

Hello, data enthusiasts! Have you ever wondered how companies make decisions based on real-time data? Well, let me tell you how. One of the most remarkable ways they do this is by streaming data to Amazon S3 (Simple Storage Service). Imagine you’re running a coffee shop, and you want to know what drinks are selling out in real-time. By streaming sales data to S3, you can see what’s trending, adjust your inventory, and even decide on your daily specials.
In this blog, I’ll walk you through the different ways of streaming data to S3 and share some tips on how to get the most out of it.
Table of Contents
Introduction to Amazon S3

Amazon S3 is a highly scalable, reliable, fast, and inexpensive data storage infrastructure on the cloud, also called “storage for the Internet“. It can store and retrieve any amount of data anytime, anywhere on the web.
Some essential properties of Amazon S3 are:
- The primary storage structure in S3 is a bucket.
- An S3 instance can have many buckets.
- The atomic data storage unit is called a file/object.
- An object is a file and any optional metadata that describes the file.
- An S3 bucket can store many files and can reside in a desired geographical location.
- The bucket’s creator can give others permission to create, delete, and list objects in the bucket.
What is Data Streaming?
Data Streaming is a technology that allows continuous real-time data transmission from a source to a destination. Rather than waiting for the complete data set to get collected, you can directly receive and process data when it is generated. A continuous flow of data, i.e., a data stream, is made of a series of data elements ordered in time. Data streaming is essential in scenarios where immediate insights and actions are critical, such as in finance, e-commerce, social media, and IoT applications.
Unlock the power of your data by streaming it directly to Amazon S3 for seamless storage and real-time insights. With Hevo, automate this process effortlessly, ensuring fast and reliable data ingestion without the hassle! With Hevo, you can:
- Automate Data Extraction: Effortlessly pull data from 150+ connectors(and other 60+ free sources).
- Transform Data effortlessly: Use Hevo’s drag-and-drop feature to transform data with just a few clicks.
- Seamless Data Loading: Quickly load your transformed data into your desired destinations, such as S3.
Try Hevo and join a growing community of 2000+ data professionals who rely on us for seamless and efficient migrations.
Get Started with Hevo for FreeUnderstanding the Need to Preplan the Data Ingestion
Data ingestion into S3 requires significant deliberation as the incoming data can be in many formats, arrive at different speeds, and have diverse pre-processing requirements.
If your data is not on the AWS infrastructure, you may want to use non-AWS solutions/tools to move your data into S3.
Method 1: Using Hevo Data for a Seamless and Simple Migration
Hevo allows you to stream data in real-time from various sources to S3 without requiring any technical expertise. You just need to follow two simple steps, and you can start streaming data to S3 without any hassle.
Step 1: Configure your desired source.
Step 2: Configure S3 as your destination.
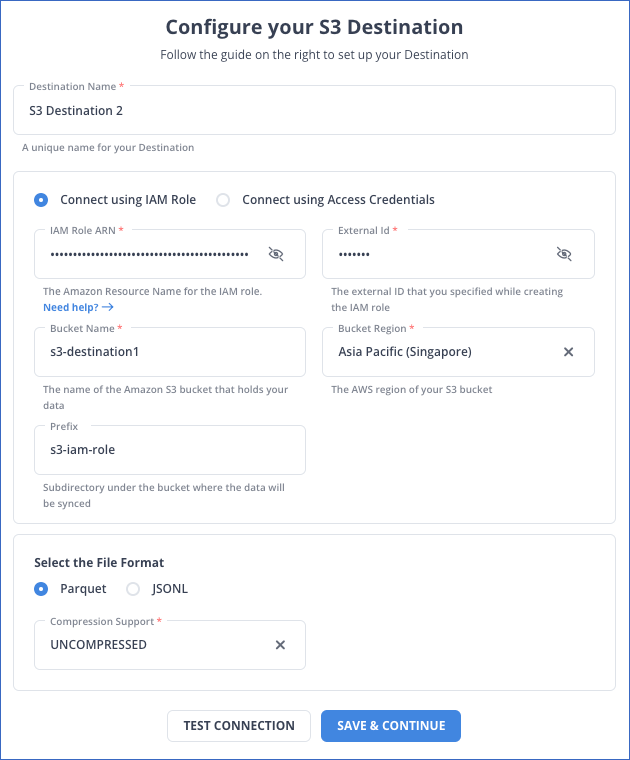
Method 2: Streaming Data to S3 using Apache Flume
Understanding Apache Flume

