

Hadoop has an open-source data management framework that allows organizations to store, organize, manage, and process petabyte-scale big data operations. Organizations often use Hive, a SQL engine built on top of the Hadoop framework for querying and batch-processing big data.
Since Hive is a part of the Hadoop environment, it helps developers to effectively analyze Hadoop data without using any third-party data processing tools. However, Hadoop does not have any built-in data visualization tools to create visual or graphical representations in the form of interactive dashboards that provide clear perceptions about data present in Hadoop.
To eliminate such limitations, Hadoop can be connected with external business intelligence tools to perform data visualizations for getting meaningful insights into Hadoop data. One such business intelligence tool is Tableau, which allows you to create graphical representations of data in the form of dashboards and reports. On connecting Hadoop to Tableau, you can seamlessly perform data visualization and analysis on Hadoop data.
In this article, you will learn about Tableau Hadoop Integration, and how to analyze big data using the connect.
Table of Contents
What is Tableau?

Developed by Pat Hanrahan, Christian Chabot, and Chris Stolte in 2003, Tableau is a business intelligence tool used for data analysis and visualization. With Tableau, you can create graphs, charts, and reports in the form of interactive dashboards, making it easier for anyone to understand the data patterns and trends over time.
Looking for the best ETL tools to connect your data sources? Rest assured, Hevo’s no-code platform helps streamline your ETL process. Try Hevo and equip your team to:
- Integrate data from 150+ sources(60+ free sources).
- Utilize drag-and-drop and custom Python script features to transform your data.
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
Try Hevo and discover why 2000+ customers have chosen Hevo over tools like AWS DMS to upgrade to a modern data stack.
Get Started with Hevo for FreeWhat is Hadoop?

Developed by Doug Cutting and Mike Cafarella in 2005, Hadoop is an open-source software framework that allows you to store, manage, and process big data. In other words, Apache Hadoop is a java-based platform for storing and processing big data in a distributed computing environment. Since Hadoop is a distributed framework, you can scale data workloads across multiple servers or nodes to perform batch processing, thereby achieving high fault tolerance.
Tableau Hadoop Integration
Connection Prerequisites For the Tableau Hadoop Connect
To set up the Tableau Hadoop Connect, you should readily have an active Google Cloud account and a pre-installed Tableau in your local machine.
Secondly, it’s also required to have already subscribed to Google services, such as Dataproc, Cloud SQL, Cloud Storage, and Network egress. Since these are billable services of Google Cloud Platform, you can use the pricing calculator to generate the cost estimate based on your project or business preferences.
Creating a New Project

- Visit the project selector page of the Google Cloud Console and click on the “Select Project” button to select your existing project. You can also create a new project by clicking on the “Create Project” button.
Enabling APIs

- For enabling APIs of Dataproc, Cloud SQL, and Cloud Key Management Services, you have to confirm your project by clicking on the “Next” button, as shown in the above image.
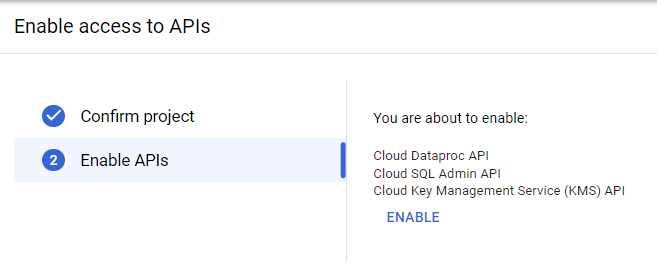
- Now, you are prompted to enable all three APIs of Cloud Dataproc, Cloud SQL Admin, and Cloud Key Management Service (KMS) API. Click on the “Enable” button to activate all three APIs.
Initializing the Cloud Environment
- In your Google Cloud Console, activate the “Cloud Shell” that resembles the command prompt of your local machine and is used to run commands and queries.
- In the Cloud shell, enter the environment variables along with the Project ID, region, and Zone of the Dataproc clusters, as given below.
export PROJECT_ID=$(gcloud info --format='value(config.project)')
export REGION=us-central1
export ZONE=us-central1-bSetting Up a Service Account For the Tableau Hadoop Connect
- Enter the command given below to create a new service account, which your cluster will use to access Google Cloud resources in the further steps.
gcloud iam service-accounts create cluster-service-account
--description="The service account for the cluster to be authenticated as."
