With the rise of modern data tools, real-time data processing is no longer a dream. The ability to react and process data has become critical for many systems. Over the past few years, MongoDB has become a popular choice for NoSQL Databases. Catering to real-time processing requirements, MongoDB introduced a powerful feature to track data changes with MongoDB Change Streams.
Apache Kafka, on the other hand, is an open-source distributed event streaming platform for fault-tolerant and scalable data pipelines. Integrating MongoDB change stream kafka allows applications to stream data in real-time.
MongoDB change stream Kafka, can be used to build real-time, scalable data pipelines. This can help data teams separate data sources from consumers and ensure data consistency across systems.
Table of Contents
Understanding MongoDB Change Stream Kafka
Before the introduction of change streams, developers used to monitor Oplog entries to track changes in the specific collection based on timestamps. Oplog or operations log is a collection that keeps a record of all the operations performed on data. This process of reading from Oplog and maintaining checkpoints was complex and not fault-tolerant.
Change streams provide a direct interface for consumers to listen to data changes in the database. They are real-time streams that flow with inserts, updates, deletes, or other operations applied to data.
How Change Streams Work
While Change streams capture any modification at the collection level, they can be created against Collection, Database, and Deployment. When a data operation is applied, MongoDB records change in its Oplog. Change streams check Oplog and deliver these changes as continuous events.

In a nutshell, we can see the operational flow of change streams as a series of four steps.
- Subscription: Data consumer subscribes to change streams on specific collections, databases, or clusters.
- Event Capture: Mongodb records operations like insert, update, or delete in the Oplog.
- Stream Delivery: Change events are sent to data consumers in real time for processing.
- Resume Tokens: Data consumers can resume stream after a specific event by passing resume tokens when opening the cursor. Change stream then uses this token to start streaming data.
Hevo offers a seamless, no-code solution to connect your MongoDB database to a wide range of destinations. With real-time data synchronization, automated schema mapping, and robust data transformation features, Hevo ensures that your MongoDB data is efficiently transferred and ready for analysis without the need for complex coding or manual intervention. Hevo offers you:
- No-Code Integration: Easily connect MongoDB to various data warehouse without writing a single line of code.
- Real-Time Data Sync: Keep your data updated with real-time synchronization, ensuring instant availability for analysis.
Why Integrate MongoDB Change Streams with Kafka?
MongoDB Change streams and Kafka can be used to implement robust real-time data processing pipelines. Here are key reasons why this integration is beneficial.
- Real-Time Data Flow: By integrating MongoDB change streams with Kafka, you can share data in real time in distributed systems. This ensures that all consumer services can react to updates immediately.
- Decoupling of Data Producers and Consumers: You can build decoupled architecture with change streams and Kafka, where the data source is separated from consumers so that they can work independently. This approach provides flexibility, as you can add or remove consumers without affecting the data source.
- Scalable Data Pipelines: Apache Kafka can handle large volumes of data. Its distributed and fault-tolerant architecture ensures that data is reliably delivered. By sending MongoDB changes into Kafka, you can build scalable pipelines that can handle increasing loads without affecting performance.
- Simplified Data Integration: Kafka can integrate with a variety of downstream systems. With Kafka acting as an intermediary, MongoDB data can easily be integrated with other systems like data warehouses, analytical platforms, and microservices.
Setting Up the Environment
Let’s consider a scenario where we have a MongoDB database and we want to track changes to the order information in real-time. We will create a change stream on the order’s collection.
Prerequisites
Before diving into the implementation, ensure the following components are installed and configured:
# Start Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# Start Kafka
bin/kafka-server-start.sh config/server.propertiesConfiguring MongoDB Change Streams
Now, set up MongoDB to start Change Streams. Create a sample Orders collection that we’ll monitor for changes.
mongo
use mydb
db.createCollection('orders')Setting Up Kafka for Integration
Create a topic in Kafka where MongoDB changes will be streamed.
bin/kafka-topics.sh --create --topic orders-changes --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1We can use the Kafka Connector to stream the changes to Kafka. The Kafka Connector is a plugin that allows Kafka to read data from and write data to external systems, such as MongoDB.
