
MongoDB database is a NoSQL, general-purpose program that uses JSON-like documents to store its data. The JSON-like documents provide a flexible and dynamic schema while maintaining simplicity, unlike relational databases that use tabular relationships.
Since NoSQL databases can scale horizontally, they are suitable for real-time and big-data applications. Businesses might often require to set up a MongoDB Aggregation Pipeline for their use case. And that is why it is imperative to learn about the ways you can do that.
This article talks about the different steps you can follow to set up an aggregation pipeline in MongoDB seamlessly. It also gives a brief introduction to MongoDB, its key features, key operators, stages of setting up the pipeline, examples, limitations, and best practices to name a few.
Table of Contents
What is MongoDB?

- MongoDB is a NoSQL open-source document-oriented database developed for storing and processing high volumes of data.
- Compared to conventional relational databases, MongoDB makes use of collections and documents instead of tables consisting of rows and columns. The Collections consist of several documents and documents containing the basic units of data in terms of key and value pairs.
- Introduced in February 2009, the MongoDB database is designed, maintained, and managed by MongoDB.Inc under SSPL(Server Side Public License).
- Organizations such as Facebook, Nokia, eBay, Adobe, Google, etc., prefer it for efficiently handling and storing their exponentially growing data.
- It offers complete support for programming languages such as C, C++, C#, Go, Java, Node.js, Perl, PHP, Python, Motor, Ruby, Scala, Swift, and Mongoid.
As the ability of businesses to collect data explodes, data teams have a crucial role to play in fueling data-driven decisions. Yet, they struggle to consolidate the data scattered across sources into their warehouse to build a single source of truth. Broken pipelines, data quality issues, bugs and errors, and lack of control and visibility over the data flow make data integration a nightmare.
1000+ data teams rely on Hevo’s Data Pipeline Platform to integrate data from over 150+ sources in a matter of minutes.
Check out why Hevo is the Best:
- Completely Automated: Set up in minutes with minimal maintenance.
- 24/5 Live Support: Round-the-clock support via chat, email, and calls.
- Schema Management: Automatic schema detection and mapping.
- Live Monitoring: Track data flow and status in real time.
Key Features of MongoDB
With constant efforts from the online community, MongoDB has evolved over the years. Some of its eye-catching features are:
- High Data Availability & Stability: MongoDB’s Replication feature provides multiple servers for disaster recovery and backup. Since several servers store the same data or shards of data, MongoDB provides greater data availability & stability.
- Accelerated Analytics: You may need to consider thousands to millions of variables while running Ad-hoc queries. MongoDB indexes BSON documents and utilizes the MongoDB Query Language (MQL) that allows you to update Ad-hoc queries in real-time.
- Indexing: With a wide range of indices and features with language-specific sort orders that support complex access patterns to datasets, MongoDB provides optimal performance for every query. For the real-time ever-evolving query patterns and application requirements, MongoDB also provisions On-demand Indices Creation.
- Horizontal Scalability: With the help of Sharding, MongoDB provides horizontal scalability by distributing data on multiple servers using the Shard Key. Each shard in every MongoDB Cluster stores parts of the data, thereby acting as a separate database.
What is the MongoDB Aggregation Pipeline?
When dealing with a database management system, any time you extract data from the database you need to execute an operation called a query. However, queries only return the data that already exists in the database. Therefore, to analyze your data to zero in on patterns or other information about the data – instead of the data itself – you’ll often need to perform another kind of operation called aggregation.
MongoDB allows you to perform aggregation operations through a mechanism called MongoDB Aggregation Pipelines. These are essentially built as a sequential series of declarative data operations called stages.
Each stage can then inspect and transform the documents as they pass through the pipeline, putting the transformed data results into the subsequent stages for further processing. Documents from a chosen collection get into a pipeline and go through each stage, where the output coming from each stage becomes the input for the next stage, and the final result is obtained at the end of the pipeline.
Stages can help you perform operations like:
- Sorting: You can reorder the documents based on a chosen field.
- Filtering: This operation resembles queries, where the list of documents can be narrowed down through a set of criteria.
- Grouping: With this operation, you can process multiple documents together to generate a summarized result.
- Transforming: Transforming refers to the ability to modify the structure of documents. This means you can rename or remove certain fields, or perhaps a group, or rename fields within an embedded document for legibility.
What are the Operators in MongoDB Aggregation Pipeline?