Flume is an open-source, distributed and reliable offering from Apache, using it does not bind you to any infrastructure or technology stack. Using Flume, you can seamlessly transport massive quantities of your data from many different sources, to a centralized data store. The data sources are customizable and can be network traffic data, event logs, social-media-generated data, or almost any kind of data.
We will use two abstractions frequently in this discussion:
- Flume Event: An atomic unit of data flow having a byte payload and some metadata (an optional set of string attributes).
- Flume Agent: A java process that enables the events to flow from an external source to the next destination (hop).
An event may hop through a few destinations before arriving to rest at the final warehouse destination(sink).
Procedure to Implement Streaming Data to S3
The “Agent” is the engine that will drive our data flow from source to sink(destination, S3 in our case). Using Flume, we have to first list our data sources+channels+sink for the given agent and then point the source and sink to a channel.
There can be multiple data sources and channels, but only a single sink.
The template format (stored in weblog.config file) for specifying these is:
#streaming data to S3
# list the sources, sinks and channels for the agent
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2>
# set channel for source
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...
# set channel for sink
<Agent>.sinks.<Sink>.channel = <Channel1>You can set the properties of each source, sink, and channel; in the following format:
#streaming data to S3
# properties for sources
<Agent>.sources.<Source>.<someProperty> = <someValue>
# properties for channels
<Agent>.channel.<Channel>.<someProperty> = <someValue>
# properties for sinks
<Agent>.sources.<Sink>.<someProperty> = <someValue>Since S3 is built over HDFS[Hadoop Distributed File System], we can use the HDFS-sink in Flume. The HDFS sink writes events(data) into the Hadoop Distributed File System.
It can bucket/partition the data based on attributes like timestamps/machine of origin/type etc. Compression is supported, as are text and sequence files.
More information about the HDFS can be found here.
Some configurable parameters include:
- hdfs.path: HDFS directory path (eg hdfs://YourNamedNode/flume/stockdata/ OR s3n://bucketName).
- hdfs.filePrefix: Name prefixed to files created by Flume in hdfs directory.
- hdfs.fileSuffix: Suffix to append to file (eg .avro OR .json).
- hdfs.rollSize: File size to trigger roll, in bytes (0: never roll based on file size).
- hdfs.rollCount: Number of events written to file before it rolled (0 = never roll based on number of events)retryInterval – Time in seconds between consecutive attempts to close a file.
A typical S3 sink configuration can be like this:
#streaming data to S3
agent.sinks.s3hdfs.type = hdfs
agent.sinks.s3hdfs.hdfs.path = s3n://<AWS.ACCESS.KEY>:<AWS.SECRET.KEY>@<bucket.name>/prefix/
agent.sinks.s3hdfs.hdfs.fileType = DataStream
agent.sinks.s3hdfs.hdfs.filePrefix = events-
agent.sinks.s3hdfs.hdfs.writeFormat = Text
agent.sinks.s3hdfs.hdfs.rollCount = 0
agent.sinks.s3hdfs.hdfs.rollSize = 33554432
agent.sinks.s3hdfs.hdfs.batchSize = 1000
agent.sinks.s3hdfs.hdfs.rollInterval = 0Though we have discussed a single flow from a source to S3 sink, a single Flume agent can contain several independent flows. You can list multiple sources, sinks, and channels in a single config.
Flume allows you to define multiple hops, where the flow starts from the first source, and then the receiver sink can forward it to another agent, and so on. Flume also allows you to fan outflows, data from one source can be sent to multiple channels. For security, SSL/TLS support is inbuilt in Flume for many components.
More information on the working of Apache Flume can be found here.
Limitations of using Apache Flume while Streaming Data to S3
- You need to configure the agent to correctly identify/load all the required data, define the hops(connections) correctly to set up the data flow, and configure the sink to receive them.
- Any pre-processing required must be explicitly programmed or configured.
- You are required to know the internals of S3, HDFS, JVM, etc.
Method 3: Streaming Data to S3 using Amazon Kinesis
Understanding Amazon Kinesis
Amazon Kinesis enables real-time processing of large data. It’s built for real-time applications and allows developers to pull data from multiple sources while scaling up and down on EC2 instances.
It captures, stores, and processes data from big, dispersed sources like event logs and social media feeds. So to sum up, Amazon Kinesis delivers data to various consumers at the same time once it has been processed.
Amazon Kinesis Firehose delivery streams can be built via the console or the AWS SDK. We will use the ole to construct the distribution stream for our blog post. We can edit and modify the delivery stream at any time once it is generated.


