




Data Modeling is the process of cleansing and organizing data into a visual representation or plan that aids in the mapping out of database relationships and operations. Various types of data models serve as a blueprint for creating an optimal database, regardless of its specific contents.
This article talks about the different types of Data Models and the process of Data Modeling along with a few Data Modeling Tools. We’re also going to take a look at the types of data modeling later in the article to provide you with a comprehensive understanding of the topic.
Table of Contents
What is a Data Model?
A data model is a graphical technique that allows you to start with the big ideas when constructing your database. It provides a uniform framework for representing real-world entities and their attributes.
The Data Model gives us an idea of how the final system will look after it has been fully implemented. It specifies the data items as well as the relationships between them. In a database management system, data models are used to show how data is stored, connected, accessed, and changed.
We portray the information using a set of symbols and language so that members of the organization may communicate and understand it.
Why Create a Data Model?
The following are the technical advantages of having a data model:
- Technical Layer: A technical layer is attached to a data model that contains all the technical information (specified by the Data Architect), allowing developers to concentrate on implementation rather than interpretation.
- Lesser Mistakes: Fewer mistakes are made on the data and application side as a result of the Data model’s clarity and precision. Developers can concentrate on feature development rather than database design.
- Database Structure Optimization: The Database structure can be optimized right from the start before any data is entered. This decreases the amount of data that needs to be moved (i.e., to improve performance after the database is in production).
- Data Risk Reduction: Risks to data are reduced. Data Architects and Database Administrators can develop backup and restore procedures if they have a better understanding of the data’s size. In a disaster recovery scenario, having strategies and safeguards in place decreases risks.
Providing a high-quality ETL solution can be a difficult task if you have a large volume of data. Hevo’s automated, No-code platform empowers you with everything you need to have for a smooth data replication experience. Check out what makes Hevo amazing:
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Types of Data Models
When dealing with the different types of Data models, a variety of stakeholders are engaged. As a result, there are three types of data models that meet the needs of each stakeholder. The following are the:
Each data model builds on the previous one to develop the database structure.
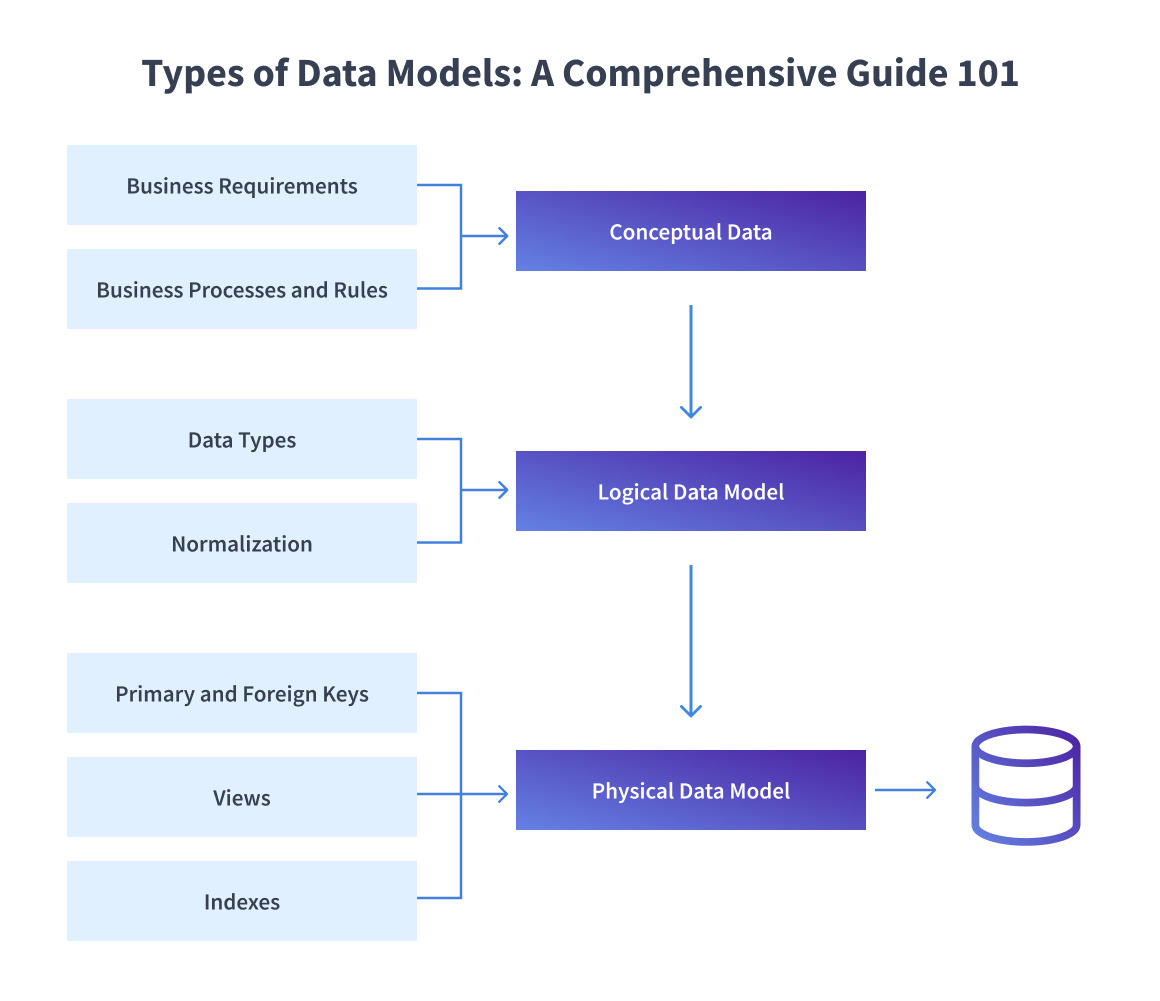
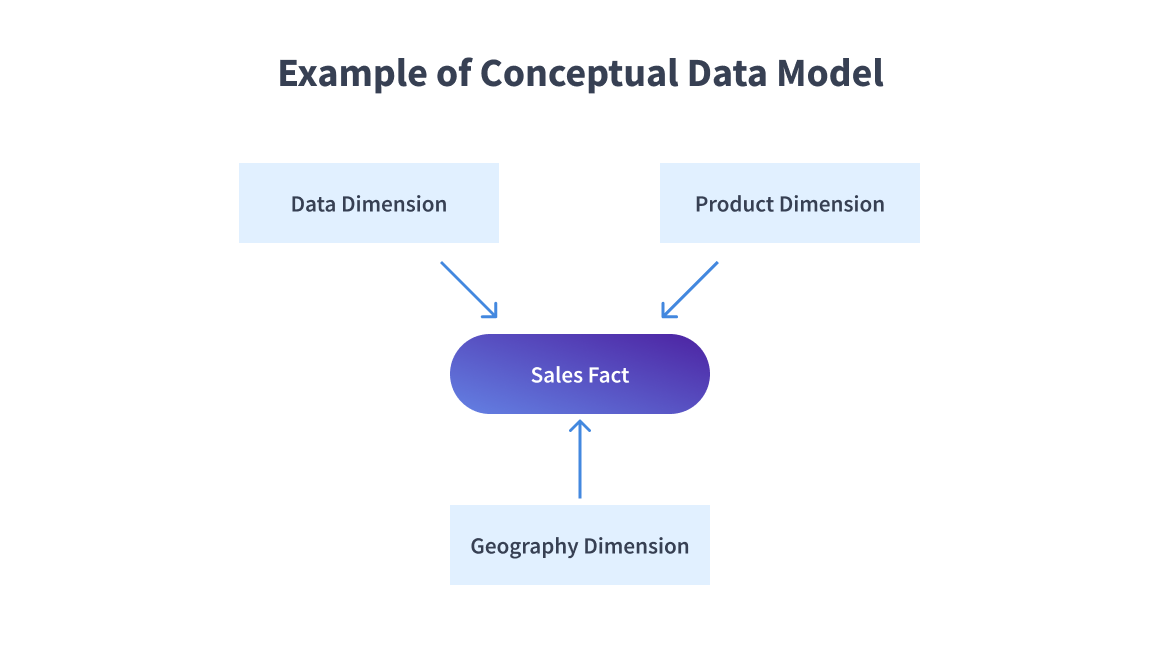
Conceptual Data Model
Conceptual Data Model is the first type of data model also known as Domain Model.