MongoDB provides you with an exhaustive list of operators that you can use across various aggregation stages. Each of these operators can be used to construct expressions for use in the aggregation pipeline stages. Operator expressions are similar to functions that use arguments. Generally, these expressions use an array of arguments and have the following format:
{ <operator> : [ <argument1>, <argument2>, ... ] }However, if you only want to use an operator that accepts a single argument, you can omit the array field. It can be used in the following format:
{ < operator> : <argument> }Different Operators in MongoDB Aggregation Pipeline
- Comparison Expression Operators: This returns a boolean, except for $cmp, which will return a number.
- Arithmetic Expression Operators: These operators will perform mathematical operations on numbers.
- Array Expression Operators: With Array Expression Operators, you can perform operations on arrays.
- Boolean Expression Operators: These operators evaluate their argument expressions as booleans and return a boolean as a result.
- Literal Expression Operators: Literal Expression Operators can return a value without having to parse it first.
- Conditional Expression Operators: With Conditional Expression Operators, you can help build conditional statements.
- Custom Aggregation Expression Operators: You can use custom aggregation expression operators to define custom aggregation functions.
- Object Expression Operators: These allow you to merge or split documents.
- Date Expression Operators: Date expression operators returns date components or objects of a given date object.
- Text Expression Operators: These operators allow you to access per-document metadata per aggregation.
- String Expression Operators: With the help of these operators, you can perform well-defined behavior for strings of ASCII characters.
- Trigonometry Expression Operators: These operators can perform trigonometric operations on numbers.
- Type Expression Operators: You can use these operators to perform operations on the data type.
- Variable Expression Operators: These operators can define variables for use within the scope of a subexpression and return the result of that subexpression.
What are the 7 Key MongoDB Aggregation Pipeline Stages?
Every stage of the MongoDB Aggregation Pipeline transforms the document as the documents pass through it. However, once an input document passes through a stage, it doesn’t necessarily produce one output document. Some stages might create more than one document as a result.
MongoDB offers its users the db.collection.aggregate() method in the mongo shell along with the db.aggregate() command to run the aggregation pipeline. A stage can show up multiple times within a pipeline, with the exception of $merge, $out, and $geoNear stages.



$match
This MongoDB Aggregation Pipeline stage filters the document stream to allow only matching documents to pass unmodified into the next pipeline stage. For every input document, the output is either zero documents (no match) or one document (a match).
$group
With this MongoDB Aggregation Pipeline stage, you can group input documents by a specified identifier expression and apply the accumulator(s) expressions, if mentioned, to every group. $group ends up consuming all input documents and gives one document per each distinct group. The output documents will only contain the identifier fields, and if mentioned, the accumulated fields.
$project
This MongoDB Aggregation Pipeline stage can reshape every document in the stream, for instance, by adding new fields or getting rid of existing fields. For every input document, you can provide one document as an output.
$sort
With $sort, you can reorder the document streams with a specified sort key. The documents are unmodified, leave for the order of the documents. For every input document, the output for this MongoDB Aggregation Pipeline stage is a single document.
$skip
$skip allows you to skip the first n documents where n is the specified skip number and passes the remaining documents unamended to the pipeline. For every input document, the output for this MongoDB Aggregation Pipeline stage is either a zero document (after the first n documents) or one document (for the first n documents).
$limit
This MongoDB Aggregation Pipeline stage allows you to pass the first n documents unamended to the pipeline where n is the specified limit. For every input document, the output is either a zero document (after the first n documents) or one document (for the first n documents).
$unwind
This MongoDB Aggregation Pipeline can break an array field from the input documents and outputs one document for every element. Every output document will contain the same field, but the array field gets replaced by an element value per document. For every input document, $unwind will output n documents where n is the number of elements and could even be zero for an empty array.
For more information on MongoDB Aggregation Pipeline stages, you can give MongoDB Aggregation Pipeline Stages a read.
How to Setup the MongoDB Aggregation Pipeline?
Step 1: Select the Stages View
- In the aggregation pipeline pane, ensure the {} Stages toggle switch is selected.
Step 2: Add an Aggregation Stage
- At the bottom of the aggregation pipeline pane, click the + Add Stage button.
Step 3: Select an aggregation pipeline stage
- On the upper-left corner of the aggregation stage card, click the Select drop-down menu and select the aggregation pipeline stage to use for the first stage of the pipeline.
Step 4: Fill in your pipeline stage
- Fill in your selected stage. You can adjust the width of the pipeline stage by dragging its border to the right.