Procedure to Implement Streaming Data to S3
Step 1: Access Kinesis Service
First, navigate to the Kinesis service, which is located in the Analytics category. If you have never used Kinesis previously, you will be presented with the following welcome page.

To begin creating our delivery stream, click on Get Started.
Step 2: Configure the Delivery Stream
Enter a name for the Delivery stream. Select Direct PUT or other sources provided under the Source section. This option creates a delivery stream to which producer programs can write directly.
If you choose the Kinesis stream, the delivery stream will use a Kinesis data stream as a data source. You should choose the first alternative to simplify the process of streaming data to S3.

Step 3: Prerequisities for Lambda Function
Kinesis Firehose can use Lambda functions to alter incoming source data and distribute it to destinations. AWS provides blueprints for Lambda functions. But, before we create a Lambda function, let’s go over the prerequisites of data transformation for streaming data to S3.
- recordid: The ID of the record delivered from Kinesis Firehose to Lambda during the invocation.
- result: The state of the data modified by the Lambda function.
- data: The data that has been altered.
There are numerous Lambda blueprints available for us to employ while developing our Lambda function for data transformation. One of these blueprints will be used to develop our Lambda function.
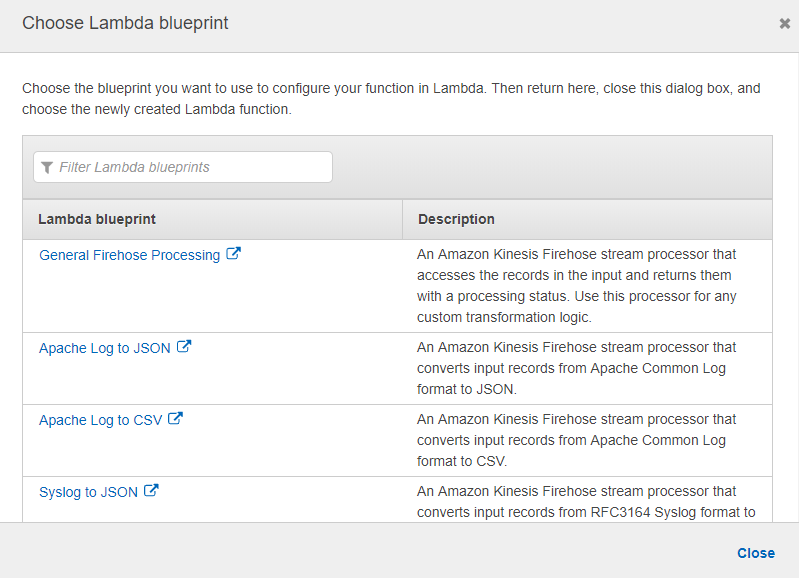
This prompts you to select a Lambda function. Choose the Create new option. The Lambda designs for data transformation are supplied here. As our blueprint, you’ll use General Firehose Processing.
Please give the function a name. Then we can give an IAM role with access to the Firehose delivery stream and authority to invoke the PutRecordBatch action.
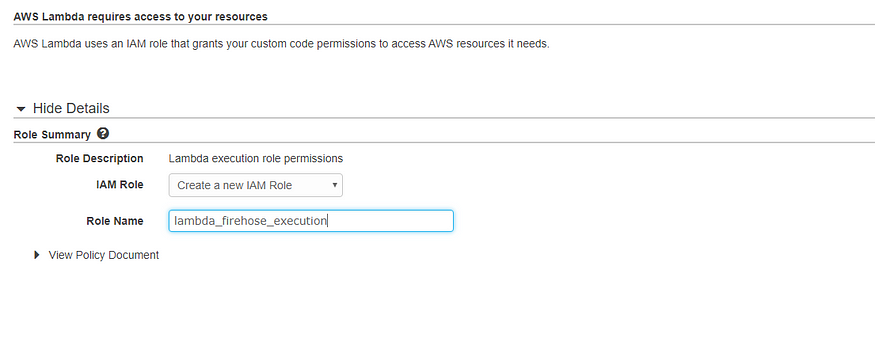
Step 4: Configure the Destination
Following the creation of the IAM role, you will be forwarded to the Lambda function creation page. Select the newly formed role and then in order to alter our data records develop your own Lambda function code. The Lambda blueprint has already filled in the code with the predetermined rules that you must follow.
Our streaming data will be in the following format.
#streaming data to S3
{"TICKER_SYMBOL":"JIB","SECTOR":"AUTOMOBILE","CHANGE":-0.15,"PRICE":44.89}On the following page, you will be asked to choose a location to save your records to S3.
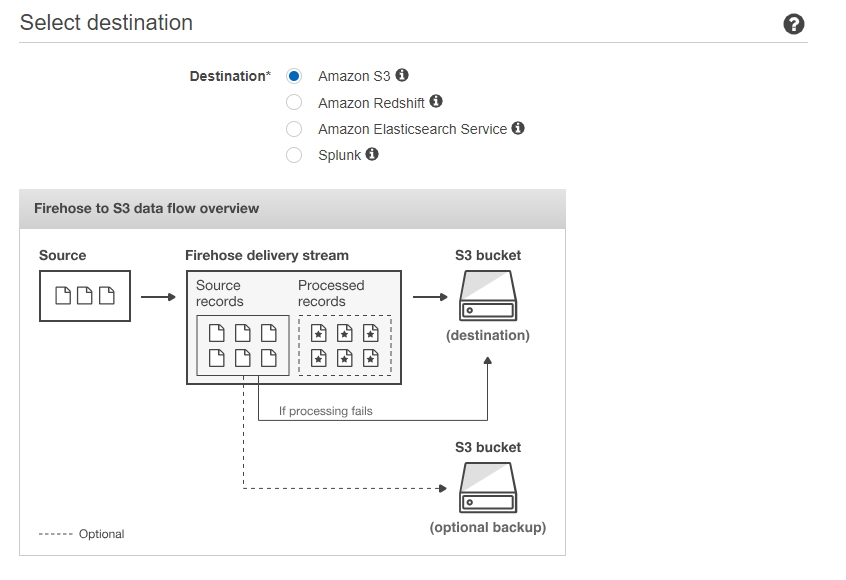
After evaluating the configurations, construct an Amazon Kinesis Firehose delivery stream by clicking Create Delivery Stream. The new Kinesis Firehose delivery stream will be accessible in the Creating State Section. After changing the delivery stream’s state to Active, you can begin transmitting data.
After changing the delivery stream’s state to Active, you can begin transmitting data to S3 from a producer.

