




Amazon S3 is one of the most prominent storage services of AWS, which enables you to store and retrieve enormous amounts of data to and from the S3 buckets. It offers an extensive set of features and functionalities that allows you to store and manage various data types like texts, images, and videos with fault-tolerant capabilities. One such data management feature of Amazon S3 is S3 batch operations, which empowers you to organize, manage, and process billions of objects at scale with only a few clicks in the Amazon S3 Management Console or a single API request.
In this article, you will learn about Amazon S3 batch operations, how to implement batch operations in S3, use cases, and the pricing range for S3 batch operations.
Table of Contents
What are Batch Operations?
Batch operations are a sequence of computing operations that repeat and can be left to run until they are done. They can be used in processing large numbers of similar tasks, such as batch reads, writes, or updates. Batch operations may save time and compute resources since it is usually faster to execute tasks in a batch rather than individually.
Here are some examples of batch operations:
- Batch processing: This is an automatic process of running software programs in batches. The user submits jobs, but that is not the interaction that is necessary to process the batch.
- Amazon S3 Batch Operations: A managed solution to enable users to perform any storage actions like copy and tagging objects at scale. A user can create jobs by listing objects that need action, action that is to be performed, and parameters of that operation.
- ERP batch: A partial quantity of a product or material, for example, the amount produced during a given production run.
What is Amazon S3?

- Launched by Amazon in 2006, Amazon S3 (Simple Storage Service) is a low-latency and high-throughput object storage service that enables developers to store colossal amounts of data.
- In other words, Amazon S3 is a virtual and limitless object storage space where you can store any type of data files, such as documents, mp3, mp4, applications, images, and more. In order to work with Amazon S3, you can utilize an easy-to-use online web interface for configuring Amazon S3 buckets to store, organize, and manage various data files.
- Amazon S3 is extremely fault-tolerant since it periodically duplicates or replicates data objects across several devices or servers in diverse S3 clusters, thereby assuring high data availability.
- Furthermore, Amazon S3 can also be linked with third-party software, such as data processing frameworks, to safely conduct queries on S3 data without transferring it to a separate analytics platform.
- Apart from these significant features and capabilities, Amazon S3 requires you to pay only for the storage space you actually utilize, with no setup fee or minimum cost.
Loading data from AWS Sources such as AWS S3 and AWS Elasticsearch can be a mammoth task if the right set of tools is not leveraged. Hevo’s No-Code Automated Data Pipeline empowers you with a fully-managed solution for all your data collection, processing, and loading needs. Hevo’s native integration with S3 and Elasticsearch empowers you to transform and load data straight to a Data Warehouse such as Redshift, Snowflake, BigQuery & more!
Let’s see some unbeatable features of Hevo Data:
- Fully Managed: Hevo Data is a fully managed service and is straightforward to set up.
- Schema Management: Hevo Data automatically maps the source schema to perform analysis without worrying about the changing schema.
- Real-Time: Hevo Data works on the batch as well as real-time data transfer so that your data is analysis-ready always.
- Live Support: With 24/5 support, Hevo provides customer-centric solutions to the business use case.
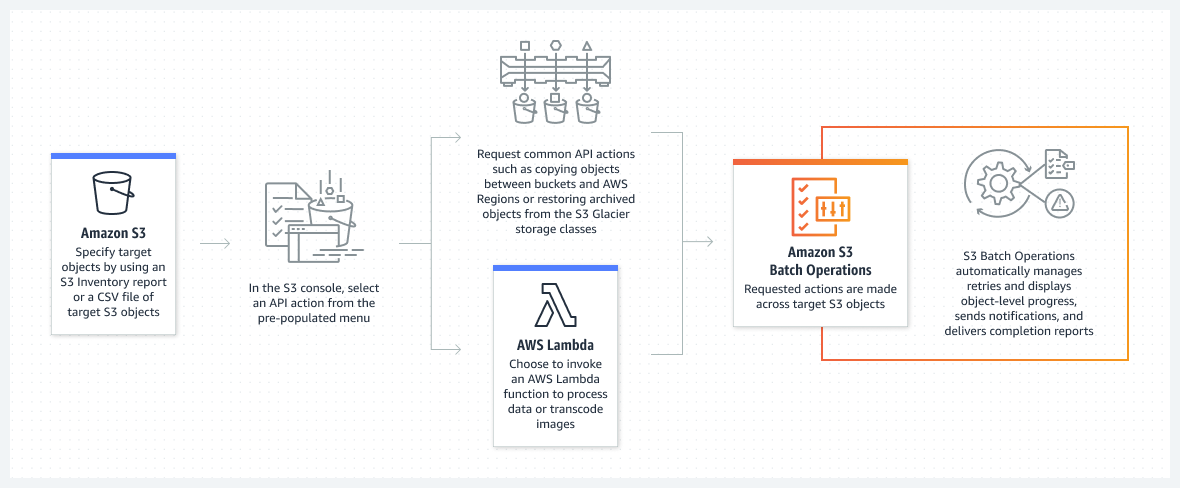
Understanding S3 Batch Operations