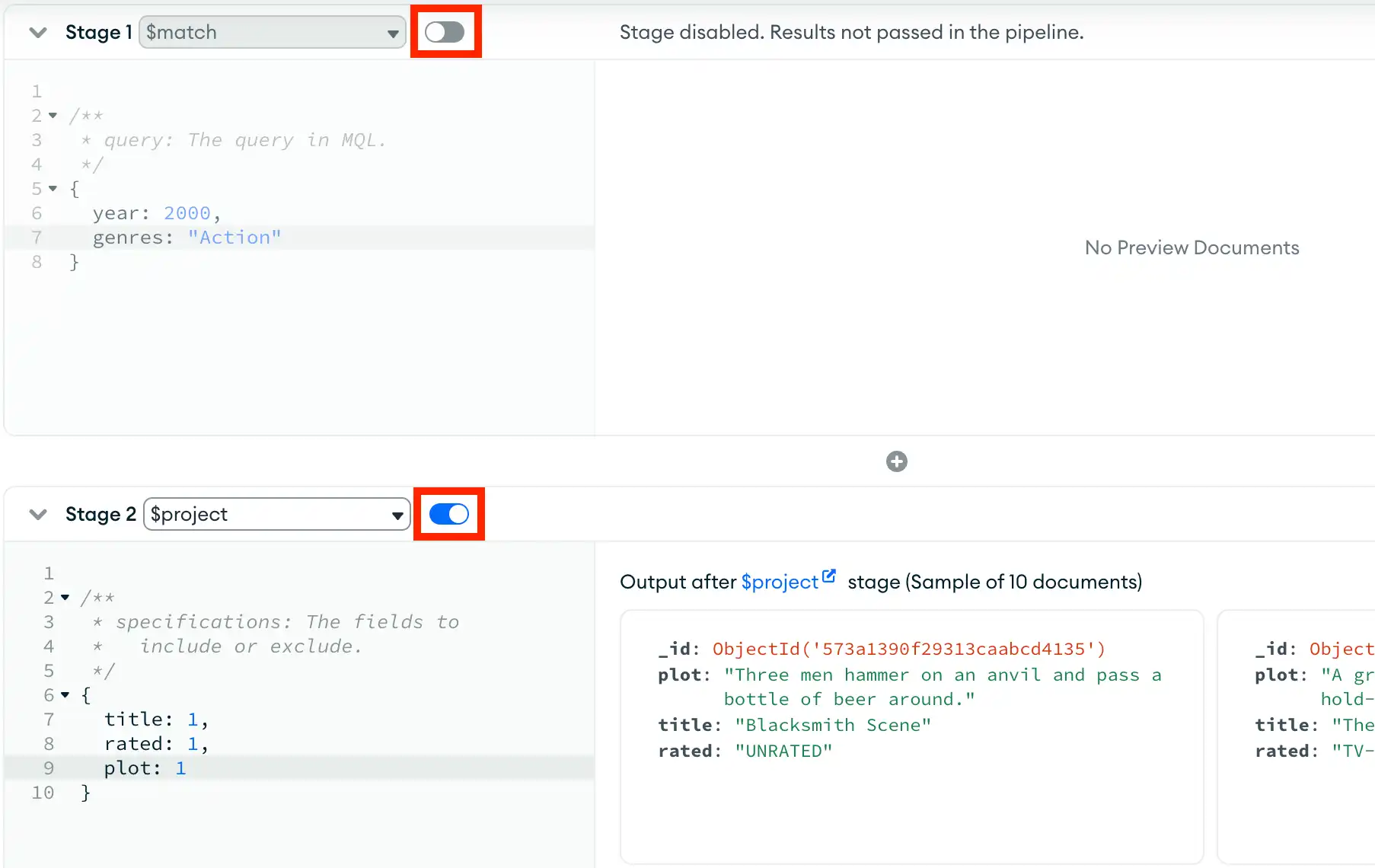
Note: The toggle to the right of each pipeline stage name dictates whether that stage is included in the pipeline. Toggling a pipeline stage also updates the pipeline preview, which updates based on whether or not that stage is included.
For example, the following pipeline excludes the first $match stage and only includes the $project stage:
Step 5: Add additional pipeline stages
- To add an additional pipeline stage after your last aggregation stage, click Add Stage. To add an aggregation stage before your most recently added stage, click the + icon above the stage card.
- Repeat steps 3 and 4 for each additional stage.
Note: You can change the order of pipeline stages by dragging the header of each stage card.
Step 6: Run the pipeline
- At the top-right corner of the pipeline builder, click Run. Compass returns your results in the document view.

