



So, gearing up for PubSub to BigQuery? In today’s world, businesses rely on online workflows, creating a lot of data. Modern apps use cloud systems to manage this data quickly, breaking it into smaller, flexible parts. PubSub messaging helps these parts communicate instantly and share updates.
PubSub sends important information, like customer details and marketing data, to tools like Google BigQuery, where companies can store and analyze it. It handles large amounts of data at once, making app development faster and more independent. This article will explain what PubSub is, how it’s used, and how to connect it to BigQuery for easy data flow.
Table of Contents
What is PubSub?

PubSub stands for Publisher-Subscriber messaging, a method for apps to communicate without directly knowing each other. In this system, publishers send messages to a topic while subscribers listen to that topic to receive those messages. Pub/Sub is great for handling high-volume data streaming and managing data pipelines. It acts as a middleman, allowing tasks to be processed in parallel.
Key Features of PubSub
PubSub is useful for simultaneously gathering information or events from many streams. A few features of PubSub are listed below:
- Filtering: PubSub can filter the incoming messages or events from Publishers based on various attributes to reduce the delivery volumes to Subscribers.
- 3rd Party Integrations: It offers OSS Integrations for Apache Kafka and Knative Eventing. Also, it provides integrations with Spunk and Datadog for logs.
- Replay Events: PubSub allows users to rewind the backlog or snapshot to reprocess messages.
What is Google BigQuery?

Google BigQuery is a cloud data warehouse that is a part of the Google Cloud Platform, which means it can easily integrate with other Google products and services. It allows users to manage their terabytes of data using SQL and helps companies analyze their data faster with SQL queries and generate insights. Google BigQuery Architecture uses the columnar storage structure that enables faster query processing and file compression.
Key Features of Google BigQuery
Google BigQuery allows enterprises to store and analyze data with faster processing. There are many more features for considering Google BigQuery. A few of them are listed below:
- BI Engine: BI Engine is an in-memory analysis service that allows users to analyze large datasets interactively in Google BigQuery’s Data Warehouse itself. It offers sub-second query response time and high concurrency.
- Integrations: Google BigQuery offers easy integrations with other Google products and its partnered apps. Moreover, developers can easily create integration with its API.
- Fault-tolerant Structure: Google BigQuery delivers a fault-tolerant structure to prevent data loss and provide real-time logs for any error in an ETL process.
Hevo offers an automated no-code data pipeline solution that helps to transfer data to Google BigQuery.It supports over 150 integrations and keeps your data up-to-date, so it’s always ready for analysis.
Why Choose Hevo?
- Automated Data Transfer: Supports both batch and real-time streaming.
- No-Code Transformation: Easily transform data for analysis-ready formats.
- Error-Free Data Mapping: Ensures accurate schema replication in BigQuery.
Experience an entirely automated, hassle-free data-loading service for Google BigQuery. Try our 14-day full-access free trial today!
Get Started with Hevo for FreePrerequisites
- Access to the Google Cloud Platform (GCP).
- Basic understanding of Cloud Shell commands.
- A project set up in GCP with permissions to use Pub/Sub, BigQuery, Dataflow, and Google Cloud Storage.
Steps to Connect PubSub to BigQuery
Here, you will learn to manually send messages from PubSub to BigQuery. The steps to connect PubSub to BigQuery are listed below:
- Step 1: Creating Google Storage Bucket
- Step 2: Creating Topic in PubSub
- Step 3: Creating Dataset in Google BigQuery
- Step 4: Connecting PubSub to BigQuery Using Dataflow
Step 1: Creating Google Storage Bucket
- Log in to Google Cloud Platform.
- There are 2 ways to use Google Cloud Platforms, i.e., through Web UI and Cloud Shell. In this tutorial to connect PubSub to BigQuery, we will use Cloud Shell.
- Open the Cloud Shell Editor by clicking on the shell icon located on top of the screen, as shown in the image below.