To install Kafka Connect place the connector JAR file in the Kafka Connect plugins directory. To configure the Kafka Connector, we’ll need to create a configuration file that specifies the MongoDB server and the Kafka server. Create a configuration file for the MongoDB Source Connector to stream data from MongoDB to Kafka.
<strong>{
"name": "mongo-source-connector",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSourceConnector",
"tasks.max": "1",
"connection.uri": "mongodb://localhost:27017",
"database": "mydb",
"collection": "orders",
"topic.prefix": "orders-change",
"change.stream.full.document": "updateLookup",
"output.format.value": "json",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
“publish.full.document.only”: “true”
}
}
</strong>In the configuration file above, we specify the name of the connector, the connector class, the maximum number of tasks, and the topic we want to publish to.
We then specify the MongoDB server URI, database, and collection we want to monitor for changes. We also set the change.stream.full.document option to “updateLookup” to ensure that we get the full document for updates.
Finally, we set the publish.full.document.only option to “true” to ensure that only the full document is published to Kafka.
Implementing the Integration
Consume the Kafka topic to verify the integration:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic orders-changes --from-beginningThis setup allows you to monitor changes in a MongoDB collection and stream those changes to Kafka in real-time. This integration is useful for building scalable, event-driven architectures.
Limitations
While integration of MongoDB Change Streams with Apache Kafka provides significant benefits, there are limitations associated with this approach.
Latency
When MongoDB changes are sent to Apache Kafka, they are serialized. Similarly, records are deserialized when received in Kafka consumer. This adds processing overhead and contributes to latency. Network issues could also increase delays, affecting real-time data flow.
Complexity of Management
Integration of change streams with Apache Kafka requires configuring and monitoring MongoDB and Kafka. This could add complexity in a distributed environment.
Limited Filtering Options
MongoDB change streams allow limited filtering options. Implementing complex filtering logic may lead to increased development effort and reduced performance.
Resource Intensive
Both MongoDB and Kafka are resource-intensive applications. They may lead to higher resource utilization and cost under heavy loads.
Monitoring and Debugging Challenges
Debugging issues in distributed systems is challenging across different logs and systems. Configuring monitoring tools to track the health of integration may add overhead and complexity to the operational environment.
Setting up CDC with Hevo
Hevo is a no-code data pipeline platform. With Hevo you can easily implement CDC from various databases into your warehouse, lake, and other destinations. Change data capture popularly known as CDC, is a process where data changes are captured and made available to downstream systems.
Key benefits of using Hevo for CDC
- No-Code Integration: Hevo provides a no-code data pipeline platform. It removes the overhead of writing code for each integration. Data teams can easily focus on bringing data value.
- Real-Time Data Ingestion: With Hevo’s ability to capture and sync data in real-time across various systems, you can ensure your data stores and analytics platforms are always up to date
- Automatic Schema Change Handling: Hevo can automatically detect schema changes in the source database and updates in the destination. This makes the data integration process super easy and reliable.
- Scalability: Hevo is designed to handle large volumes of data efficiently. Thus you do not need to worry about your increasing business needs.
- Monitoring and Alerts: Hevo provides user-friendly and easy-to-understand built-in dashboards to monitor your data flow. With its alerting and monitoring features issues can quickly be identified and resolved.
Step 1: Set up MongoDB CDC as a Source
Here’s a guide to setting up CDC with Hevo:
Step 1. 1: Sign up or Login into the Hevo account, visit Hevo Data’s website to sign up.

