



Today, enterprises generate huge volumes of data. Most of them have learned that data is an important decision-making tool, so they store all the data generated from the departments. The purpose of storing the data is to analyze it to extract insights that can be used for decision-making. Enterprises may also collect data from external sources. This happens especially when an enterprise wants to know more about what is happening in the market and understand its competitors better.
In most cases, this data grows into huge volumes, running up to Petabytes. Since the data is collected from multiple sources, it’s normally in an unstructured format. When dealing with such data, dimensional models such as Data Warehouses can provide a more consistent and accessible data storage than Relational Databases.
A Data Warehouse can aggregate data from multiple sources into a single repository for analysis, reporting, and Business Intelligence. In this article, we will be discussing how to implement SQL Server for Data Warehouse.
Table of Contents
Understanding Data Warehouses
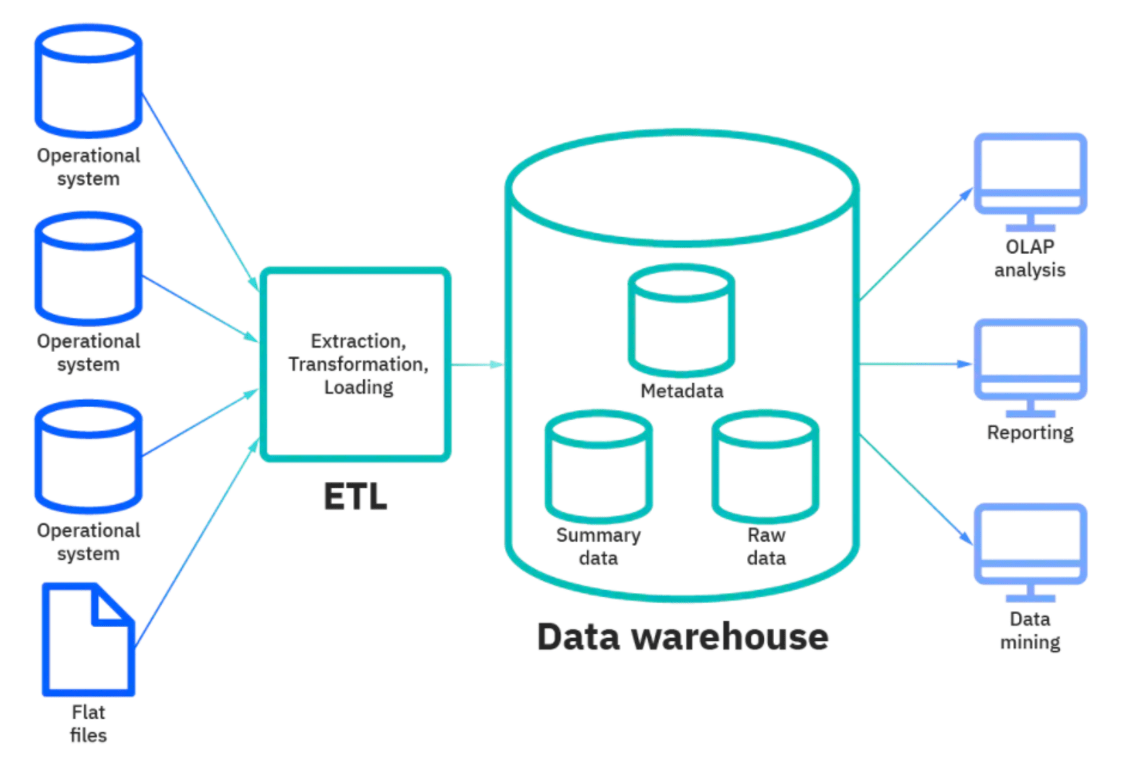
- A Data Warehouse refers to a large collection of business data that helps an organization to make data-driven decisions. A Data Warehouse normally connects and analyzes business data from heterogeneous sources.
- The Data Warehouse forms the core of the Business Intelligence system, which is used for data analysis and reporting. It is a blend of components and technologies that facilitate the strategic use of data. Data Warehouses are designed for querying and analysis rather than for transaction processing.
- The huge volumes of data stored in Data Warehouses come from multiple applications like sales, marketing, finance, external partner systems, customer-facing apps, etc.
- Technically, the Data Warehouse periodically pulls the data from such apps and systems, then the data is taken through formatting and import processes to match the data already stored in the Data Warehouse. The Data Warehouse then stores the data ready for access by decision-makers.
Hevo is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs. With integration with 150+ Data Sources (60+ free sources), we help you not only export data from sources & load data to the destinations but also transform & enrich your data, & make it analysis-ready.
