

While you can use Snowpipe for straightforward and low-complexity data ingestion into Snowflake, Snowpipe alternatives, like Kafka, Spark, and COPY, provide enhanced capabilities for real-time data processing, scalability, flexibility in data handling, and broader ecosystem integration.
If your requirements are beyond basic data loading, you may find Kafka or Spark more suitable for building robust and scalable data pipelines tailored to your needs.
In this blog post, we will explore the different snowpipe alternatives for batch and continuous loading and highlight the essential trade-offs, such as maintenance, cost, and the technical expertise required for each.
Let us begin by understanding batch and real-time data loading.
Table of Contents
What is Batch Loading?
Batch Data Loading is when the system collects data generated over a period of time, arranges it in batches, and loads it into the destination at regular intervals, not continuously.
It is typically used when dealing with large datasets.
What is Real-time Loading?
Real-time loading, or real-time data ingestion, involves continuously transferring and processing data as it becomes available, which helps in instant decision-making. Real-time data loading is used when you can quickly react to the customer’s changing demands and stay up to date.
Hevo Data, a No-code Data Pipeline, helps load data from any data source such as databases, SaaS applications, cloud storage, SDK, and streaming services and simplifies the ETL process. It supports 150+ data sources and loads the data onto the desired Data Warehouse like Apache Kafka, enriches the data, and transforms it into an analysis-ready form without writing a single line of code.
Check out why Hevo is the Best:
- Secure: Hevo has a fault-tolerant architecture that ensures that the data is handled in a secure, consistent manner with zero data loss.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Explore Hevo’s features and discover why it is rated 4.3 on G2 and 4.7 on Software Advice for its seamless data integration. Try out the 14-day free trial today to experience hassle-free data integration.
Get Started with Hevo for FreeReal-Time Data Loading with Kafka

Apache Kafka is an open-source, distributed event-streaming platform that handles real-time data. It enables real-time data ingestion and processing, handling continuous data streams from various sources, which Snowpipe does not support. It can be used as one of the Snowpipe alternatives because, unlike the latter, Kafka is not limited by its architecture.
Now, we will look into the components of Apache Kafka.
Kafka is based on four main APIs that are:
- Producer API: Publishers that send messages with data on topics.
- Consumer API: Consumers who subscribe to the messages sent by the Producers and update accordingly.
- Broker API: These are the Kafka servers that manage the communication.
- Topic: Categories in which messages are published.
Steps to Load Data
Let us dive into the step-by-step procedure of loading data from your CSV file to Apache Kafka.
Step 1. Create a Kafka Topic
To load data into Apache Kafka, you need to first create a Kafka Topic, which will act as a medium for the data loading process. To create a Kafka Topic, use the command given below:
kafkahost$ $KAFKA_INSTALL_DIR/bin/kafka-topics.sh --create \
--zookeeper localhost:2181 --replication-factor 1 --partitions 1 \
--topic topic_for_gpkafka
Step 2. Stream the contents of the CSV file to a Kafka producer
Now, to stream the contents of your CSV file to the Kafka Producer API so that it can send messages with data, use the command given below:
kafkahost$ $KAFKA_INSTALL_DIR/bin/kafka-console-producer.sh \
--broker-list localhost:9092 \
--topic topic_for_gpkafka < sample_data.csv
Step 3. View the contents of your file
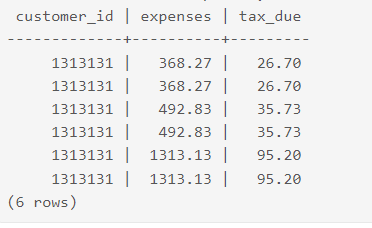
You can view the contents of your CSV file using the command given below:
gpcoord$ psql -d testdb
testdb=# SELECT * FROM data_from_kafka WHERE customer_id='1313131'
ORDER BY expenses;
Use Cases of Kafka as Snowpipe Alternatives
- Log Aggregation: It gathers and consolidates log data from distributed systems to facilitate centralized monitoring and analysis.
- Ecosystem Integration: Kafka integrates well with other Apache projects, third-party tools, and frameworks.
- Flexible: Kafka has a decoupled architecture and supports different programming languages and frameworks, making it versatile.
A Snowflake-native app to monitor Fivetran costs.