Additional Resources:
Read about how you can set up the MongoDB Aggregation Pipeline using the Stage Wizard, Focus Mode, and Text View Mode.
Examples of MongoDB Aggregation Pipelines
If you consider this test “posts” collection:
{
"title" : "my first blog",
"author" : "John",
"likes" : 4,
"tags" : ["angular", "react", "python"]
},
{
"title" : "my second blog",
"author" : "John",
"likes" : 7,
"tags" : ["javascript", "ruby", "vue"]
},
{
"title" : "hello city",
"author" : "Ruth",
"likes" : 3,
"tags" : ["vue", "react"]
}$group – Example
This is what $group would look like on this:
db.posts.aggregate([
{ $group: { _id:"$author", titles: { $push:"$title"}} }
])The output for this command would be as follows:
{
"_id" : "Ruth",
"titles" : [
"hello city"
]
},
{
"_id" : "John",
"titles" : [
"my first blog",
"my second blog"
]
}$match – Example
This is what the command would look like for $match:
db.posts.aggregate([
{ $match: { author:"John"} }
])This is what the result would look like for this command:
{
"_id" : ObjectId("5c58e5bf186d4fe7f31c652e"),
"title" : "my first blog",
"author" : "John",
"likes" : 4.0,
"tags" : [
"angular",
"react",
"python"
]
},
{
"_id" : ObjectId("5c58e5bf186d4fe7f31c652f"),
"title" : "my second blog",
"author" : "John",
"likes" : 7.0,
"tags" : [
"javascript",
"ruby",
"vue"
]
}$sum – Example
For this example set, we can execute this command as follows:
db.posts.aggregate([
{ $group: { _id: "$author", total_likes: { $sum: "$likes" } } }
])This is what the output of this command would look like:
{
"_id" : "Ruth",
"total_likes" : 3
},
{
"_id" : "John",
"total_likes" : 11
}How to Boost MongoDB Aggregation Pipeline Performance?
Here are a few simple things to consider to boost your MongoDB Aggregation Pipeline performance:
- The db.aggregate() command can either store the results in a collection or return a cursor. When returning a cursor or storing the results within a collection, each document in the result set is subject to the BSON Document Size Limit (16 MB currently). Therefore, if any single BSON document exceeds the BSON Document Size Limit, the command will throw an error.
- If you have multiple pipeline stages, it is usually better to understand the overhead attached to every stage. For example, if you have both the $match and $sort stage in your pipeline, it is highly recommended that you utilize a $match before $sort to minimize the documents that you wish to sort.
What are the Limitations of MongoDB Aggregation Pipelines?
Despite the various advantages of leveraging MongoDB Aggregation Pipelines for your business use case, it is far from perfect. As far as limitations are concerned, the result has the same size limitations per document (16 megabytes). On top of this, every stage is limited to 100 MB of RAM.
You can work around the size limitations by leveraging the allowDiskUse option, otherwise, MongoDB might throw an error.
Conclusion
- This article delves into the various salient features of MongoDB Aggregation Pipelines and the steps you can follow to set one up for your business use case seamlessly.
- It also gives a brief introduction to MongoDB’s features and benefits before discussing the various operators, best practices, examples, stages, and much more to give you a complete idea about MongoDB Aggregation Pipelines.
- To get a complete picture of your business performance and financial health, you need to consolidate data from MongoDB and all the other applications used across your business.
- Connect Vue.js to MongoDB by setting up a backend with Node.js and Express, allowing your Vue app to interact with a MongoDB database. Get started with step-by-step instructions at Vue.js MongoDB Integration.
- To achieve this you need to assign a portion of your Engineering Bandwidth to Integrate data from all sources, Clean & Transform it, and finally, Load it to a Cloud Data Warehouse or a destination of your choice for further Business Analytics.
- All of these challenges can be comfortably solved by a Cloud-Based ETL tool such as Hevo Data.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. What is MongoDB aggregation pipeline?
The MongoDB aggregation pipeline is a framework for processing data in stages. It lets you perform operations like filtering, grouping, and transforming data efficiently.
2. How to optimize aggregation pipeline in MongoDB?
To optimize the aggregation pipeline, minimize the number of stages, use indexes, and filter data early. Also, leverage $match and $project stages whenever possible.
3. Is MongoDB good for aggregation?
Yes, MongoDB is well-suited for aggregation due to its flexible schema, support for
complex queries, and powerful aggregation framework.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