Here’s what Hevo Data offers to you:
- Diverse Connectors: Hevo’s fault-tolerant Data Pipeline offers you a secure option to unify data from 150+ Data Sources (including 60+ free sources) and store it in any other Data Warehouse of your choice. This way, you can focus more on your key business activities and let Hevo take full charge of the Data Transfer process.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the schema of your Data Warehouse or Database.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Understanding SQL Server
- SQL Server is a popular Relational Database Management System (RDBMS) by Microsoft that also supports high availability configurations like Always On SQL Server.. It offers many features that you can use to create, manage, and analyze databases.
- Some of the key features that SQL Server provides include storing, retrieving, and securely managing relational data; it supports Transact-SQL (T-SQL), which enables you to query and manipulate data in your database. SQL Server also includes integration, analysis, and reporting capabilities that help in data modeling and generate useful insights.
Data Warehouse Schemas
The schema logically describes the entire database. It includes the names and descriptions of all record types, along with information on any related aggregates and data items. A data warehouse must maintain a schema, much like a database. In this section, we will discuss the schemas used in a data warehouse.
Schema Star
- In a star schema, a single one-dimensional table represents each dimension.
- The collection of characteristics is contained in this dimension table.
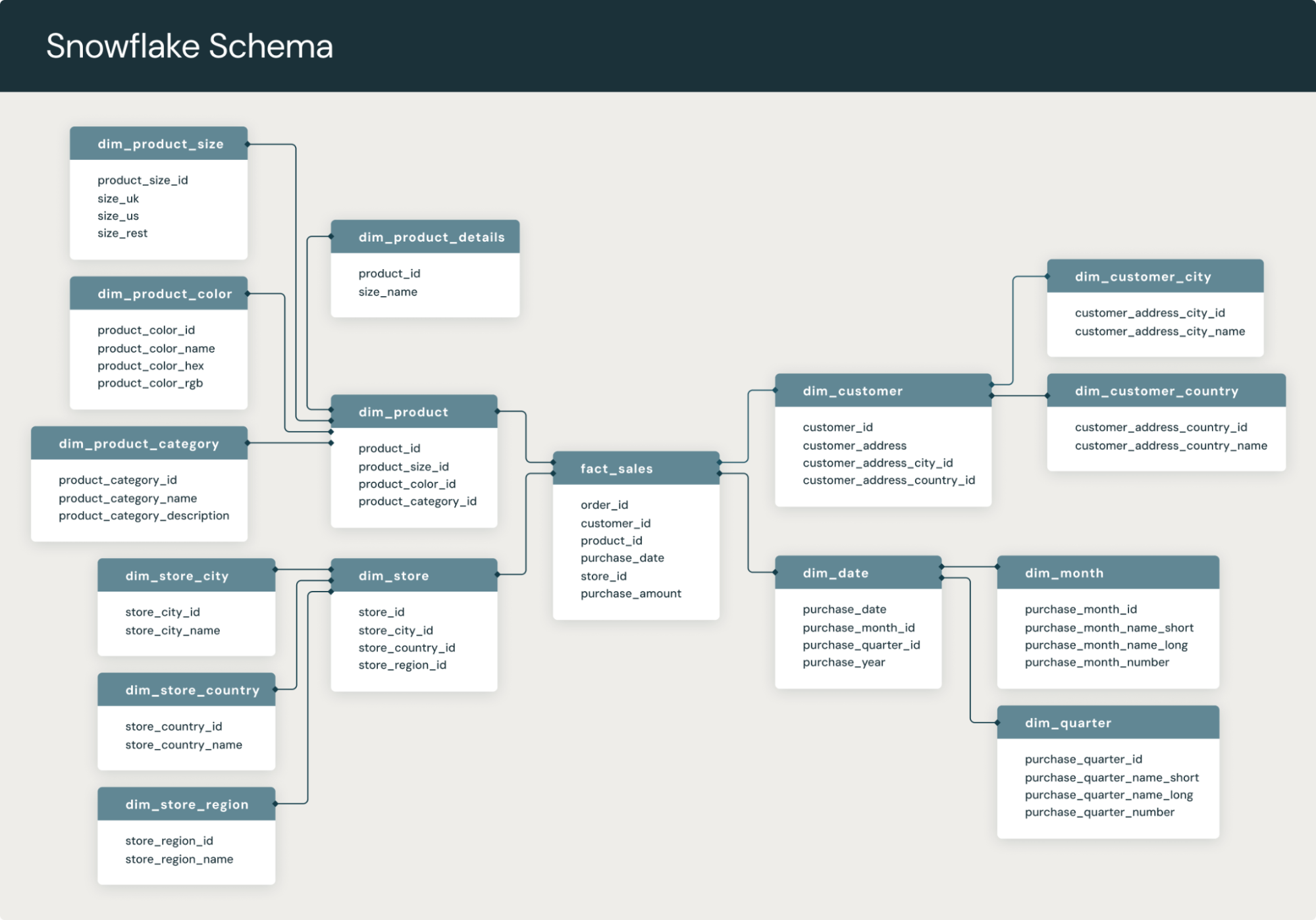
Snowflake Schema
- In the Snowflake schema, a few dimension tables have been normalized.
