




Easily move your data from Pagerduty To Databricks to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time—check out our 1-minute demo below to see the seamless integration in action!
Building an all-new data connector is challenging, especially when you are already overloaded with managing & maintaining your existing custom data pipelines. To fulfill an ad-hoc PagerDuty to Databricks connection request from your customer experience & analytics team, you’ll have to invest a significant portion of your engineering bandwidth.
We know you are short on time & need a quick way out of it. This can be a piece of cake for you if you just need to download and upload a couple of CSV files. Or you could directly opt for an automated tool that fully handles complex transformations and frequent data integrations for you.
Either way, with this article’s stepwise guide to connect PagerDuty to Databricks effectively, you can set all your worries aside and quickly fuel your data-hungry business engines in 8 nifty minutes.
Method 1: Using Custom Code to Move Data from PagerDuty to Databricks
This method would be time-consuming and somewhat tedious to implement. Users will have to write custom codes to enable two processes: Downloading CSV files and importing them to Databricks.
Method 2: Simplify PagerDuty To Databricks Connection Using Hevo
Hevo Data, an Automated Data Pipeline, provides a hassle-free solution to connect PagerDuty with Databricks within minutes with an easy-to-use, no-code interface. Hevo is fully managed and completely automates the process of not only loading data from PagerDuty but also enriching the data and transforming it into an analysis-ready form without having to write a single line of code.
Get Started with Hevo for FreeTable of Contents
Method 1: Exporting & Importing PagerDuty Reports as CSV Files
PagerDuty offers various reports that provide account-wide views of historical data, allowing you to monitor your business’s operational efficiency. You can go to Analytics > Reports to find different reports based on the pricing plan.
Step 1: Download CSV files
Let’s see how you can easily download these reports as CSV files for the PagerDuty to Databricks integration:
- System Report: It provides account information by escalation policies and services. To download a CSV, go to View Incidents > Download CSV.
- Team Report: This shows the team’s performance and operational load over time. You can select the data range to view All High-Urgency Incidents and click on the Download CSV option.
- User Report: Provides detailed information about individual responders in PagerDuty. Select the data from the table for the specific user to download your CSV file and then click Download CSV to the right.
- Notifications Report: This shows details about the notifications that are sent to your users. For historical data, you can click Download CSV under the Actions column. Else, you can click on the View Online option to the right of the date range and then click on the Download CSV option.
- Incidents Report: Offers a detailed view of an incident’s service, duration, who resolved it, and escalations. Similar to the Notifications Report, you can click on the Download CSV under the Actions column for the historical table. Or, click on View Online to the right of the date range and then click Download CSV.
Step 2: Import CSV Files
- Log in to your Databricks account. On your Databricks homepage, click on the “click to browse” option. A new dialog box will appear on your screen. Navigate to the location on your system where you have saved the CSV file and select it.
- In the Create New Table window in Databricks, click on the Create New Table with UI button. Interestingly, while uploading your CSV files from your system, Databricks first stores them in the DBFS(Databricks File Store). You can observe this in the file path of your CSV file, i.e., in the format “/FileStore/tables/<fileName>.<fileType>”.