- It will take some time to start, then click on the “Authorize” button to grant permissions.
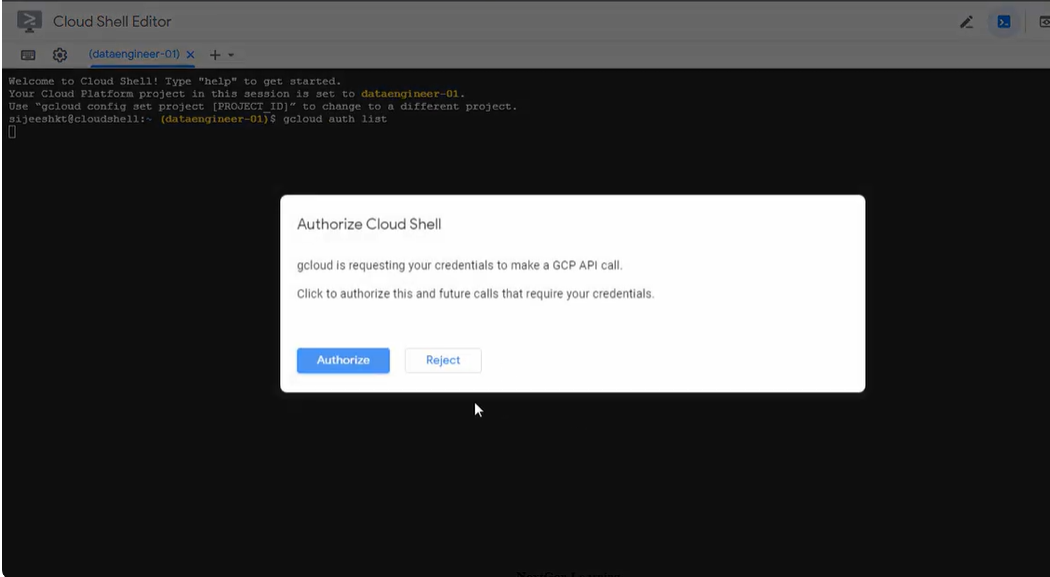
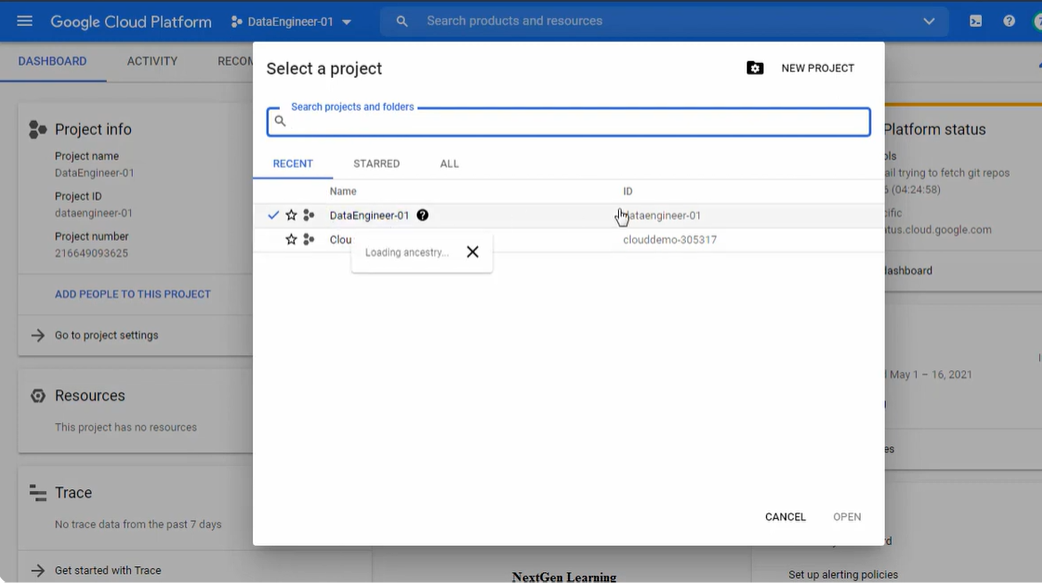
- Now, choose the existing project or create a new project for PubSub to BigQuery dataflow.
