




Unlock the full potential of your Slack data by integrating it seamlessly with BigQuery. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
According to reports, Slack is used by more than 100,000 organizations. That would be a lot of data! What if you could connect Slack to a data warehouse like BigQuery for integrating the data? Wouldn’t that be amazing? Because that will enable you to derive insights from the customer interactions in Slack.
The data integration will also help you to quickly and effectively process large volumes of data and arrive at fruitful conclusions. Awesome! But, Slack doesn’t provide a built-in way to integrate the platform with BigQuery. You will need to adopt some methods for that.
In this blog, I will introduce you to the three methods for Slack to BigQuery integration. The ways include using JSON files, creating a platform using Slack APIs, and using an automated data pipeline. I will also discuss the limitations of each of these and the benefits.
Method 1: Export data to JSON Files and BigQuery
This method involves various steps and hence has higher risks of error. First, you’ll have to export data as JSON Files, and then import those JSON Files into BigQuery.
Method 2: Develop an integration platform using Slack APIs
This method is for more technically skilled users. It involves using various APIs provided by Slack for integration. It’s cumbersome because, after integration, you’ll have to monitor it, too.
Method 3: Using a fully automated data pipeline
Hevo, a completely automated tool, is used for this. For integration, there are two simple steps: first, configure the source (Slack) and then configure the destination (BigQuery).
Get Started with Hevo for FreeTable of Contents
Method 1: Export Data to JSON Files and to BigQuery
Step 1.1: Export Data to a JSON File
Data from your workspace or Enterprise Grid organization can be exported using Slack. You might have a few options for data exports depending on your subscription:
- The following methods can be used by workspace owners and administrators to export data from public channels in their workspace:
- Click on the name of your workspace in the top left corner of your desktop.
- Click on Settings & administration from the menu bar. Then select Workspace settings.
- Select Import/export data in the top right side.
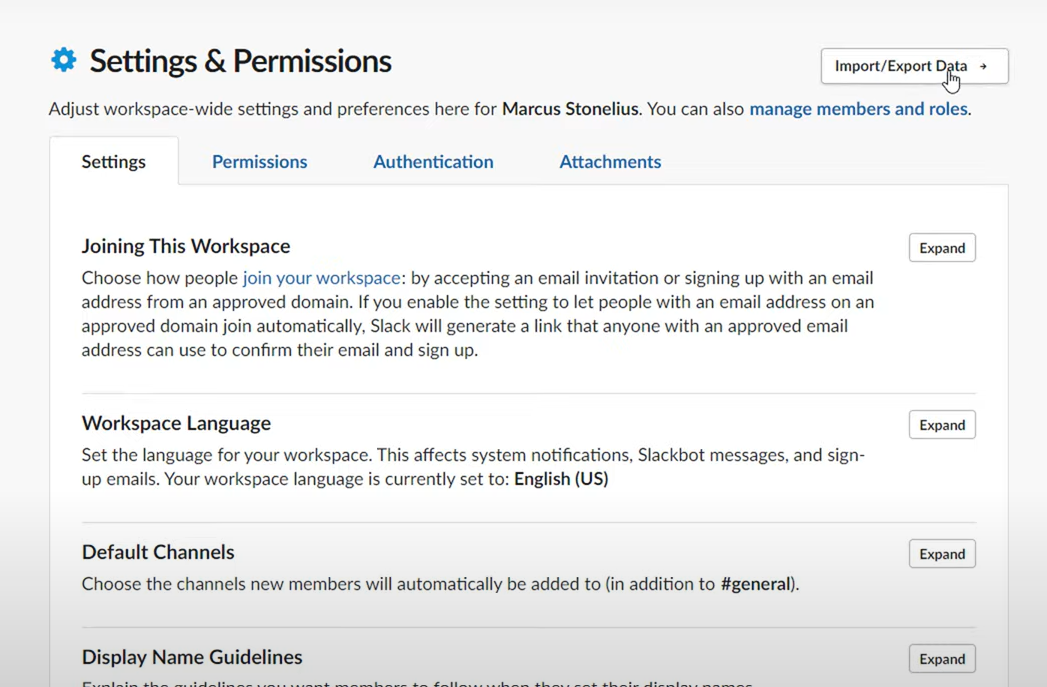
- Choose the Export tab.
- Below Export date range, click on the drop-down menu.
