one of the servers fails, the topic/data will be available on other servers.
- Zookeeper localhost:2181: This attribute states that your Zookeeper instance runs on port 2181. When you enter the command to create Topics in Kafka, the command will be redirected to the Zookeeper instance running along with Kafka.
Topics should always have a unique name for differentiating and uniquely identifying between other topics to be created in the future. In this case, you are giving a “Topic Test” as a unique name to the Topic. This name can be used to configure or customize the topic elements in further steps.
In the above steps, you have successfully created a new Topic. You can list the previously created Topics using the command given below.
'kafka-topics.bat -zookeeper localhost:2181 -list'.You can also get the information about the newly created Topic by using the following command. The below-given command describes the information of Kafka Topics like topic name, number of partitions, and replicas.
kafka-topics.bat -zookeeper localhost:2181 -describe --topic <the_topic_name>After creating topics in Kafka, you can start producing and consuming messages in the further steps. By default, you have “bin/kafka-console-producer.bat” and “bin/kafka-console-consumer.bat” scripts in your main Kafka Directory. Such pre-written Producer and Consumer Scripts are responsible for running Kafka Producer and Kafka Consumer consoles, respectively.
Initially, you have to use a Kafka Producer for sending or producing Messages into the Topic. Then, you will use Kafka Consumer for receiving or consuming messages from Topics.
For that, open a new command prompt and enter the following command.
kafka-console-producer.bat --broker-list localhost:9092 --topic testAfter the execution of the command, you can see the ” > ” cursor that is frequently blinking. Now, you can confirm that you are in the Producer Console or Window.
Once the Kafka producer is started, you have to start the Kafka consumer. Open a new command window and enter the below command according to your Kafka versions. If you are using an old Kafka version (<2.0 version), enter the command given below.
kafka-console-consumer.bat --zookeeper
localhost:2181 --topic testIf you are using the recent Kafka versions (>2.0 version), enter the command given below.
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginningIn the above commands, the Topic Test is the name of the Topic inside which users will produce and store messages in the Kafka server. The same Topic name will be used on the Consumer side to Consume or Receive messages from the Kafka Server.
After implementing the above steps, you have successfully started the Producer and Consumer Consoles of Apache Kafka. Now, you can write messages in the Producer Panel and receive Messages in the Consumer Panel.
Step 3: Send and Receive Messages
Open both the Apache Kafka Producer Console and Consumer Console parallel to each other. Start typing any text or messages in the Producer Console. You can see that the messages you are posting in the Producer Console are Received and Displayed in the Consumer Console.
By this method, you have configured the Apache Kafka Producer and Consumer to write and read messages successfully.
You can navigate to the Data Directories of Apache Kafka to ensure whether the Topic Creation is successful. When you open the Apache Kafka Data Directory, you can find the topics created earlier to store messages. In the directory, such Topics are represented in the form of folders.
If you have created Partitions for your Topics, you can see that the Topic Folders are separated inside the same directory according to the given number of partitions. In the Kafka Data Directory, you will see several files named “Consumer Offsets” that store all the information about the consumer configuration and messages according to the Apache Kafka Topics.
From these steps, you can confirm and ensure that Apache Kafka is properly working for message Producing and Consuming operations.
Where are Kafka topics stored?
Kafka topics are stored distributed across the Kafka cluster. Specifically, each Kafka partition belonging to a topic is an ordered, immutable sequence of records that is continually appended to. These partitions are distributed over the servers in the Kafka cluster with certain numbers of partitions assigned to each server.
The partitions get stored as log files on the filesystem of the Kafka brokers. Each log file contains data for only a single partition. Inside the log file, data is stored in the order it was received by the partition. So the physical storage location of a topic is split up across many brokers within a cluster, with each broker storing one or more of the topic’s partitions in local log files on disk.
How to View a List of Kafka Topics?
1. Using the kafka-topics.sh script:
This is the recommended method for accessing the Kafka CLI tools. It comes bundled with Apache Kafka and is available on all platforms. Here’s how to use it:
kafka-topics.sh --bootstrap-server <BOOTSTRAP_SERVER> --list- Replace
<BOOTSTRAP_SERVER>with the address of your Kafka broker (e.g.,localhost:9092). - The
--listoption tells the script to list all available topics. - This method also works with older versions of Kafka using the
--zookeeperoption instead of--bootstrap-server.
2. Using the Kafka AdminClient API:
If you’re working with Kafka in code, you can use the AdminClient API to list topics. Here’s an example in Java:
Properties props = new Properties();
props.put("bootstrap.servers", "<BOOTSTRAP_SERVER>");
AdminClient adminClient = AdminClient.create(props);
List<String> topics = adminClient.listTopics().names();
adminClient.close();
for (String topic : topics) {
System.out.println(topic);
}- Remember to replace
<BOOTSTRAP_SERVER>with your actual value. - This method gives you more control over filtering and formatting the output.
How to Clear a Kafka Topic?
To delete a Kafka topic, first check a few parameters:
- For Kafka versions 2.2 and above, employ the Kafka hostname and port (e.g., localhost:9092).
- For older Kafka versions, utilize the Zookeeper URL and port (e.g., localhost:2181).
- Utilize the kafka-topics.sh CLI, incorporating the –delete option.
- Confirm that the Kafka brokers permit topic deletion with the setting delete.topic.enable=true (default).
Example
Removing the topic named “first_topic” while my Kafka broker operates on localhost:9092.
kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic first_topickafka-topics.sh --zookeeper localhost:2181 --delete --topic first_topicConclusion
In this article, you have learned about Apache Kafka, Apache Kafka Topics, and steps to create them. You have learned the Manual Method of creating Topics and customizing Topic Configurations in Apache Kafka by the command-line tool or command prompt.
However, you can also use the Kafka Admin API, i.e., TopicBuilder Class, to programmatically implement the Topic Creation operations. By learning the manual method as a base, you can explore the TopicBuilder method later.
FAQ
1. What is an event and topic in Kafka?
In Kafka, an event (or message) is a record of something that happened, typically containing a key, value, and timestamp. A topic is a named channel where events are published, and it acts as a category for organizing data streams.
2. What is Kafka with an example?
Kafka is a distributed event streaming platform used for building real-time data pipelines and applications. For example, in an e-commerce site, Kafka can stream real-time order data from the application to a central analytics system, ensuring all systems are up-to-date.
3. Is Kafka topic a queue?
No, a Kafka topic is not a queue. While Kafka can behave like a queue in some scenarios, topics are more like logs. Consumers can read from any point in a topic, and Kafka allows multiple consumers to consume data independently, unlike traditional queues where each message is consumed only once.
4. What is the publish-subscribe pattern in Kafka?
In Kafka, producers write messages to topics, and consumers read messages from topics. This publish-subscribe pattern lets producers send messages without waiting for consumers to process them.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