- Now on Cloud Shell and create a new Bucket in Google Cloud Storage by typing the command given below.
gsutil mb gs://uniqueName
- Here, provide a unique name to the Bucket in place of “uniqueName” in the above command. A new bucket is created.
In the new tab of the browser, open Google Cloud Platform. Next, open Google Cloud Storage and check if the new Bucket is present or not.
Step 2: Creating Topic in PubSub
- Go to the Cloud Shell again and create a new topic in PubSub by typing the command given below.
gcloud pubsub topics create Topic01- Here, provide a topic name of your choice in place of “Topic01” in the above command.
- It will create a new topic in PubSub.
- In the new tab of the browser, open Google Cloud Platform and there, open PubSub and check if the new topic with a provided name is present or not.
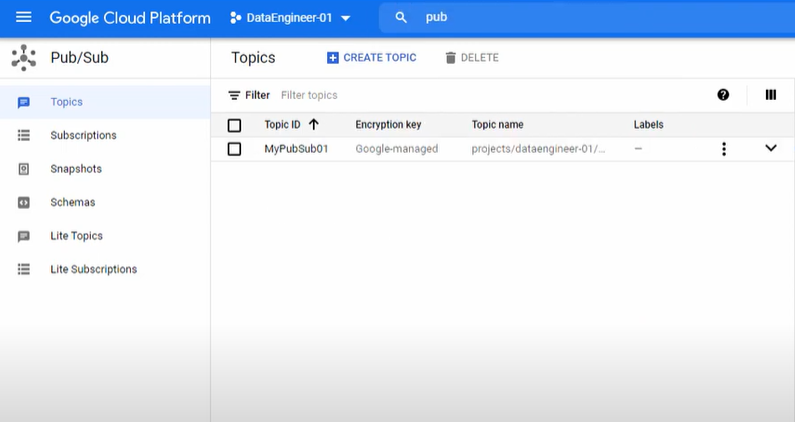
Step 3: Creating Dataset in Google BigQuery
- Now, create a new dataset in Google BigQuery by typing the command in Cloud Shell given below.
bq mk dataset01- Here, replace the name of the dataset of your choice with “dataset01“.
- It will create a new dataset in Google BigQuery, that you can check in Google BigQuery Web UI.
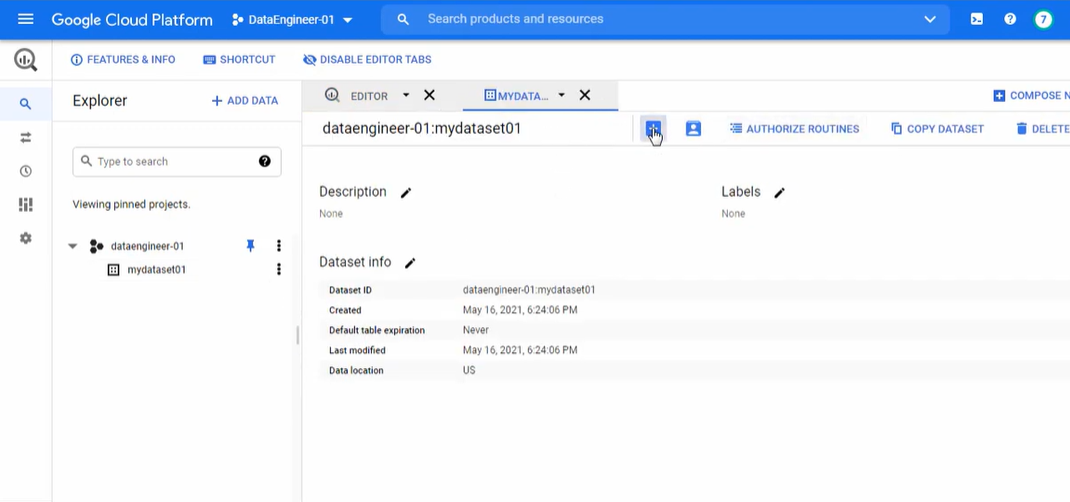
- Now, let’s create a new table in the current dataset.