- Amazon S3 Batch Operations is a data management functionality in Amazon S3 that allows you to handle billions of items at scale with only a few clicks in the Amazon S3 Management Console or a single API request.
- Instead of spending months developing custom applications to perform these tasks, you can use this feature to make changes to object metadata and properties, as well as perform other storage management tasks.
- Such storage management tasks include copying or replicating objects between buckets, replacing object-tag sets, modifying access controls, and restoring archived objects from S3 Glacier.
- With the Amazon S3 batch operation mechanism, a single job can execute a specific operation on billions of objects carrying exabytes of data. In addition, you can create and run many jobs at the same time, or you can utilize job priorities to define the importance of each job and guarantee the most vital work is completed first.
- Amazon S3 monitors the progress, delivers notifications, and saves a thorough completion report of all S3 batch operations, resulting in a fully controlled, auditable, and serverless experience.
Prerequisites
A fundamental understanding of batch processing.
Use Cases of S3 Batch Operations
- Job Cloning: With the Amazon S3 batch operation process, you can easily clone an existing job, make changes to the parameters, and resubmit it as a new job. Such cloned jobs are used to rerun a failed job or to make any necessary changes or adjustments to the existing jobs.
- Programmatic Job Creation: You might add a Lambda function to the bucket where your inventory reports are automatically generated and then launch a new batch job whenever a report arrives in the specific inventory. Jobs created programmatically do not require confirmation and are instantly ready to execute.
- Job Priorities: In each AWS region, you can have several jobs running at the same time. Jobs with a higher priority rate take precedence, and existing jobs are delayed or paused temporarily. To make adjustments to the job execution, you have to choose an active job and click on Update priority.
- CSV Object Lists: If you need to handle a subset of the objects in an S3 bucket but cannot recognize them using a common prefix, you can build a CSV file and use it to drive your job operation. You may begin with an inventory report and filter the objects by name or by comparing them to a database or other reference. For instance, if you utilize Amazon Comprehend to perform sentiment analysis on all of your saved papers, you can use inventory reports to discover papers that haven’t been analyzed yet and add them to a CSV file.



How to Implement S3 Batch Operations in AWS?
On implementing S3 batch operations, you can easily process hundreds, millions, even or billions of S3 objects. You can also copy or transfer objects to another bucket, assign tags or access control lists (ACLs), start a Glacier restore, or run an AWS Lambda function on each one. This functionality extends S3’s existing support for inventory reports, and it can leverage the reports or CSV files to drive your batch processes.
To implement S3 batch operations, you do not need to write code, set up server fleets, or figure out how to partition and distribute work to the fleet. Instead, you build a job in minutes with a few clicks in UI (User Interface), then leave it free and sit back as S3 handles the work behind the scenes. For implementing UI operations, you can use the S3 Console, the S3 CLI, or the S3 APIs to create, monitor, and manage batch processes.
- Step 1: In this tutorial, we use the Amazon S3 console to create and execute batch jobs for implementing S3 batch operations. Initially, we have to enable inventory operations for one of our S3 buckets and route the reports to the “jbarr-batch-inventory.”
- Step 2: After selecting an inventory item, click Create job from manifest to begin implementing batch processes.

- Step 3: Some of the relevant details have been entered in the “S3 – Create job” dialogue box by default. However, you can also select your preferred Manifest format, such as the S3 inventory report and CSV.
- Step 4: Now, click on the Next button on the left bottom to proceed with further steps.
- Step 5: In the next step, you are prompted to choose the operation that you want to implement on Amazon S3 objects. For this case, select the “Replace all tags” operation and fill in the key-value pair information. After filling in the necessary fields, click on the Next button.