Cost Considerations
Apache Kafka’s cost considerations revolve around several key factors:
- Infrastructure costs
- Compute resources: As Kafka is a distributed platform, multiple nodes are required to store the data. The number of nodes and configurations affects the cost.
- Storage: The cost depends on the amount of data stored and the type of storage used, e.g., SSDs for higher performance and HDDs for cost efficiency
- Operational costs
- Monitoring and logging: Implementing tools and solutions to ensure that Kafka clusters are working well can drive up operational costs.
- Administration: Managing Kafka clusters requires a lot of administration.
Required Skills
To use Apache Kafka effectively, there are a few technologies you need to be aware of:
- Using this data loading option requires the Kafka ecosystem, that is, the Kafka APIs.
- Configuring the APIs also requires some technical knowledge, which can be a barrier for many companies.
When should you prefer Kafka over Snowpipe?
This section illustrates what are the scenarios in which Kafka should be used as one of the Snowpipe Alternatives.
- Real-time Data Processing: Kafka handles continuous data streams with low latency, making it best suited for real-time applications. In contrast, Snowpipe’s near-real-time ingestion may not meet the immediate processing needs of high-frequency data streams.
- Scalability and Flexibility: Kafka supports complex data workflows and integration with various systems and frameworks like Spark or Flink. In contrast, Snowpipe may lack the scalability required to handle large volumes of diverse data sources and processing demands.
Data Loading with Apache Spark

Apache Spark is an open-source distributed platform that provides an interface for programming clusters with data parallelism and fault tolerance. It is designed to analyze large sets of data quickly and efficiently. While Snowpipe excels in near-real-time ingestion into Snowflake, it cannot perform intricate data transformations and handle continuous data streams effectively, which can be done using Spark as one of Snowpipe alternatives.
Steps to Load Data using Apache Spark
In this section, we will learn how to load data from CSV to Spark DataFrame.
Step 1. Define Variables and Load CSV File
In this step, we will declare/define the variables to be used further and load the CSV file. The command for doing the same is provided below in Scala:
val catalog = "<catalog_name>"
val schema = "<schema_name>"
val volume = "<volume_name>"
val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
val fileName = "rows.csv"
val tableName = "<table_name>"
val pathVolume = s"/Volumes/$catalog/$schema/$volume"
val pathTable = s"$catalog.$schema"
print(pathVolume) // Show the complete path
print(pathTable) // Show the complete path
Step 2. Create a DataFrame
Like Topic used in Apache Kafka DataFrame is used as a medium in Apache Spark. To create a DataFrame, load the contents of the CSV file into it. The command is given below:
val data = Seq((2021, "test," "Albany", "M", 42))
val columns = Seq("Year", "First_Name", "County", "Sex", "Count")
val df1 = data.toDF(columns: _*)Here, df1 is the name I have given to the DataFrame to be created. You can name it as you choose.
Step 3. Load Data into the DataFrame from CSV
You can load the load directly from the CSV file into the DataFrame you created in Spark using the command provided below.
val dfCsv = spark.read
.option("header", "true")
.option("inferSchema", "true")
.option("delimiter", ",")
.csv(s"$pathVolume/$fileName")
display(dfCsv)
Step 4. Display the data loaded
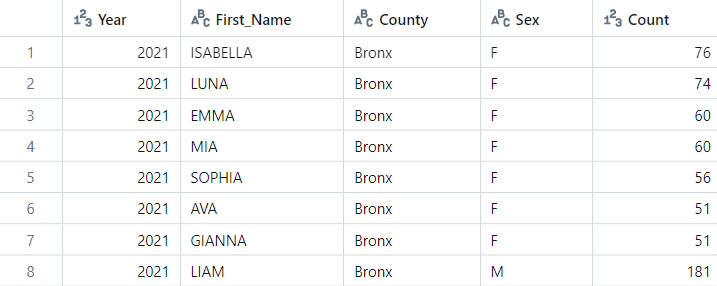
You can now display or filter the loaded data as per your needs using the command given below:
display(df.filter(df["Count"] > 50))
Use Cases of Apache Spark as Snowpipe Alternatives
Before using Spark, you must know some of its significant use cases.
- ETL (Extract, Transform, Load) Operations include loading data from various sources, transforming it, and finally loading it into the destination systems.
- Real-Time Processing: This includes ingesting and processing data in real-time streams for immediate analysis and informed decision-making.
- Machine Learning includes preparing and loading data for training machine learning models using Spark’s MLlib library.
Cost Considerations
The cost considerations revolve around several key factors, such as:
- Compute Resources
- Instance types: The decision whether to use compute instances such as virtual machines or containers affects costs. Instances with higher CPU and memory configurations generally cost more.
- Scaling: Spark can be scaled horizontally by adding more nodes. Cloud providers charge for the number of instances used, so optimizing instance types and cluster sizes is critical to controlling costs.
- Processing Patterns
- Batch vs. streaming: Continuous data processing jobs can be more costly due to ongoing calculations and resource utilization. Batch processing jobs, which are executed at fixed time intervals, can be more cost-effective.
Required Skills
To use Apache Spark effectively, there are a few technologies you need to be aware of:
- Proficient in programming languages such as Scala, Java, and Python.
- Familiarity with Spark’s core APIs for data manipulation, streaming, machine learning (MLlib), and graph processing (GraphX).
When should you prefer Spark over Snowpipe
- Complex Data Transformations: Unlike Snowpipe, which facilitates data ingestion into Snowflake, Spark’s distributed computing framework performs extensive data preprocessing and manipulation before loading data into a warehouse.
- Machine Learning: Snowpipe mainly focuses on data loading rather than advanced analytics and machine learning, so it may not offer the same level of integrated support as Spark for these tasks.
Bulk Data Loading using COPY Statement
Bulk data loading using the COPY statement is a feature in databases like PostgreSQL and Snowflake that enables efficient and fast data ingestion from external sources. Unlike Snowpipe, which is designed for near-real-time ingestion from external sources, this Snowpipe alternatives allows users to load large volumes of data from cloud storage or local files into Snowflake tables efficiently.
Steps to Load Data
In this section, I will show you how to load data using the COPY statement.
Prerequisites:
- A Data Warehouse setup
- A Cloud Storage Platform
- A bucket in that platform that contains the data.
Step 1. Create Storage Integration
We need to create an interface between Snowflake and other third-party services. Storage Integration is an example of such an interface. To create a storage integration, use the command given below:
CREATE STORAGE INTEGRATION <integration_name>
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'GCS'
ENABLED = TRUE
STORAGE_ALLOWED_LOCATIONS = ('gcs://<bucket>/<path>/', 'gcs://<bucket>/<path>/');Here,
<integration_name> is the name you want to give the new integration.
<bucket> is the cloud bucket name containing your data files.
<path> is an optional field, which is the location of your bucket.