- The data is divided into many tables by the normalization process.
- The dimensions table in a snowflake schema is normalized, in contrast to a star schema.
Fact Constellation Schema
- There are several fact tables in a fact constellation. Another name for it is galaxy schema.
Steps to Implement a Data Warehouse with SQL Server
Microsoft SQL Server is a common Database Management System (DBMS) among organizations. It provides a Graphical User Interface (SSMS) through which you can run queries that access the database.
Understanding the Scenario
In this section, you will learn how to create a data warehouse in SQL Server. Suppose a wholesale shop X has several stores in the city, where various products are sold daily. They have asked you to design a system that will help them make quick decisions and show Return on Investment (ROI). Let us design a SQL Server for Data Warehouse for wholesale shop X. To implement a SQL Server for Data Warehouse, just follow the steps given below:
- SQL Server for Data Warehouse Step 1: Determine and Collect the Requirements
- SQL Server for Data Warehouse Step 2: Design the Dimensional Model
- SQL Server for Data Warehouse Step 3: Design your Data Warehouse Schema
- SQL Server for Data Warehouse Step 4: Implement your Data Warehouse


Step 1: Determine and Collect the Requirements
- First, you must interview the key decision-makers in the company to determine the factors that determine the business’s success. What are the most important business questions that the Data Warehouse must address?
- Also, you must talk to members from different departments to know more about their data, how they are related to members from other departments, and what they are expecting from the Data Warehouse.
- Also, talk to the management team and find out what their requirements are for the SQL Server for the Data Warehouse.
Step 2: Design the Dimensional Model
The dimensional model must address the users’ needs, contain easily accessible information, and be designed to allow for future scalability.
he dimensional model should have three components: dimensions, measures, and fact tables. Learn how these play out in Star Schema vs Snowflake Schema.
2.1: Dimension
This is the master table that is made up of individual, non-overlapping elements. The dimensions facilitate the filtering, grouping, and labelling of the data. Dimension tables have textual descriptions about the business subjects. In our case study, the dimensions can be Product, Customer, Mall, Date, Time, and Salesperson.
2.2: Measure
It represents a column with quantifiable data (numeric) that you can aggregate. A measure is mapped to a fact table column. In our case, some of the valid measures include Actual Cost, Total Sales, Quantity, and Fact Table record count.
2.3: Fact Table
The data stored in a Fact Table is known as Measures (also dependent attributes). The fact table should give statistics of sales broken down by customer, product, period, salesperson, and store dimensions. It contains the historical transaction entries from your live system, and it only has the Foreign key column that references different dimensions and numeric measure values on which aggregation is to be performed.
Fact Tables can be Snapshot, Transactional, or Cumulative. In our case study, the Fact Sales Table should have the following attributes:
- Foreign Key Column: Sales Date key, Sales Time key, Sales Person ID, Invoice Number, Store ID, Customer ID.
- Measures: Actual Cost, Quantity, Total Sales, Fact Table Record Count.
Step 3: Design your Data Warehouse Schema
- Now that you’ve identified the dimensions and the measures, you can use the right schema to relate the dimensions and the Fact Tables.
- Some of the most popular schemas used for the development of a dimensional model are Star Schema, Snowflake Schema, Distributed Star Schema, etc.
- Many prefer using the Star schema because it makes querying data easier.
Step 4: Implement your Data Warehouse
You can achieve this by running T-SQL scripts on SQL Server Management Studio (SSMS), a powerful IDE for SQL Server developers. Launch SSMS, connect to a database engine, and open a new query editor.
First, create a database in SQL Server for the Data Warehouse:
Create database Sales_DNext, select the database:
Use Sales_D
GoLet’s create the Customer Dimension table in the Data Warehouse to hold the personal details of customers:
Create table DimCustomerTable
(
CustomerID int primary key identity,
CustomerAltID varchar(15) not null,
CustomerName varchar(40),
Gender varchar(15)
)
goYou can fill it with some sample values using the INSERT statement. Next, you can create a basic level of the Product Dimension Table without having to consider any Category or Subcategory.