--display-name="Cluster service account"
- After setting up a service account, you should create a backend cluster for Dataproc and encrypt the passwords for Cloud Key Management Service. You can follow this GitHub repository to get relevant code for cluster creation and password encryption.
Creating a Sample Hive Table
Hive runs on top of the Hadoop architecture and provides an interface that resembles SQL frameworks for processing or querying the data. In other words, Hive is a SQL-based database that allows users to read, write, and manage petabytes of data. Since Hive is built on top of Apache Hadoop, it serves as a data warehousing service that reads, writes, and manages large datasets that are stored in Hadoop servers.
- Enter the following command in the cloud shell to create a Cloud Store bucket for storing a sample Apache Parquet file. Apache Parquet is the column storage file format used by Apache Hadoop ecosystems, such as Pig, Spark, and Hive to support fast data processing, regardless of the choice of data processing framework.
gsutil mb -l ${REGION} gs://${PROJECT_ID}-hive- Now, copy the publicly available sample Parquet file into the newly created bucket.
gsutil cp gs://hive-solution/part-00000.parquet
gs://${PROJECT_ID}-hive/dataset/transactions/part-00000.parquet- Then, connect to the master node of the Dataproc cluster by entering the following command.
gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-m- Now, a new command terminal is opened, where you have to enter the command given below to connect to the local Hive server.
beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice admin admin-password"
--hivevar PROJECT_ID=$(gcloud info --format='value(config.project)')- Now, execute the below command to create a new table using the Parquet file that you copied to the newly created bucket.
CREATE EXTERNAL TABLE transactions
(SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING)
STORED AS PARQUET
LOCATION 'gs://${PROJECT_ID}-hive/dataset/transactions';- Run a simple SQL query to check whether the table is created correctly.
SELECT * FROM transactions LIMIT 10;- After executing the above command, you will get an output in a tabular format on your command prompt.
Creating a Proxy Cluster
At this stage, you have to create a proxy cluster that provides Apache Knox initialization action. The Apache Knox gateway system gives a single point of authentication for external applications to access Apache Hadoop services and REST APIs in a cluster.
- Initially, you have to clone the Dataproc “initialization-actions” GitHub repository by executing the following command.
git clone https://github.com/GoogleCloudDataproc/initialization-actions.git- Create the topology file that points to the backend cluster.
export KNOX_INIT_FOLDER=`pwd`/initialization-actions/knox
cd ${KNOX_INIT_FOLDER}/topologies/
mv example-hive-nonpii.xml hive-us-transactions.xml- Now, open the “hive-us-transactions.xml” with your preferred editor application. Add the user identity to Hive as “Sara,” which acts as the fictitious admin for the tutorial purpose.
<param>
<name>hive.acl</name>
<value>admin,sara;*;*</value>
</param>
- In the next step, you have to point the HIVE client URL to the backend cluster by editing the .xml file, given below.
<service>
<role>HIVE</role> <url>http://<backend-master-internal-dns-name>:10000/cliservice</url>
</service>
- After customizing the .xml file, save the file and close the editor. Furthermore, if you need more security while accessing Apache services and APIs via Apache Knox, you should configure the SSL/TLS certificate. You can also create a new proxy cluster for managing the requests and transactions of Apache Knox. For creating proxy clusters and configuring Apache Knox transaction files, you can follow the official documentation.
Setting up Authorization
- In this step, you have to configure the “user sync” configuration file for setting up authorization.
- Now, execute the following command to connect to the master node of the backend cluster created before.
export BACKEND_CLUSTER=backend-cluster
gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-m- Then, run the below-given command to edit the “user sync” file for customizing the properties.
sudo vi /etc/ranger/usersync/conf/ranger-ugsync-site.xml- In the “user sync” configuration file, edit the properties, as shown in the below image.

- After customizing the “user sync” configuration file, save the file and close the editor.
Setting up Ranger Admin Console
In this step, you have to set up the Range Admin console to enable, monitor, and manage comprehensive data security across the Hadoop ecosystem while connecting with external or third-party applications.
- Navigate to the Dataproc page in your cloud console and click on the previously created backend cluster. Then, click on “Web Interfaces” to find a list of Hadoop components that are actively running in your cluster.
- Now, click on Ranger from the Hadoop components list to open the Ranger console.