| ASPECT | DESCRIPTION |
| Focus | Provides a big-picture view of system contents, organization, and business rules. |
| Project Stage | Generated during the early requirements-gathering phase. |
| Entity Classes | Define significant items (entities) represented in the data model |
| Attributes and Constraints | Include characteristics, limitations, and relationships between entities |
| Security and Data Integrity | Addresses security measures and data integrity requirements |
| Notation | Usually uses straightforward and simple notation |
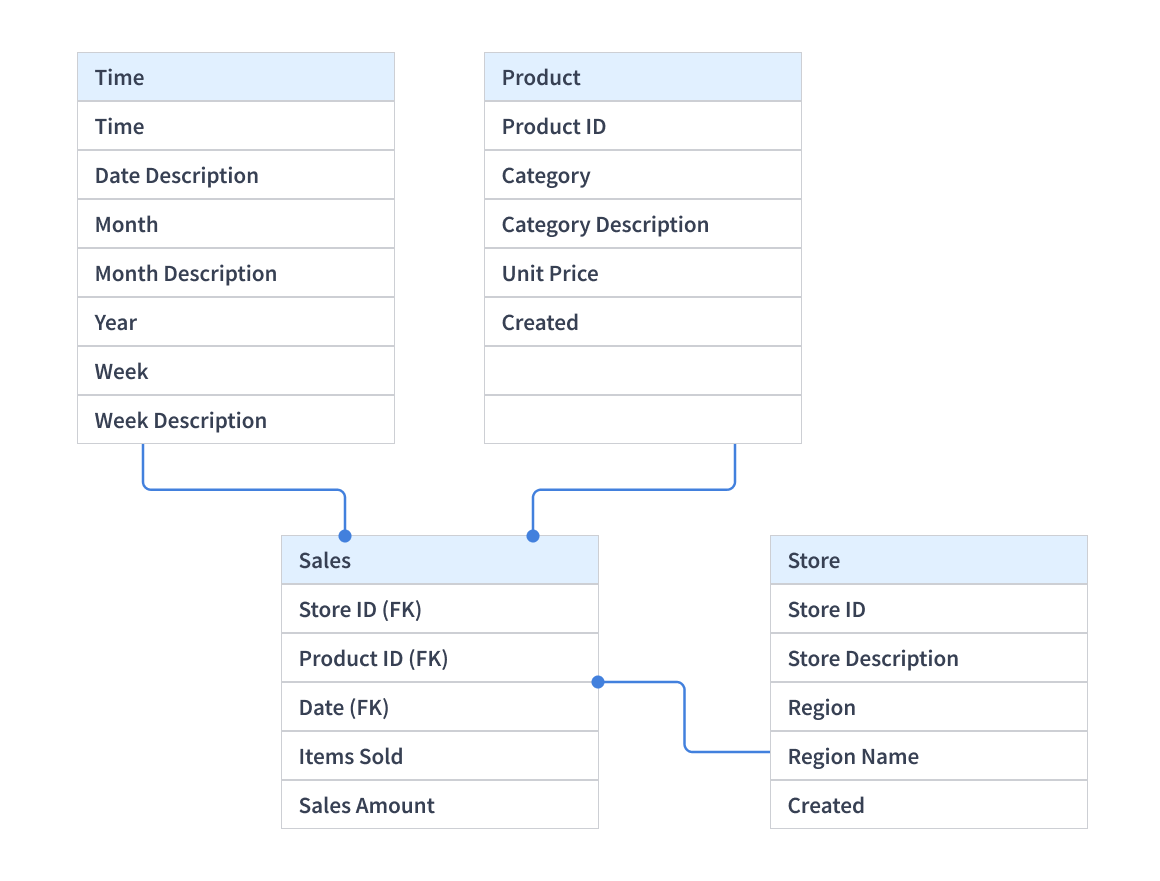
Logical Data Model
The Logical Data Model is the second one in the types of Data models.
| ASPECT | DESCRIPTION |
| Abstraction Level | Less abstract than conceptual models, providing more details on concepts and relationships |
| Modeling System | Follows a formal Data Modeling notation system |
| Data Properties | Defines data types, lengths, and other properties of the data |
| Technical System Needs | Does not specify technical system needs |
| Use in Procedural Contexts | Valuable in procedural or data-oriented projects like Data Warehouse design or reporting systems |
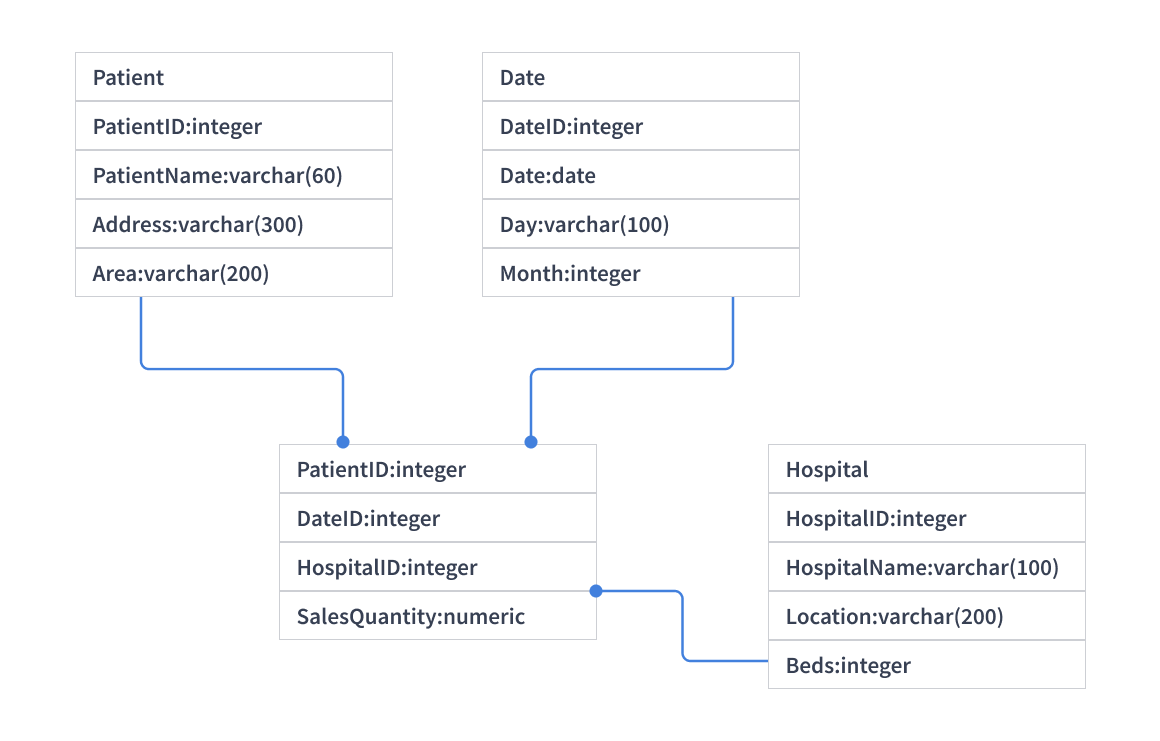
Physical Data Model
Physical Data Model is the last one in the types of Data models.
| ASPECT | DESCRIPTION |
| Abstraction Level | The least abstract defines the physical format in which data will be stored. |
| Purpose | Provides a finished design that can be implemented as a Relational Database |
| Associative Tables | Includes associative tables showing relationships between entities |
| Implementation | Directly related to the structure used in the Database Management System (DBMS) |
| Keys | Utilizes primary keys and foreign keys to maintain relationships |
Data Modeling Process
Data Modeling as a discipline invites stakeholders to examine Data processing and storage in great depth. Different conventions govern which symbols are used to represent data, how models are built up, and how business needs are communicated in Data Modeling methodologies. All approaches provide structured workflows that comprise a list of actions that must be completed in sequential order. An example of a workflow is shown below:
- Identify Entities: Find the items, events, or concepts within a dataset. Each item has to be unique but associated with another.
- Identify Attributes: Decide on fundamental features (attributes) of each object, for instance, a “customer” has a name and phone number, whereas an “address” contains street and city details.
- Specify Associations: Define the manner in which entities are interconnected, that is, a customer “lives” at an address.
- Map Attributes to Objects: The model should reflect exactly how the business interacts with its data.
