



Today, large volumes of data are transmitted as messages between applications, systems, and services. In case an application isn’t ready, or a service failure occurs, messages and transactions may be lost or duplicated. This might cost organizations time, resources, and money to rectify. Here’s when the Message Queue (MQ) comes for rescue. With MQ, messages can be placed in a queue and held there until delivery is guaranteed, and users will never miss a message.
In this blog, you will learn about IBM MQ and Kafka, two of the popularly used Message Queues used in IT systems. Though IBM MQ vs Kafka addresses the same problem of how to handle streaming data, they function in different ways. Further, you will learn about the critical differences between IBM MQ vs Kafka.
Table of Contents
What is MQ?
A Message Queue (MQ) is an asynchronous service-to-service communication protocol used in microservices architectures. In MQ, messages are queued until they are processed and deleted. Each message is processed only once. In addition, MQs can be used to decouple heavyweight processing, buffering, and batch work.
Message Queues provide asynchronous communication and processing between different parts of a system. It also provides a lightweight buffer for temporarily storing messages, as well as endpoints (sending and receiving messages) for connecting to the queue.
Hevo Data helps load data from any data source, such as Databases, SaaS applications, Cloud Storage, SDKs, and Streaming Services, and simplifies the ETL process. It supports 150+ data sources (including Apache Kafka and 60+ free data sources).
Check out why Hevo is the Best:
- Secure: Hevo’s fault-tolerant architecture ensures that data is handled securely, consistently, and with zero data loss.
- Schema Management: Hevo eliminates the tedious task of schema management. It automatically detects the schema of incoming data and maps it to the destination schema.
- Incremental Data Load: Hevo allows the transfer of modified data in real-time, ensuring efficient bandwidth utilization on both ends.
- Live Support: The Hevo team is available 24/5 to extend exceptional support to its customers through chat, E-Mail, and support calls.
MQ Architecture


- Messages: They consist of requests, responses, error messages, or just any information.
- Queue: It is a collection of objects/messages waiting to be processed in a sequential sequence, commencing at the beginning and working down the line.
- Message Queue: A Message Queue is a collection/sequential queue of messages that are transmitted between applications. It contains a list of unprocessed work objects.
- Producer: A producer adds a message to the queue to send to the consumer.
- Consumer: The message is held in the queue until it is retrieved and processed by the consumer.
Protocols Support
There are three open-source Message Queue implementation standards that have emerged:
- AMQP (Advanced Message Queuing Protocol) — a feature-rich message queuing protocol.
- Protocol for Streaming Text-Oriented Messaging (STOMP) — a text-oriented, simple message protocol.
- MQTT (previously MQ Telemetry Transport) — is a lightweight message queuing protocol designed for embedded devices.
The standardization and adoption of these protocols are at various levels: the first two work at the HTTP level, whereas MQTT works at the TCP/IP level.
Key Features of MQ
Some of the main features of Message Queues are listed below.
- Security: Message Queues will authenticate applications attempting to access the queue and will allow users to encrypt messages both over the network and within the queue.
- Ordering: Most Message Queues use best-effort ordering, which assures that messages are delivered in the same order as they were sent.
- Push or Pull: For retrieving messages, most Message Queues offer both push and pull methods. The term “pull” refers to the process of repeatedly searching the queue for new messages. When a message is accessible, a consumer is alerted through “push.” The combined mechanism is also known as Pub/Sub or publish-subscribe messaging.
- Delay Delivery: Many Message Queues allow users to specify a message’s delivery time. A delay queue can be set up if consumers need a common delay for all communications.
What is IBM MQ?

IBM MQ is a message and queuing middleware that makes integrating various applications and business data across many platforms easier and faster. With the help of IBM MQ, applications can publish messages to many subscribers.
IBM MQ facilitates the interchange of information between applications, systems, services, and files by delivering and receiving message data via messaging queues. This makes creating and maintaining business applications a lot easier.
Key Features of IBM MQ
Some of the main features of IBM MQ are listed below.