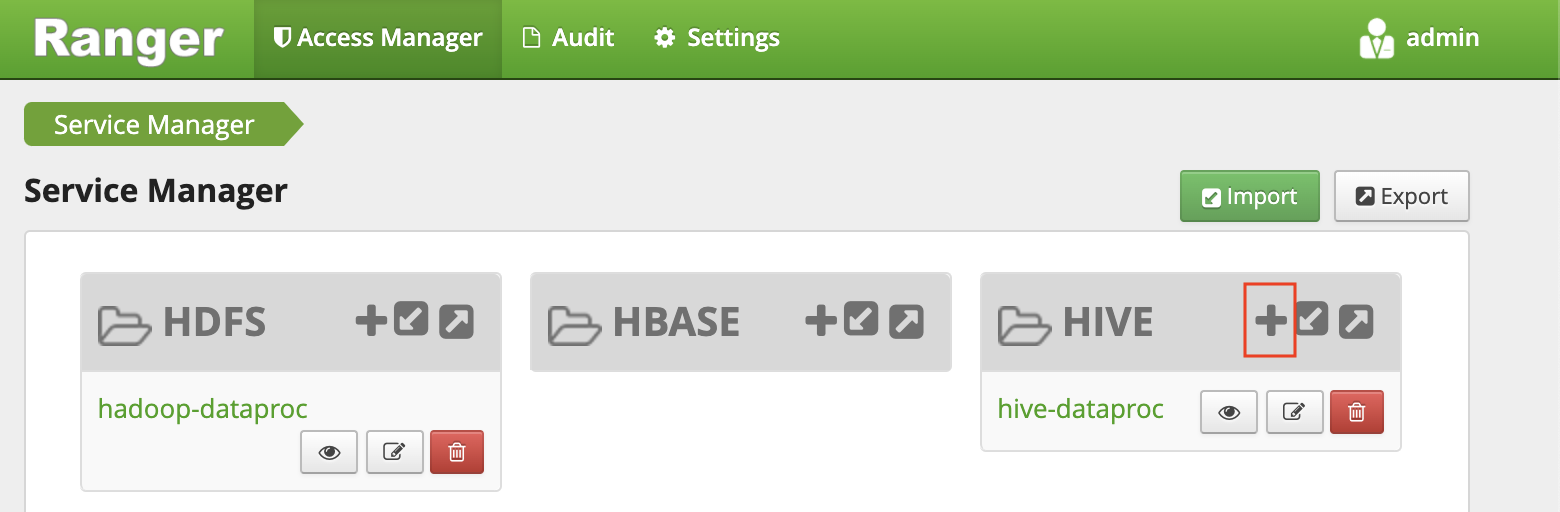
- In the Ranger console, you can find the service manager page, as shown above.
- Now, click on the plus symbol near the HIVE service to create a new HIVE service.
- Then, you are prompted to fill in the connection configuration information. Enter the configuration information, as given below.
- Service name: ranger-hive-service-01
- Username: admin
- Password: admin-password
- JDBC driver class name: org.apache.hive.jdbc.HiveDriver
- JDBC URL: jdbc:hive2:<backend-master-internal-dns-name>:10000/;transportMode=http;httpPath=cliservice
- After filling in the necessary information, click on the “Add” button.
Connecting Tableau Hadoop
- At this stage, you are all set for the Tableau Hadoop Connect to query Hadoop data from the Tableau workspace.
- Initially, you have to create a firewall to open the TCP port for data transfer.
- Execute the following command to open the TCP port 8443.
gcloud compute firewall-rules create allow-knox
--project=${PROJECT_ID} --direction=INGRESS --priority=1000
--network=default --action=ALLOW --rules=tcp:8443
--target-tags=knox-gateway
--source-ranges=<your-public-ip>/32- In the place of <your-public-ip>, enter the public IP address of your local machine. To find the public IP address of your local machine, visit the Find your IP website.
- Now, apply the firewall configuration to the master node of the proxy cluster by running the command given below.
gcloud compute instances add-tags ${PROXY_CLUSTER}-m --zone=${ZONE}
--tags=knox-gateway- In the next step, download and install the Hive ODBC driver by following the official documentation.
- Now, open the Tableau Desktop and click on the “Connect” menu on the home page.