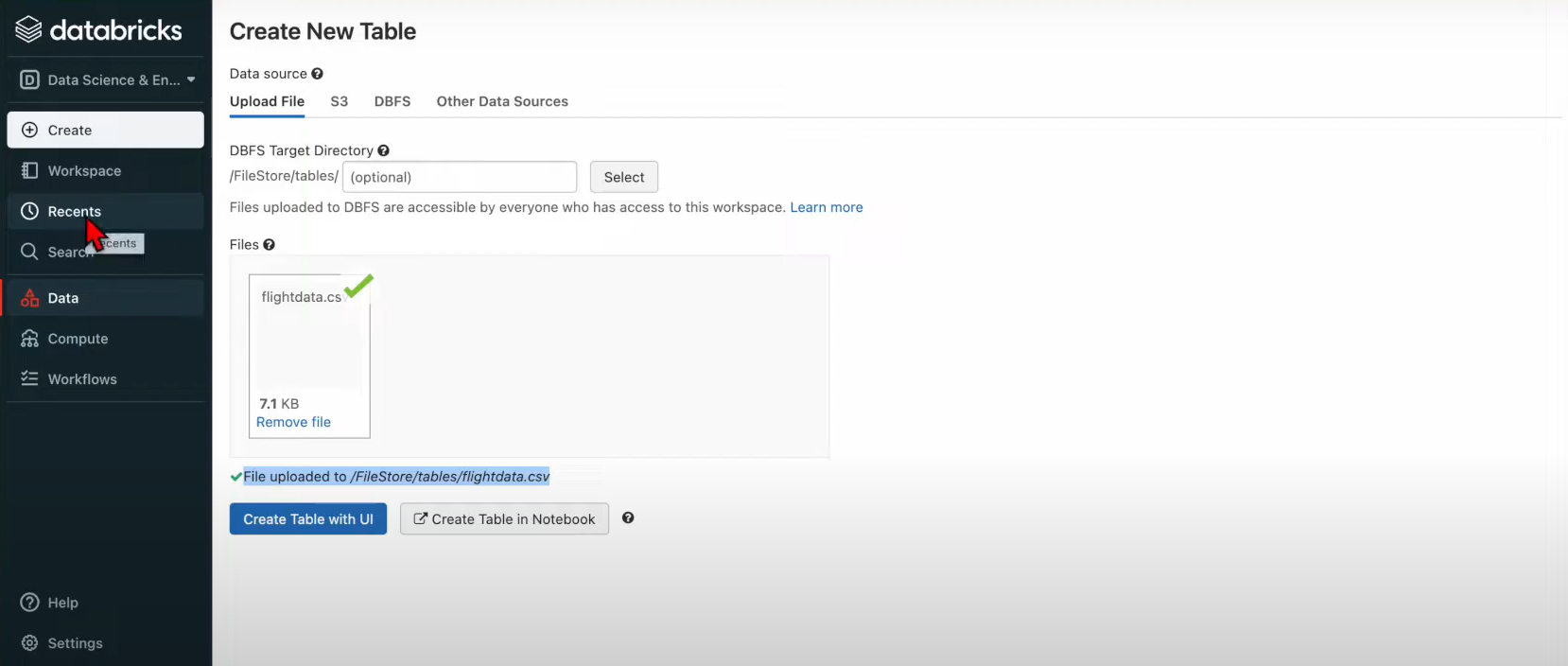
- Select the cluster where you want to create your table and save the data. Click on the Preview Table button once you are done.
- Finally, you can name the table and select the database where you want to create the table. Click on the Infer Schema check box to let Databricks set the data types based on the data values. Click the Create Table button to complete your data replication from PagerDuty to Databricks.
Is there a more fluid and effortless alternative to this resource-intensive & time-consuming solution? Yes, Of course. You can always…
Method 2: Automate the Data Replication process using a No-Code Tool
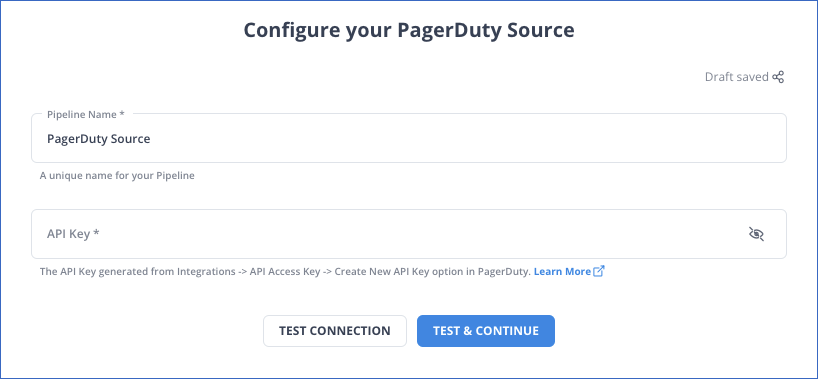
Step 1: Configure PagerDuty as Source
Step 2: Configure Databricks as the Destination

Data Replication
| Default Pipeline Frequency | Minimum Pipeline Frequency | Maximum Pipeline Frequency | Custom Frequency Range (Hrs) |
| 1 Hr | 1 Hr | 24 Hrs | 1-24 |
Hevo Data’s fault-tolerant architecture ensures that the data is handled securely and consistently with zero data loss. It also enriches the data and transforms it into an analysis-ready form without writing a single line of code.