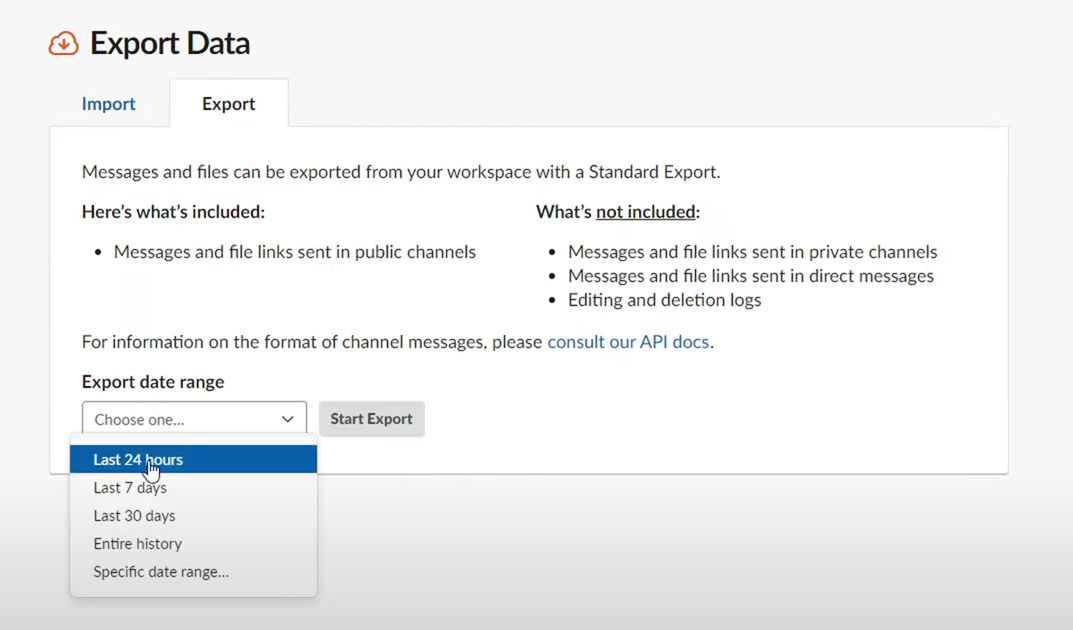
- Select Start export. You will get an email from Slack when the file is ready for export.
- Select Visit your workspace’s export page after opening the email
- Select Ready for download to access the zip file.
The downloaded zip file will have your workspace’s message history in JSON format and file links from all open channels.
Step 1.2: Convert JSON Data to BigQuery
The first step to convert JSON data to BigQuery is injecting the data.
1.2.1: Inject the JSON Data
First, let’s assume that you need to load data from newline delimited JSON files.
Suppose, you have a file named file1.jsonl that has the following data:
1,20
2,"""This is a string"""
3,"{""id"": 10, ""name"": ""Alice""}"You can use the bq load command to load this file.
bq load --source_format=CSV mydataset.table1 file1.csv id:INTEGER,json_data:JSON
bq show mydataset.table1
Last modified Schema Total Rows Total Bytes
----------------- -------------------- ------------ -------------
22 Dec 22:10:32 |- id: integer 3 63
|- json_data: jsonNext, you need to use the storage write API.
1.2.1.(i) Use the Storage Write API
You can use the Storage Write API to import JSON data. The example given below uses the Storage Write API Python client.
Create a protocol buffer to store the streamed data that has been serialized. A string is used to encode the JSON data. The JSON col field in the sample below contains JSON information.
message SampleData {
optional string string_col = 1;
optional int64 int64_col = 2;
optional string json_col = 3;
}Next, you need to format the JSON data for each row as a string value:
row.json_col = '{"a": 10, "b": "bar"}'
row.json_col = '"This is a string"' # The double-quoted string is the JSON value.
row.json_col = '10'As per the code sample, add the rows to the write stream. The client library manages protocol buffer serialization.
Once this is done, the next phase is using the legacy streaming API.
1.2.1.(ii) Use the Legacy Streaming API
The example given below feeds JSON data to BigQuery using the legacy streaming API after loading it from a local file.
from google.cloud import bigquery
import json
# TODO(developer): Replace these variables before running the sample.
project_id = 'MY_PROJECT_ID'
table_id = 'MY_TABLE_ID'
client = bigquery.Client(project=project_id)
table_obj = client.get_table(table_id)
# The column json_data is represented as a string.
rows_to_insert = [
{"id": 1, "json_data": json.dumps(20)},
{"id": 2, "json_data": json.dumps("This is a string")},
{"id": 3, "json_data": json.dumps({"id": 10, "name": "Alice"})}
]
# Throw errors if encountered.
# https://cloud.google.com/python/docs/reference/bigquery/latest/google.cloud.bigquery.client.Client#google_cloud_bigquery_client_Client_insert_rows
errors = client.insert_rows(table=table_obj, rows=rows_to_insert)
if errors == []:
print("New rows have been added.")
else:
print("Encountered errors while inserting rows: {}".format(errors))So, injecting JSON data is done. Next, let’s understand how to query JSON data.