Create table DimProductTable
(
ProductKey int primary key identity,
ProductAltKey varchar(15)not null,
ProductName varchar(50),
ProductActualCost money,
ProductSalesCost money
)
GoYou can then fill it with some sample values. Next, create the Store Dimension Table to store the details of various stores located in different parts of the city:
Create table DimStoresTable
(
StoreID int primary key identity,
StoreAltID varchar(15)not null,
StoreName varchar(50),
StoreLocation varchar(50),
City varchar(50),
State varchar(50),
Country varchar(50)
)
GoYou can also fill it with some sample values. Next, create a Dimension SalesPerson table to store the details of salespersons working in different stores and fill it with sample values:
Create table DimSalesPersonTable
(
SalesPersonID int primary key identity,
SalesPersonAltID varchar(15)not null,
SalesPersonName varchar(50),
StoreID int,
City varchar(50),
State varchar(50),
Country varchar(50)
)
GoYou can then create the Dimension Tables for Date and Time, and then a Fact Table to store all the transactional entries of the previous day’s sales and the right foreign key columns referring to the primary key column of the dimensions.
Step 5: Construct the Sample Report
- At last, you can create the dashboards and reports that your stakeholders requested. Since they are most likely already familiar with Excel, you may use it. Power BI and SQL Server Reporting Services are further options.
OUTPUT: SAMPLE REPORT
The following is a potential report output for the data warehouse in SQL Server. It displays product sales by period using Power BI. The data warehouse may provide a few more reports, such as client sales or sales by location.
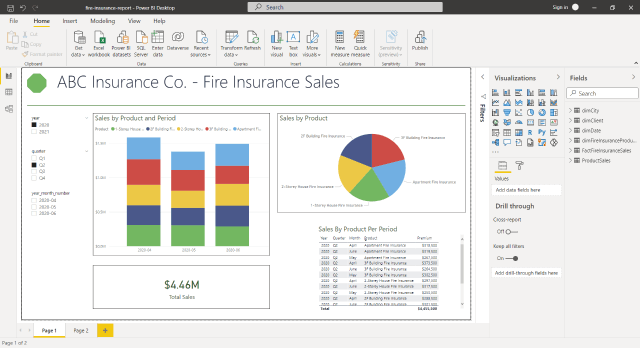
After doing that, your SQL Server for Data Warehouse will be ready!
Advantages of Microsoft SQL Server as a data warehouse
- To construct a data warehouse on MS SQL Server, all you would need to do is duplicate your database structure.
- With Python and R, MS SQL Server offers built-in capabilities for automated reporting, machine learning, and analysis.
- Additionally, SQL Server provides strong data security and protection.
- Managed Data Warehouse was first offered by SQL Server a few years ago; however, it can only be used for database performance monitoring.
Is SQL Server the Right Fit for Your Data Warehouse?
When to Use SQL Server as a Data Warehouse
SQL Server might be an excellent choice if you’re already immersed in the Microsoft ecosystem – for instance, utilizing tools like Power BI, Excel, or even Azure. Everything works harmoniously together, which can be a true advantage. Additionally, if you’re not managing vast amounts of data and don’t require real-time operations or numerous users accessing it simultaneously, SQL Server can operate efficiently.
And by the way, if you and your team are already proficient with SQL Server Management Studio (SSMS) and fluent in T-SQL, that’s a significant advantage!
Additionally, if you prefer having your assets on your own premises or a blend of your location and the cloud, while ensuring maximum security, SQL Server is certainly a suitable option for you.
When Not to Use SQL Server as a Data Warehouse
At times, SQL Server may not be the ideal companion for your data warehouse requirements. If you’re working with large volumes of data that must be processed extremely quickly, such as in real-time, or if you have various types of data that are not well-organized, SQL Server may begin to struggle.
Additionally, if you lack a tech expert available to adjust settings for optimal performance and configure all the intricate components, it may turn into a hassle. If you’re considering needing to frequently scale up or down, or if you prefer the notion of only paying for what you utilize, remember that SQL Server’s licensing can occasionally become somewhat expensive.
Ultimately, it comes down to the nature of your particular needs and circumstances.
Conclusion
Building a data warehouse with SQL Server is effective, but it takes time, effort, and technical resources. From designing schemas to managing data flows, it can quickly become overwhelming. Most teams would rather spend that time analyzing data, not setting up infrastructure.
That’s where Hevo helps. It automates end-to-end data pipelines, extracting, transforming, and loading data into SQL Server, BigQuery, Snowflake, and more. No manual scripts, no maintenance headaches—just clean, real-time data where you need it.
With 150+ integrations, auto schema mapping, and real-time sync, Hevo makes scaling your data workflows effortless. Plus, it takes minutes to set up and comes with 24/7 live support. Try it free for 14 days and simplify your data journey.
Frequently Asked Questions
1. Can SQL Server be used as a data warehouse?
Yes, SQL Server can be used as a data warehouse by leveraging its features for large-scale data storage, retrieval, and analysis.
2. What is the SQL data warehouse?
SQL Data Warehouse is a cloud-based, scalable, and fully managed data warehousing service by Microsoft, integrated with Azure for large-scale analytics.
3. What is Datastore in SQL Server?
In SQL Server, a datastore typically refers to a repository of data, such as a database or storage system used for managing and retrieving data.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