- Here, let’s take a simple example of a message in JSON (JavaScript Object Notation) format, given below.
{
"name" : "Aditya",
"language" : "ENG"
}You can create any message you want, but it should be in JSON format.
According to the above example, the message has two fields, “name” and “language” as “STRING” type.
- To create a table according to the above message structure, type the command given below.
bq mk dataset01.table01 name:STRING,language:STRING - Here, “dataset01” is the name of your dataset, and “table01” is the name of the table you want to provide. Then, “name” and “language” as fields with their datatypes.
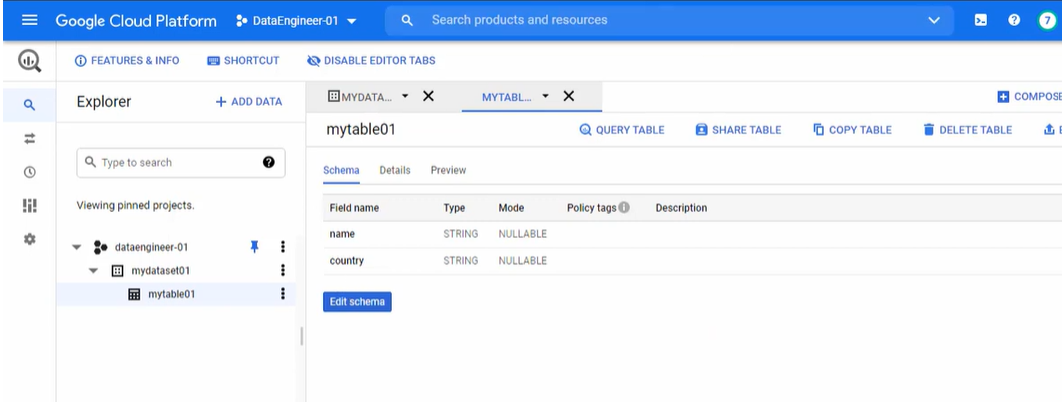
Step 4: Connecting PubSub to BigQuery Using Dataflow
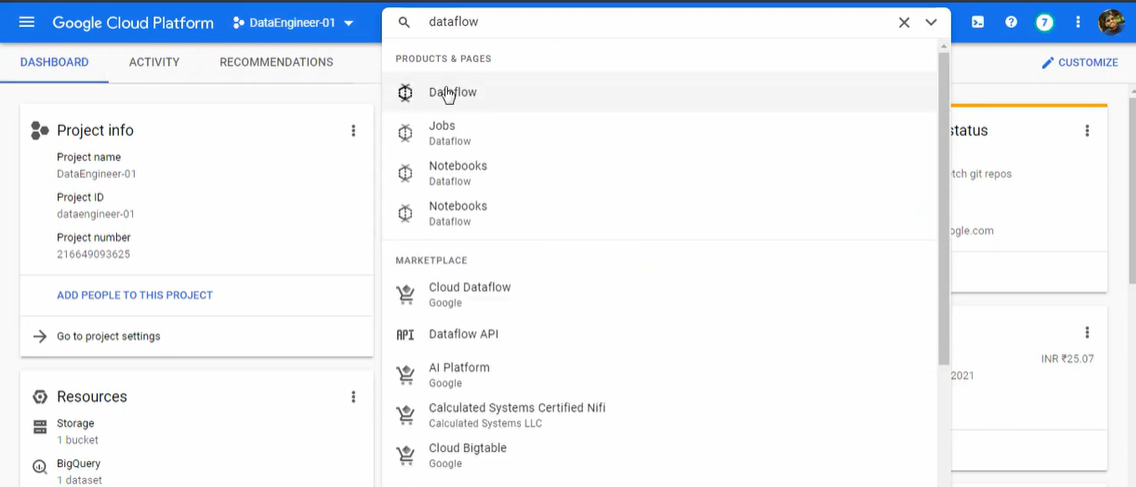
- In the new tab of the browser, open Google Cloud Platform and go to search for “Dataflow” and open it. It will open the Dataflow service by Google.