1.2.2: Query JSON Data
In this section, I will explain how to use Google Standard SQL to extract values from the JSON. Remember that JSON is case-sensitive and supports UTF-8 in both fields and values.
The examples mentioned use the following table:
CREATE OR REPLACE TABLE mydataset.table1(id INT64, cart JSON);
INSERT INTO mydataset.table1 VALUES
(1, JSON """{
"name": "Alice",
"items": [
{"product": "book", "price": 10},
{"product": "food", "price": 5}
]
}"""),
(2, JSON """{
"name": "Bob",
"items": [
{"product": "pen", "price": 20}
]
}""");Querying is also done. The next step is extracting values as JSON.
1.2.3: Extract Values as JSON
Using the field access operator in BigQuery, you can access the fields in a JSON expression given a JSON type.
You can use the JSON subscript operator to access an element of an array and refer to the members of a JSON object by name. Any string or integer expression, including non-constant expressions, may be used for subscript operations as the expression included in the brackets.
Both the field access and subscript operators return JSON types, allowing you to combine their use in expressions or send the outcome to other JSON-type-accepting functions.
The JSON QUERY function benefits from these operators’ syntactic sugar. For instance, JSON QUERY(cart, “$.name”) is similar to the phrase cart.name.
These operations return SQL NULL if the JSON object or the JSON array does not include an element with the provided name or position, respectively.
The JSON data type does not define equality or comparison operators. Therefore, JSON values cannot be used directly in clauses like GROUP BY or ORDER BY. Instead, extract field values as SQL strings using the JSON VALUE method.
1.2.4: Extract Values as Strings
A scalar value is extracted and returned as a SQL string via the JSON VALUE function. If cart.name does not point to a scalar value in the JSON, SQL NULL is returned.
SELECT JSON_VALUE(cart.name) AS name
FROM mydataset.table1;+——-+
| name |
+——-+
| Alice |
+——-+
The WHERE clause and the GROUP BY clause are examples of situations where the JSON VALUE function can be used. You can also use the STRING function, which converts a JSON string into a SQL STRING.
You might need to extract JSON values and return them as another SQL data type in addition to STRING. There are the following value extraction options:
- STRING
- BOOL
- INT64
- FLOAT64
You can use the JSON TYPE function to determine the type of JSON value. Alright. Now, what about extracting arrays from JSON?
1.2.5: Extract Arrays from JSON
JSON arrays, which are not precisely comparable to an ARRAY<JSON> type in BigQuery, are possible. The following functions can be used to retrieve a BigQuery ARRAY from JSON:
- JSON_QUERY_ARRAY: This function extracts an array and returns it as an ARRAY<JSON> of JSON.
- JSON_VALUE_ARRAY: This function extracts an array of scalar values and returns it as an ARRAY<STRING> of scalar values.
You have seen how to use the JSON method for Slack to BigQuery data replication. It’s time to take a look at the limitations of this method.
Limitations of Using JSON Method
- When ingesting JSON data into a table using a batch load task, the source data must be in CSV, Avro, or JSON format. The use of other batch load formats is not permitted.
- The nesting restriction for the JSON data type is 500.
- You can’t use Legacy SQL to query a table containing JSON types.
- On JSON columns, row-level access policies cannot be used.


That’s it. Let’s move on to the next method to integrate data from Slack to BigQuery.
Method 2: Develop an Integration Platform Using Slack APIs
This method is for the ones who are up for a challenge. Slack provides a combination of APIs that may allow a technical resource to develop an integration with BigQuery. You can refer to the API docs provided by Slack. Their ‘Getting Started’ guides are quite thorough and should point you in the right direction.
Basic overview of Slack APIs
- The Web API is a collection of HTTP RPC-style methods, all with URLs in the form https://slack.com/api/METHOD_FAMILY.method.
- While it’s not a REST API, those familiar with REST should be at home with its foundations in HTTP.
- Use HTTPS, SSL, and TLS v1.2 or above when calling all methods. Learn more about SSL and TLS requirements.