You can go to the destination S3 bucket and verify that the streaming data was saved there. Check to see if the streaming data has the Change attribute as well. The backup S3 bucket will contain all of the streaming records prior to transformation.
And that’s it! You have now successfully established and tested a delivery system for streaming data to S3 using Amazon Kinesis Firehose.


Conclusion
So, there you have it! Streaming data to Amazon S3 can transform how you do business. Just picture that coffee shop again: by using S3, you’re not only keeping track of your best-selling drinks but also discovering trends and making smarter decisions on the fly. With S3’s ability to handle large amounts of data seamlessly, it becomes a powerful tool for anyone looking to stay ahead of the game.
And here’s where Hevo comes in to make things even easier! Hevo allows you to set up data streaming to S3 with just a few clicks, without complex coding or infrastructure management. Sign up for Hevo’s 14-day free trial to automate the entire process, ensuring your data is continuously updated and ready for analysis.
FAQs on streaming data to S3
Can you stream to an S3 bucket?
Yes, you can stream data to an S3 bucket using services like Amazon Kinesis Firehose, which allows data streaming directly into S3 for storage or further processing.
Is S3 good for streaming?
S3 is not typically used for real-time streaming but is excellent for storing and archiving streamed data. Amazon Kinesis or AWS IoT is used for streaming, while S3 is used for persistent data storage.
Can Kinesis Data Streams send data to S3?
Yes, Amazon Kinesis Data Streams can send data to S3 through Kinesis Firehose, which allows you to load streaming data into S3 in real-time for analysis or storage.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