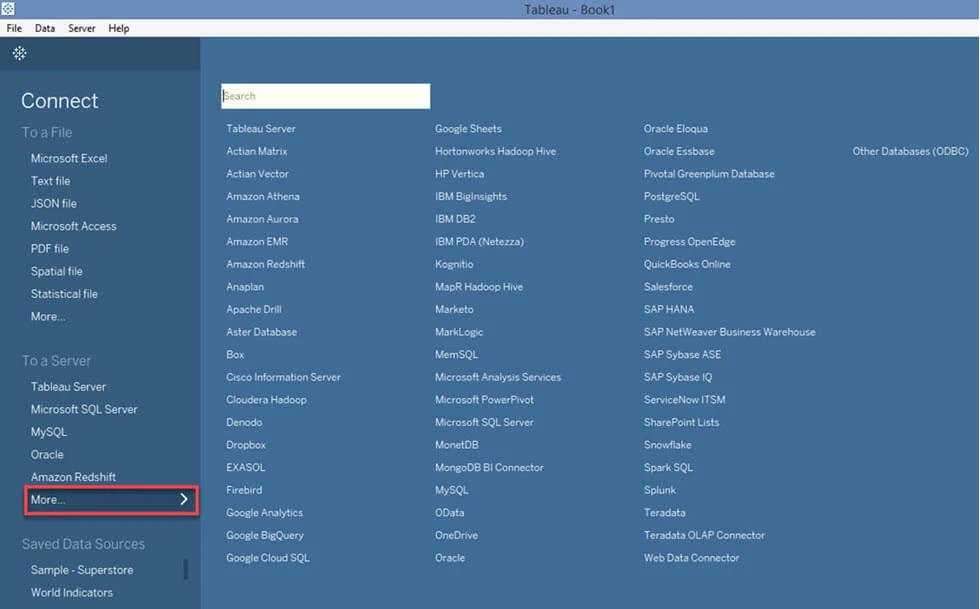
- Click on the “More” option on the left pane and search for Cloudera Hadoop. On finding the Cloudera Hadoop, click on it.
- The Cloudera Hadoop dialogue will pop up and prompt you to enter the server information.

- Enter the necessary server configuration details and click on the “Sign In” button.
- Now, you are all set to query the Hadoop data by setting up the Tableau Hadoop Connect.
- After the Tableau Hadoop Connect is successful, in Tableau, go to the Data Source screen, and click on “Select Schema.” Then, search for the schema named “default.”
- On double-clicking the “default” schema, it will open the data table panel.
- Then, double click on the “New Custom SQL in the table panel.” Now, the “Edit Custom SQL” window opens, where you can run queries to fetch data from Hadoop.
- Enter the following query in the “Edit Custom SQL” window to select the date and transaction type from the transactions table in Hadoop.
SELECT `submissiondate`,
`transactiontype`
FROM `default`.`transactions`- After running the above command, the metadata for the transaction query is retrieved from Hive. Now, click on the “Update Now” button.
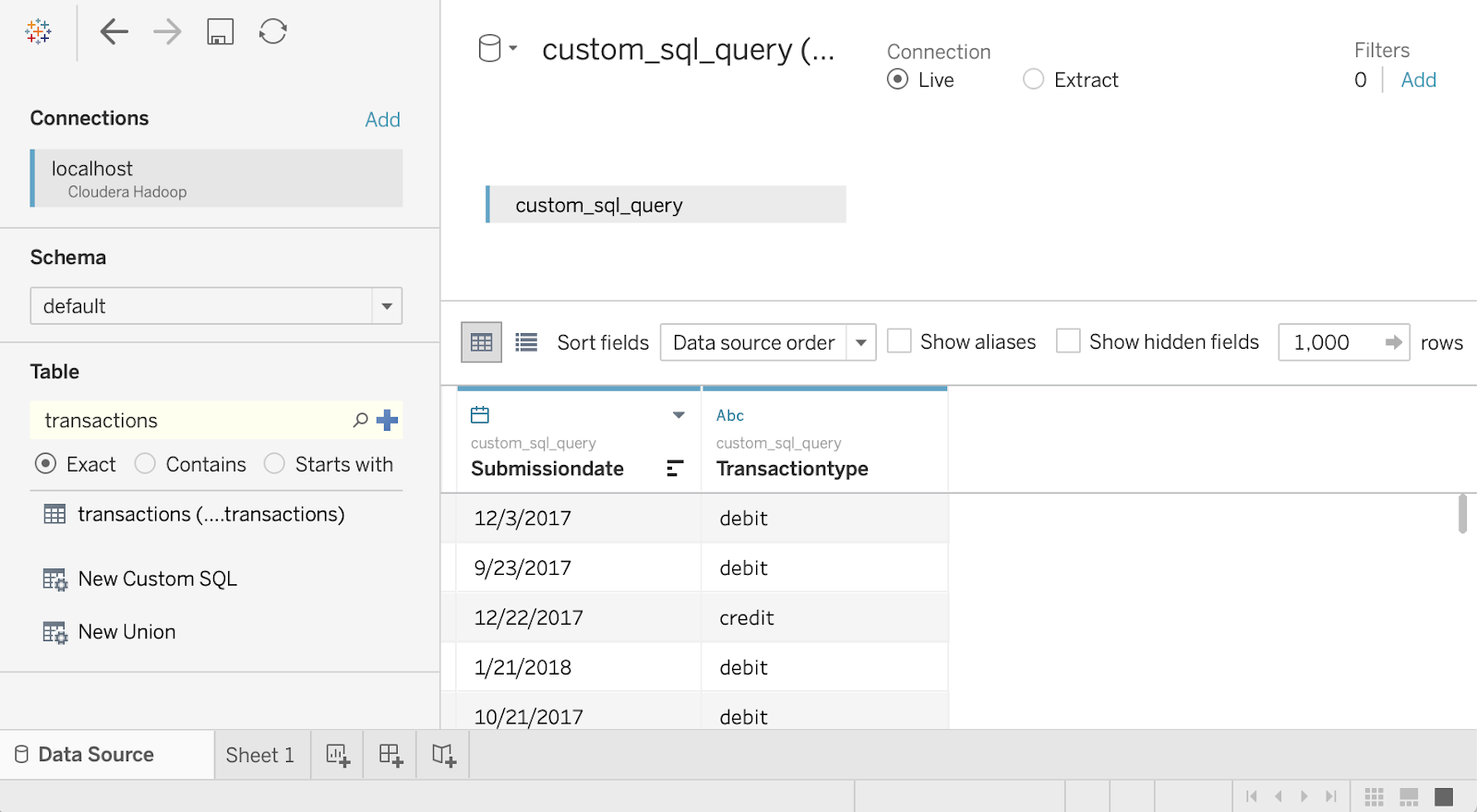
- As shown in the above image, you successfully fetched Hadoop data from the “transactions” table. Similarly, you can fetch any data from Hadoop by writing queries in Tableau Desktop; hence emphasizing the Tableau Hadoop connect works.
On following the above-given steps, you successfully established the Tableau Hadoop connect, fetching data from the Hadoop tables faster than before.
You can also take a look at how you can effortlessly set up Tableau REST API Connection and Tableau Hive Connection step-by-step.
Benefits of Tableau Hadoop Connection
- Seamless Big Data Integration: Connect Tableau directly to Hadoop, enabling smooth analysis of large datasets.
- Real-Time Insights: Access and visualize data from Hadoop clusters in real-time without heavy data extraction.