Hevo Data’s reliable data pipeline platform enables you to set up zero-code and zero-maintenance data pipelines that just work. By employing Hevo Data to simplify your PagerDuty to Databricks data integration needs, you can leverage its salient features:
- Reliability at Scale: With Hevo Data, you get a world-class fault-tolerant architecture that scales with zero data loss and low latency.
- Monitoring and Observability: Monitor pipeline health with intuitive dashboards that reveal every state of the pipeline and data flow. Bring real-time visibility into your ELT with Alerts and Activity Logs.
- Stay in Total Control: When automation isn’t enough, Hevo Data offers flexibility – data ingestion modes, ingestion, and load frequency, JSON parsing, destination workbench, custom schema management, and much more – for you to have total control.
- Auto-Schema Management: Correcting improper schema after the data is loaded into your warehouse is challenging. Hevo Data automatically maps the source schema with the destination warehouse so that you don’t face the pain of schema errors.
- 24×7 Customer Support: With Hevo Data, you get more than just a platform, you get a partner for your pipelines. Discover peace with round-the-clock “Live Chat” within the platform. What’s more, you get 24×7 support even during the 14-day full-feature free trial.
- Transparent Pricing: Say goodbye to complex and hidden pricing models. Hevo Data’s Transparent Pricing brings complete visibility to your ELT spending.

What can you achieve by replicating data from PagerDuty to Databricks?
Replicating data from PagerDuty to Databricks can help your data analysts get critical business insights. Here’s a short list of questions that this data integration helps answer:
- What percentage of customers’ queries from a region is through email?
- The customers acquired from which channel have the maximum number of tickets raised?
- What percentage of agents respond to customers’ tickets acquired through the organic channel?
- Customers acquired from which channel have the maximum satisfaction ratings?
- How does customer SCR (Sales Close Ratio) vary by Marketing campaign?
- How does the number of calls to the user affect the activity duration with a Product?
- How does Agent performance vary by Product Issue Severity?
You can also read more about:
- Segment to Databricks
- Setting up Databricks ETL Methods
- Amazon RDS to Databricks
- ActiveCampaign to Databricks
Bringing It All Together
That’s it! Now you know all the ways to replicate data from PagerDuty to Databricks. If the PagerDuty data replication is a rarity, you can always go with the trusty download and upload CSV file approach. However, if your business teams need data from multiple sources every few hours in an analysis-ready form, you might need to burden your engineering team with custom data connections.
This is a time-consuming task that requires continuous monitoring of the data pipelines to ensure no data loss. Sounds challenging, right? Well, no worries. You can also automate your data integration with a No-code ELT tool like Hevo data, which offers 150+ plug-and-play integrations. Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, check out our unbeatable pricing to choose the best plan for your organization.
Frequently Asked Questions
1. What data can be integrated from PagerDuty to Databricks?
Incidents, alerts, schedules, and response metrics from PagerDuty can be integrated and analyzed in Databricks.
2. How often can PagerDuty data be synced to Databricks?
The frequency of syncing is determined by the ETL tool or pipeline, from near real-time sync to batch imports over daily or weekly.
3. Can I transform the PagerDuty data before loading it into Databricks?
Most ETL tools and custom pipelines should allow for any number of transformations-filtering, aggregating, normalizing data, and so on- before that data’s loaded into Databricks.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