- From mainframe to mobile, flexible messaging integration provides a single, robust messaging backbone for dynamic heterogeneous environments.
- Extensibility and company growth are supported by IBM’s open standards development tools.
- Message transmission with a variety of security elements and auditable outcomes. High-performance message transmission improves the speed and reliability of data delivery.
- It has multiple modes of operation, including point-to-point, publish/subscribe, file transfer, and enterprise-grade messaging features for moving information efficiently and reliably.
Also, take a look at the most Popular Message Broker Platforms to help choose the the right platform for you.
What is Apache Kafka?

Apache Kafka was originally developed at Linkedin as a stream processing platform before being open-sourced and gaining large external demand. Later, the Kafka project was handled by the Apache Software Foundation. Today, Apache Kafka is widely known as an open-source message broker and a distributed data storage platform written in Scala.
It is a fault-tolerant, high throughput pub-sub messaging system built for real-time input and processing of streaming data. A streaming application consumes data streams, but a data pipeline processes and transmits data from one system to another on a constant basis.
Key Features of Kafka
Some of the main features of Kakfka are listed below.
- Apache Kafka is extremely fast and ensures that there will be zero downtime and no data loss.
- Kafka can readily handle large volumes of data streams and allows users to derive new data streams using previous data streams from the producer.
- Kafka is distributed and fault-tolerant, Kafka is exceptionally reliable. So applications can leverage Kafka in a variety of ways. Furthermore, it provides methods for creating new connections as needed.
- Kafka uses a Distributed Commit Log, ensuring that messages are saved on drives as rapidly as possible. Failures with the databases are handled efficiently by the Kafka cluster.
You can also take a look at the Top Kafka Alternatives to check out features provided by other platforms as well.
Critical Difference Between IBM MQ and Kafka
Now that you have a brief knowledge of IBM MQ and Kafka. Let’s read more about IBM MQ vs Kafka to understand better which one is best for what factor.
| Feature | IBM MQ | Kafka |
| Security | Advanced security features, including granular controls and message simplification. | Basic security features; lacks IBM MQ’s advanced capabilities. |
| Scalability | Can be horizontally scaled, ideal for high reliability but may lag with numerous consumers. | Highly scalable, especially with multiple consumers due to its single log structure. |
| Throughput | Suitable for applications needing high reliability and no message loss. | Designed for high-throughput and big data applications. |
| Communication Protocol | Push-based; messages are sent to a queue where multiple systems can consume them. | Pull-based; receiving systems request messages, with easier event logging. |
| Use Cases | Great for conventional messaging and JMS; suited for critical applications. | Ideal for big data frameworks, streaming, and pub-sub architectures. |
| Pricing | Requires licensing, which can be costly. | Open-source, generally free; subscription costs for managed services. |
- IBM MQ vs Kafka: Security
- IBM MQ vs Kafka: Performance factors
- IBM MQ vs Kafka: Communication protocol
- IBM MQ vs Kafka: Use Cases
- IBM MQ vs Kafka: Pricing
IBM MQ vs Kafka: Security
IBM MQ and Kafka both offer superior security features for organizations to build mission-critical applications. However, IBM MQ offers a range of advanced capabilities, such as enhanced granular security and message simplification capability, which Kafka does not.
IBM MQ vs. Kafka: Performance Factors
Scalability: Both can be horizontally scaled. However, because Kafka uses a single log for all consumers, it’s more scalable, especially when it comes to the number of consumers.
Throughput: Kafka is recommended for applications that demand high throughput or interaction with a big data stack. On the other hand, IBM MQ is best suited for applications that require a high level of reliability and cannot tolerate message loss.