- Here, click on the “+CREATE JOB FROM TEMPLATE” option to create a new PubSub BigQuery Job, as shown in the image below.
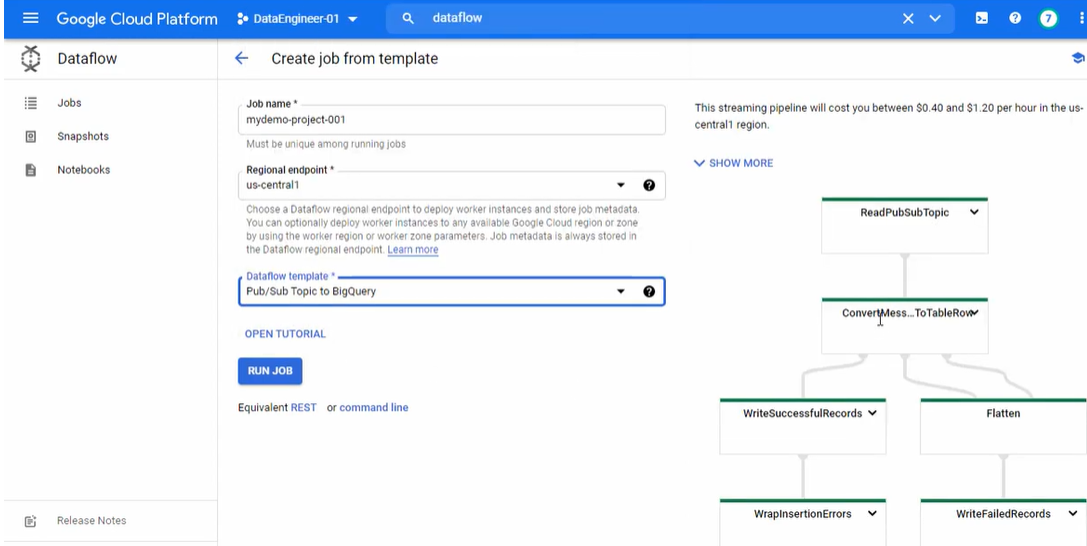
- Now, provide the Job name and choose the “PubSub Topic to BigQuery” option in the Dataflow template drop-down menu, as shown in the image below.

- Copy the “Topic name” from the PubSub topic you just created and the Table ID from the Google BigQuery Table Info.
- Paste both the values in their respective fields in Dataflow.
- Go to Google Cloud Storage, and open the current project Bucket. There navigate to the “CONFIGURATION” tab and copy the value against “gsutil URI“.