- Each method has a series of arguments informing the execution of your intentions.
- Pass arguments as:
- GET querystring parameters,
- POST parameters presented as application/x-www-form-urlencoded, or
- a mix of both GET and POST parameters
- Most write methods allow arguments with application/json attributes.
- Some methods, such as chat.postMessage and dialog.open, feature arguments that accept an associative JSON array. However, these methods can be difficult to properly construct when using a application/x-www-form-urlencoded Content-type, so we strongly recommend using JSON-encoded bodies instead.
POST bodies
When sending a HTTP POST, you may present your arguments as either standard POST parameters, or you may use JSON instead.
URL-encoded bodies
When sending URL-encoded data, set your HTTP Content-type header to application/x-www-form-urlencoded and present your key/value pairs according to RFC-3986.
For example, a POST request to the conversations.create method might look something like this:
POST /api/conversations.create
Content-type: application/x-www-form-urlencoded
token=xoxp-xxxxxxxxx-xxxx&name=something-urgentYou can also go through their guides that take you through the basic setup for a Slack app. It’s a lot of investment in terms of time and effort from you. And, you would need to devote your focus to constant monitoring and functioning of the platform once it’s built. Do you think it’s worth it?
Method 3: Using a Fully Automated Data Pipeline
Step 3.1: Configure your Slack source

Step 3.2: Configuring BigQuery as the destination

That’s it about the three methods to replicate data from Slack to BigQuery. Next, let’s look into the benefits of data replication from Slack to BigQuery.
What makes Hevo Amazing?
- Fully Managed: You don’t need to dedicate time to building your pipelines. With Hevo’s dashboard, you can monitor all the processes in your pipeline, thus giving you complete control over it.
- Data Transformation: Hevo provides a simple interface to cleanse, modify, and transform your data through drag-and-drop features and Python scripts. It can accommodate multiple use cases with its pre-load and post-load transformation capabilities.
- Schema Management: With Hevo’s auto schema mapping feature, all your mappings will be automatically detected and managed to the destination schema.
- Scalable Infrastructure: With the increase in the number of sources and volume of data, Hevo can automatically scale horizontally, handling millions of records per minute with minimal latency.
- Live Support: The support team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
What Can you Achieve by Replicating Data from Slack to BigQuery?
Here are a few benefits of replicating data from Slack to BigQuery:
- You can develop a single customer view using data from your Slack to evaluate the effectiveness of your teams and initiatives.
- Obtain more thorough consumer insights. To understand the customer journey and provide insights that may be applied at different points in the sales funnel.
- You can improve client satisfaction. Examine client interactions on the channels. Using this information along with consumer touchpoints from other channels, determine the factors that will increase customer satisfaction.
I hope you got an idea about the benefits of replicating data from Slack to BigQuery. Let’s wrap it up.
Wrapping Up
Replicating data from Slack to BigQuery would enable businesses to arrive at decisions based on interactions on Slack. There are mainly three ways to achieve this. The first method is using JSON files. You can export data from Slack to JSON using the instructions mentioned in the article.
After that, inject your JSON data, and query the data. The second method is to develop an integration platform using Slack APIs. The final method is to use a fully automated data pipeline like Hevo. You can take a look at the merits of each method for Slack to BigQuery migration and decide which one is suitable for you.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
FAQs
Q1) How do I connect Slack to BigQuery?
To connect Slack to BigQuery, use Google Cloud’s “Slack Connector for BigQuery” app. Install the app in Slack, then configure it with your Google Cloud project and BigQuery dataset. This allows querying and viewing BigQuery results directly within Slack.
Q2) How to integrate Slack with GCP?
To integrate Slack with Google Cloud Platform (GCP), use Google Cloud’s Slack integrations like the “Google Cloud Slack app.” Install the app in Slack and authenticate with your GCP account to receive notifications, monitor resources, and manage projects directly from Slack.
Q3) How to push data into BigQuery?
To push data into BigQuery, you can use the BigQuery API, client libraries, or tools like the BigQuery Data Transfer Service. Data can also be uploaded via the BigQuery web UI, using CSV, JSON, or Parquet files, or by streaming real-time data using the BigQuery streaming API.
Q4) Which apps integrate with Slack?
Slack integrates with numerous apps, including Google Workspace, Microsoft 365, Zoom, Trello, Jira, Salesforce, GitHub, Dropbox, and Asana. It also supports integrations with automation tools like Zapier and IFTTT, as well as custom-built apps via Slack’s API.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