Step 1. 2: On Hevo’s Dashboard, click on “Create Pipeline”
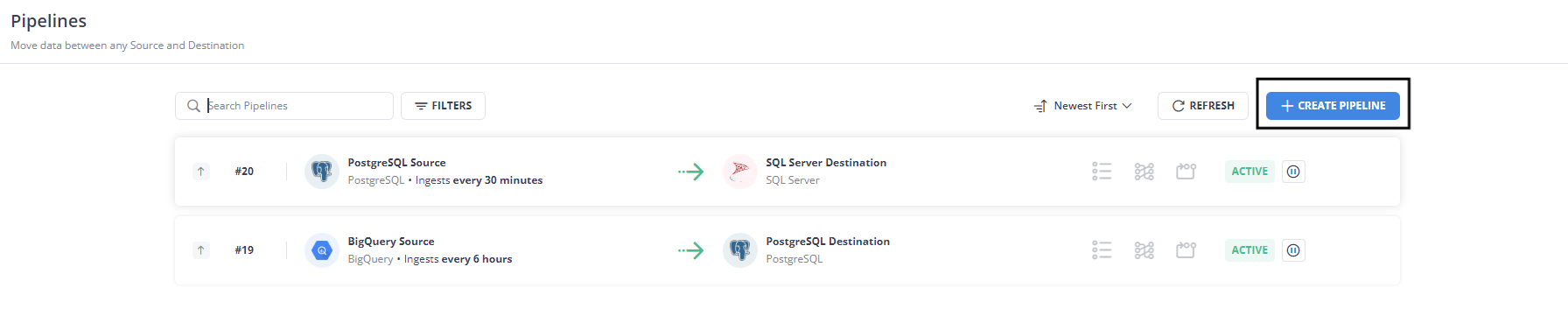
Step 1. 3: Select the type of database you want to use for CDC. Hevo supports multiple databases such as MySQL, PostgreSQL, MongoDB, and more. For this demonstration I will be selecting MongoDB as my source:
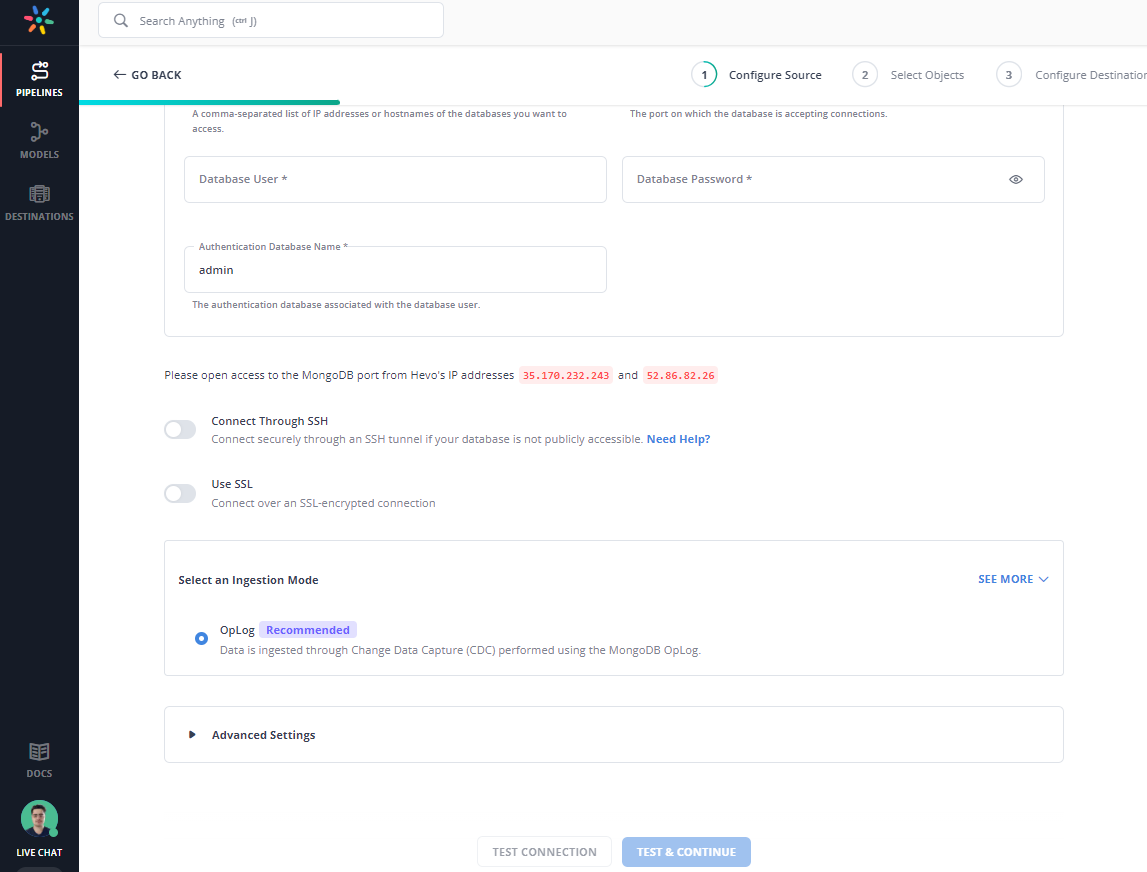
Add the required details like database host, port, username, and password.