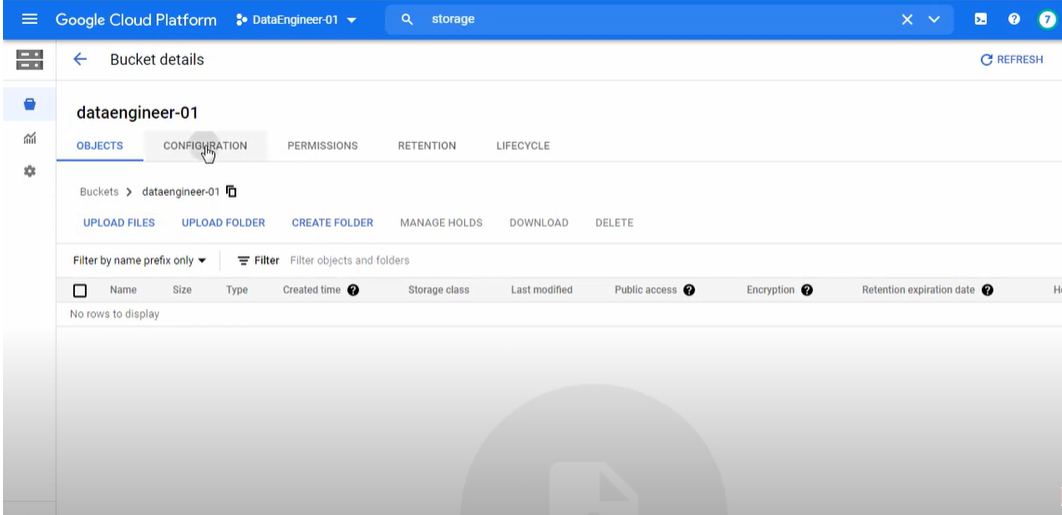
- Paste the value in the “Temporary location” field in Dataflow and click on the “RUN JOB” button.
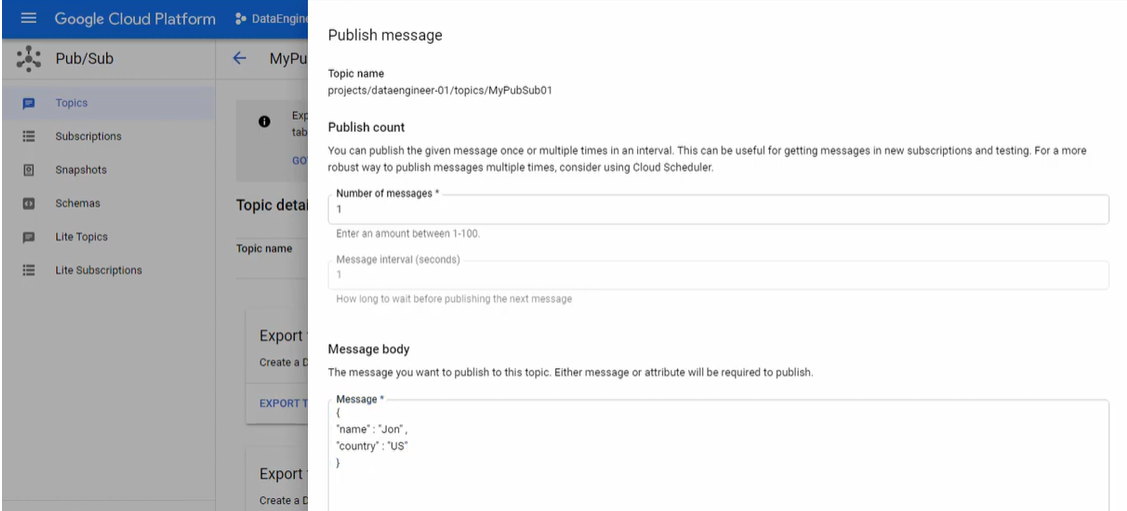
- Now, go to PubSub and click on the “+ PUBLISH MESSAGE” button.
- Copy and paste the above message in JSON or provide your message based on the fields you added in the table.
- Click the “Publish” button. It will publish the message from PubSub to BigQuery using Dataflow and Google Cloud Storage.
Finally, you can check the data in BigQuery.