- Step 6: Now, you have to provide a unique name for your job, select its priority rate, and request a completion report that includes all tasks.
- Step 7: Then, you have to select the Amazon S3 bucket destination for the report. You have to also grant permission to access the specified resources in the S3 bucket. After filling in the required fields, click on the Next button.
const formData = new FormData();
formData.append("title", "The Matrix");
formData.append("year", "1999");
const response = new XMLHttpRequest();
response.open("POST","http://localhost:5000/");
response.send(formData);
response.onload = (e) => {
alert(response.response);
}- Step 8: Finally, you have to review the information filled in the previous steps. Check whether the region, manifest format and operations details are entered correctly.
- Step 9: After double-checking the given values, click on the Create Job button.
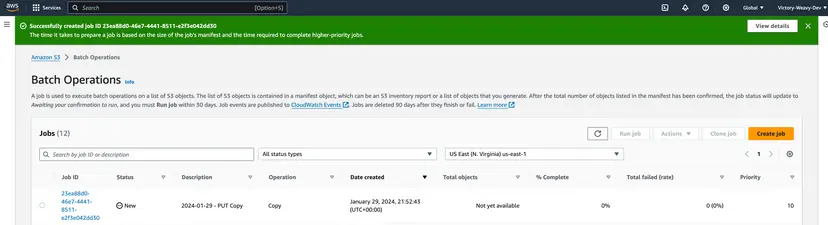
- Step 10: Now, the job enters the Preparing state. Consequently, S3 Batch Operations validates the manifest and performs other verifications. Then, the job enters the “Awaiting your confirmation” state. You have to choose your Job ID, parallel to the “Awaiting your confirmation” status, and click Confirm and run, as shown in the above image.
- Step 11: You can confirm whether the job is executed successfully by checking the Status of the Job ID, as shown in the above image. Since the Status is “Complete” for your Job ID, you can confirm that your job has been executed successfully.
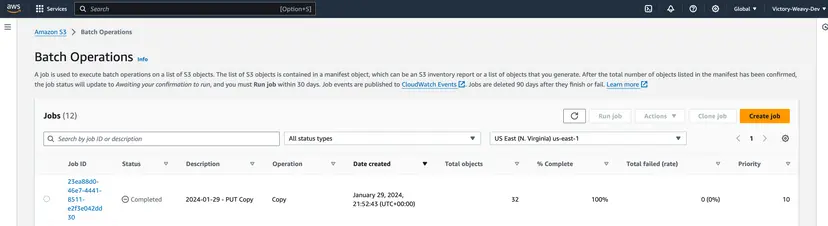
- Step 12: You can check your completion report that specifies the batch operation details for each of your S3 objects, as shown in the above image.
- Step 13: If you execute a job that processes a huge number of S3 objects, you have to frequently refresh the completion report for monitoring the recent progress or status. After the first 1000 objects are processed, S3 Batch Operations evaluates and monitors the total failure rate and will terminate the task if the failure rate exceeds 50%.
Pricing of S3 Batch Operations
- To implement a single batch operation in Amazon S3, you are charged about $0.25 per job. You have to additionally pay for the number of S3 objects executed per job or batch operation. It will cost you around $1.00 per million object operations.
- You will also be charged for any relevant operations carried out on your behalf while implementing S3 Batch Operations, such as data transfer, requests, and other costs.
- You can visit the pricing page of Amazon S3 to learn the most recent prices for batch operations.
For a broader view of AWS’s innovations, check out how Amazon S3 tables are revolutionizing the open table format space.
Conclusion
- In this article, you learned about Amazon S3, S3 batch operations, and how to implement Amazon S3 batch operations.
- This article only focused on implementing one of the batch operations, i.e., “Replace all tags.”
- However, you can also explore and try to implement other batch operation techniques like PUT copy, Invoke AWS Lambda function, Replace access control list (ACL), and Restore.
- However, as a Developer, extracting complex data from a diverse set of data sources like Databases, CRMs, Project management Tools, Streaming Services, and Marketing Platforms to your Database can seem to be quite challenging.
- AWS Batch Job simplifies batch workloads by automatically provisioning resources as needed. Explore details at AWS Batch Job Overview.
- If you are from non-technical background or are new in the game of data warehouse and analytics, Hevo Data can help!
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. What is S3 Batch Operation?
S3 Batch Operations allow you to perform large-scale operations (e.g., copying or deleting objects) on Amazon S3 objects in bulk.
2. What is the limitation of batch operations in S3?
S3 Batch Operations are limited to 100 million objects and cannot be used for real-time processing.
3. How much do S3 batch operations cost?
S3 Batch Operations are priced based on the number of requests and the specific operation. There’s also a charge for the use of S3 storage during the operation.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