Step 2. Grant required Permissions
You need to go to your Cloud Platform and give Snowflake permission to access your Cloud buckets. Below, I have mentioned a list of those permissions :

Step 3. Create a Table
You need to create a table in your warehouse with the same schema that you want to load. The command to create a table is given below:
CREATE TABLE <Table_name>(
<column_name1> data_type,
<column_name2> data_type
);Step 4. Load your data using the COPY command
In the end, you need to load your data directly from your cloud storage to the warehouse using the command given below:
COPY INTO <table_created>
From <stage_name>
file_format=my_csv_format
on_eror=continue;

Advantages of Bulk Loading
Let’s dive into the advantages of COPY statement as Snowpipe Alternatives and how it can help.
- Speed: The COPY statement is helpful in bulk-loading large amounts of data into the database. It avoids line-by-line processing and performs direct bulk inserts, considerably speeding up data-loading processes.
- Direct Database Integration: The COPY statement is executed directly in the database and provides immediate availability and integration of data. This eliminates the need for additional services or integrations required by Snowpipe.
- Consistency: The COPY operations are fully transactional and ensure ACID compliance.
Use Cases of Bulk Loading as Snowpipe Alternatives
Some of the major use cases of COPY statement are discussed below:
- Initial Data Loading: While setting up a new database, the COPY statement is ideal for loading all the data from external files into the database directly.
- Migration and Upgrades: The COPY statement helps to migrate data from legacy systems into the new environment, ensuring data continuity and integrity.
- Data Backup: Copying data to archive for long-term storage or historical analysis is simplified with a COPY statement, allowing organizations to maintain comprehensive data archives for compliance or auditing purposes.
Cost Considerations
You can do the following to reduce the cost:
- You should optimize storage usage, leverage cost-effective storage tiers (e.g., archival storage for infrequently accessed data)
- You can compute resource usage and monitor data transfer volumes and patterns to optimize usage and minimize unnecessary spending.
Required Skills
Here are a few skills required to use the COPY statement:
- Knowledge of SQL for writing queries to load data.
- Understanding of data formats such as CSV or JSON to format input files.
- Familiarity with access controls and permissions for managing data security.
- The ability to optimize COPY operations for performance by configuring parameters such as batch size and error handling.
Which Alternative is the best pick?
- When your solution demands processing and data analysis on immediate terms, Apache Kafka is a suitable tool for the demand.
- If you want a processing engine that can handle complex data transformations and real-time implementations, Spark is the one.
- The COPY statement at Snowflake offers a plain way to bulk data loading from diverse sources and it is full of flexibility.

Conclusion
Snowpipe is good at real-time integration into Snowflake, but it fares poorly with respect to bulk transformations and heterogeneous structured data sources. Alternatives like Apache Kafka or Spark are both strong on complex transformations and have wide compatibility with different data sources. Additonally, the COPY statement in Snowflakes comes out to be more effective than other specialized features in other tools and applications. The choice is now yours.
You can also achieve seamless data integration and analytics in Snowflake with Hevo.
Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, check out our unbeatable pricing to choose the best plan for your organization.
Frequently Asked Questions (FAQs)
1. Is Snowpipe expensive?
Snowpipe’s compute costs are 1.25 times more expensive than the virtual warehouse’s compute costs.
2. Who is Snowflake’s biggest competitor?
Amazon Redshift and Google BigQuery are some of Snowflake’s major competitors.
3. Is Airflow better than Snowpipe?
Airflow is a batch scheduler, and to use it to schedule anything that runs more frequently than 5 minutes becomes challenging to manage. Also, you’ll have to manage the scaling yourself with Airflow.
4. What are the disadvantages of snowpipes?
Configuring Java Client is a technical task that requires technical expertise. So, it becomes a barrier for many organizations.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