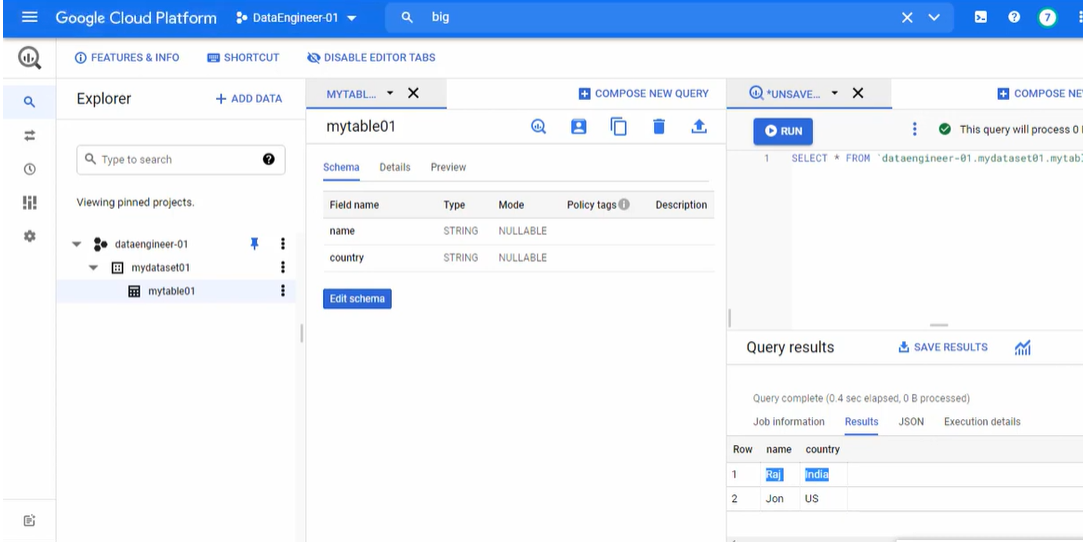
That’s it! You successfully connected PubSub to BigQuery.

Use Cases of PubSub to BigQuery Connection
Some of the common use cases of BigQuery PubSub Connection are listed below.
Stream Analytics: This provides insight in real time by processing and putting live data into order, thereby giving business an updated view of information that frequently changes.
Microservices Integration: It combines several services together, pushes events into systems such as Cloud Run or Kubernetesend. Here, even low latency data can be handled.
Log and Event Monitoring: Ingests logs from a multivariate set of sources into BigQuery for its central tracking and analysis.
Benefits of Connecting PubSub to BigQuery
PubSub powers modern applications with an asynchronous, streamlined data flow. Connecting PubSub to BigQuery allows companies to get all the data, messages, or events in a Data Warehouse. A few benefits of Connecting PubSub to BigQuery are listed below:
- Connecting PubSub to BigQuery allows companies to transfer data to Data Warehouse to run analytics on data and generate insights.
- PubSub ensures reliable delivery of the message at any scale and message replication simple.
- It allows users to integrate PubSub with many other apps and services through Google BigQuery and publish data.
You can also explore how you can connect BigCommerce data with BigQuery to store and analyze different types of data in your BigQuery destination.
Wrapping it up
In this article, you learned about the steps to connect PubSub to BigQuery. You also read how PubSub to BigQuery data flow allows companies to store user data and manage applications’ data streams at any scale. PubSub allows developers to manage data streams in real-time without lag.
Storing data in Google BigQuery can be tricky since setting up ETL pipelines and configuring details manually requires expertise. Plus, data often isn’t in the right format, so transforming it properly needs strong data engineering and administration skills.
FAQs
1. How to load data from PubSub to BigQuery?
First, create a pipeline using Dataflow, then set up PubSub topic to receive messages, and then use a Dataflow job to transfer those messages to table in BigQuery.
2. What is the difference between BigQuery and PubSub?
PubSub is a messaging service for real-time event streaming, while BigQuery is a data warehouse designed for storing and analyzing large datasets.
3. What is the PubSub to BigQuery template?
It’s a pre-built Dataflow template that simplifies the process of streaming data from PubSub directly into BigQuery.
Share your experience of learning about PubSub to BigQuery Seamless Dataflow in the comments section below!

Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