Step 1. 4: When setting up the source, you’ll have an option to select an Ingestion Mode.
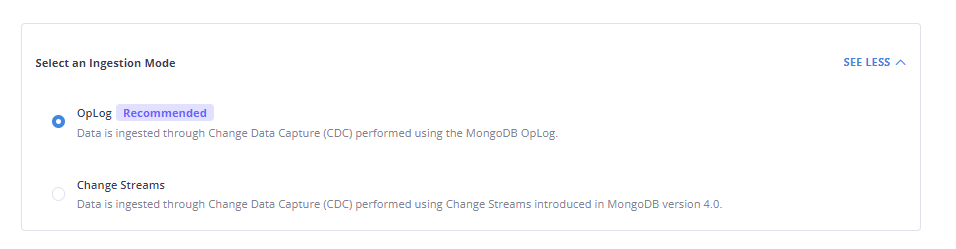
Step 2: Configure your Destination
Step 2. 1: After configuring the source, choose the destination where you want the captured changes to be sent. Hevo supports various destinations such as data warehouses (e.g., Amazon Redshift, Google BigQuery), data lakes (e.g., Amazon S3), or even other databases. I’ll use BigQuery as my destination.

After the source and Destination are set up you can monitor the data flow in real-time with Hevo’s Dashboard. Make adjustments to the source, destination, or transformations as required.
By setting up CDC with Hevo, you can ensure that your data infrastructure is robust, up-to-date, and ready to support real-time analytics.


You can also read more about:
- Heroku Kafka Deployment
- PostgreSQL Kafka Connector
- How to Set Up Spark and Kafka Streaming
- Creating Spring Kafka Consumer Applications
Conclusion
MongoDB’s change streams provide a powerful feature to capture database changes. Its integration with Kafka can ensure that changes are propagated in real time to data consumers. While this integration has numerous benefits, it needs to be carefully planned with robust monitoring, especially in case of large-scale and mission-critical environments.
Hevo provides an even more streamlined approach to implementing CDC, without the need for custom coding. This helps data teams focus on deriving maximum value out of data for business rather than managing complex infrastructure.
FAQ on MongoDB Change Streams with Apache Kafka
1. What are MongoDB Change Streams?
Change Stream is a feature provided by MongoDB to allow users to subscribe to real-time changes in your MongoDB database. Any modification event flows through these streams enabling applications to react immediately to database changes.
2. What is MongoDB Oplog?
MongoDB’s Oplog or operations log is a collection that keeps a record of all the operations performed on data.
3. Can I filter which changes are streamed from MongoDB to Kafka?
Yes, MongoDB Change Streams allow you to filter events based on specific criteria, such as operation type (insert, update, delete) or fields within the documents. Thus you can only send reduced relevant changes to Kafka.
4. What happens if there’s a failure in Kafka or MongoDB?
If Kafka fails, MongoDB Change Streams will continue capturing changes, but these changes won’t be streamed until Kafka is back online. Resume tokens can be used to resume from where it left off, minimizing data loss.
5. Can Hevo implement CDC for MongoDB?
Yes, With Hevo’s support, you can implement CDC for MongoDB without the need to write any code. You just need to provide credentials and collections for which changes have to be captured.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link