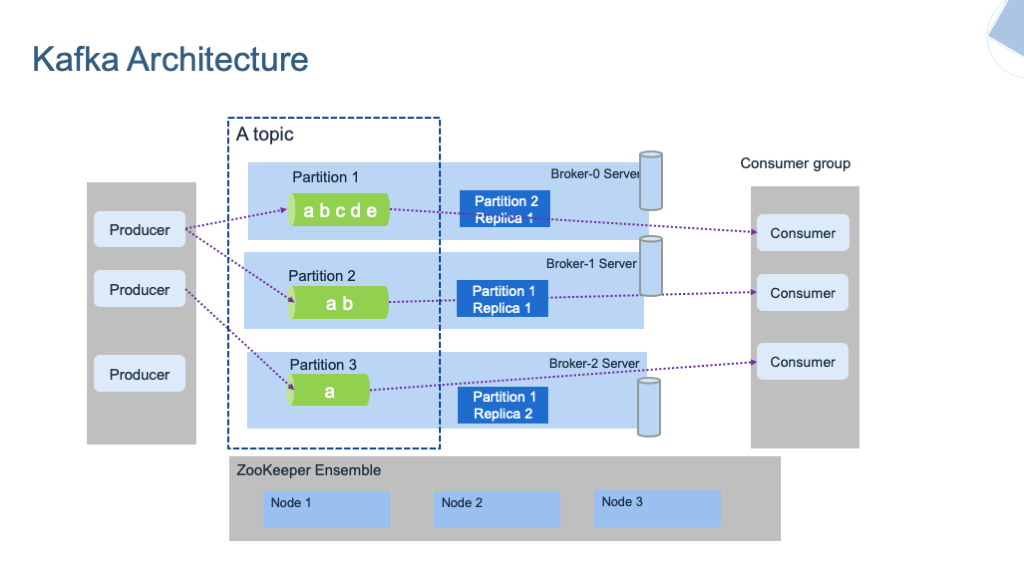
IBM MQ vs. Kafka: Communication Protocol
Apache Kafka utilizes pull-based communication, where the receiving system requests a message from the producing system. Kafka is quicker than most traditional message queuing systems. Because messages in Apache Kafka are not erased once the receiving system has read them, it is easier to log events.
IBM MQ employs a push-based communication mechanism, in which a message-producing system sends its message to the queue, where any receiver may consume it. Multiple systems can draw the same message from the queue at the same time with this sort of communication.
IBM MQ vs Kafka: Use Cases
As a conventional Message Queue, IBM MQ has more features than Kafka. IBM MQ also supports JMS, making it a more convenient alternative to Kafka. Kafka, on the other side, is better suited to large data frameworks such as Lambda. Kafka also has connectors and provides stream processing.
Only the pub-sub architecture differs, with the exception that in the case of IBM MQ, previous message messages are not stored for new consumers.
IBM MQ vs Kafka: Pricing
There are no prices involved with Apache Kafka because it is an open-source solution, but fees vary on the subscription-based hosting services. On the other hand, IBM MQ involves some very expensive licensing costs compared to the open-source products in the market.
You can also read more about:
Conclusion
In this article, you learnt about two widely used messaging queues – IBM MQ vs Kafka – along with their critical differences. In current cloud architectures, most applications are decoupled into smaller, independent blocks, making them easier to build, deploy, and maintain. With the help of a Message Queue, better communication and coordination can be provided to these distributed applications. In short, MQ allows applications to communicate with one another by sending messages.
Companies need to analyze their business data stored in multiple data sources. The data needs to be loaded to the Data Warehouse to get a holistic view of the data. Hevo Data is a No-code Data Pipeline solution that helps to transfer data from 150+ sources to desired Data Warehouse. It fully automates the process of transforming and transferring data to a destination without writing a single line of code.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questios
1. Why is MQ used?
Message Queuing (MQ) is used in computing to facilitate communication between different parts of a system by sending and receiving messages.
2. Can Kafka connect to MQ?
Yes, Apache Kafka can connect to various Message Queue (MQ) systems.
3. Why use Kafka over MQ?
Kafka offers high throughput, scalability, durability, replay capability, a distributed architecture, a wide ecosystem, and is optimized for event streaming, making it suitable for modern data pipelines and real-time processing scenarios.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