- Enhanced Decision-Making: Analyze big data trends with powerful Tableau visualizations for actionable insights.
- Scalability: Handle growing data volumes efficiently with Hadoop’s robust storage capabilities combined with Tableau’s intuitive tools.
- Cost-Effective Analytics: Reduce data processing costs by leveraging Hadoop’s open-source framework alongside Tableau’s visualization prowess.
Conclusion
In this article, we learned about Tableau and Hadoop in brief. We also talked about the steps to establish the Tableau Hadoop connect.
This article mainly focused on setting up the Tableau Hadoop connect via Google Cloud Platform with several levels of the authentication process for attaining high security during data transfer. However, you can also use third-party connectors or drivers for the Tableau Hadoop Connect to perform end-to-end data transfer.
Hevo, with its strong integration with 150+ sources and BI tools allows you to not only export & load data but also transform & enrich your data & make it analysis-ready in a jiffy.
Try Hevo and see the magic for yourself. Sign up for a free 14-day trial to streamline your data integration process. You may examine Hevo’s pricing plans and decide on the best plan for your business needs.
FAQs
1. Does Tableau work with Hadoop?
Yes, Tableau can connect to Hadoop through various interfaces such as Hive, Impala, or Presto. It allows users to visualize and analyze data stored in Hadoop clusters.
2. How to connect Tableau to HDFS?
To connect Tableau to HDFS, use a Hadoop distribution that supports a query engine like Hive or Impala. Connect Tableau to Hive/Impala, which in turn queries data stored in HDFS.
3. Can Tableau connect to big data?
Yes, Tableau can connect to big data sources, including Hadoop, Spark, and cloud data warehouses like BigQuery or Redshift. It enables users to visualize and analyze large volumes of data efficiently.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