- Assign Keys and Normalize: Use keys to relate entities without replicating information and ensure that normalization neither provides a defeat nor does it bring performance problems.
- Update and test: The model should be regularly updated and tested according to the ever-changing needs of a business.
This workflow always ensures data management is approached in a structured way.
Discover how conceptual, logical, and physical data models contribute to effective database design in our in-depth guide
Benefits of Data Modeling
Developers, Data Architects, Business Analysts, and other stakeholders can examine and comprehend relationships among data in a Database or Data warehouse using Data Modeling. Furthermore, it has the ability to:
- Reduce software and database development errors.
- Increase enterprise-wide consistency in documentation and system architecture.
- Enhance the performance of your application and database.
- Streamline Data mapping across the organization.
- Improve communication between the development and Business Intelligence teams.
- Make database design easier and faster at the conceptual, logical, and physical levels.
Data Modeling Tools
Today, a variety of commercial and free source Computer-Aided Software Engineering (CASE) solutions, including Data modeling, diagramming, and visualization tools, are extensively utilized. Following are a few examples:
- Erwin Data Modeler is a Data Modelling tool that supports alternative notation approaches, including a dimensional approach, and is based on the Integration DEFinition for information modeling (IDEF1X) Data modeling language.
- Enterprise Architect is a visual modeling and design tool for enterprise information systems, architectures, software applications, and databases. It is built on the foundation of object-oriented languages and standards.
- ER/Studio is a database design software that works with several common database management systems today. Both relational and dimensional data models are supported.
- Open Source Solutions like Open ModelSphere are examples of free Data modeling tools.
Learn more about:
- MongoDB Schema Designer
- UML Database Modeling
- Streamline your data with a product information management data model. Discover how it can enhance your data organization and accuracy.
- Understanding the Data Reference Model
- Best Strategies to Create & Maintain A High Level Data Model
Conclusion
As a software developer or Data Architect, creating Data models will be beneficial. Knowing when to employ the appropriate data model and how to include business stakeholders in the decision-making process can be quite beneficial. In this article, you learned about the different types of Data Models and the Data Modeling process.
Hevo Data will automate your data transfer process, hence allowing you to focus on other aspects of your business like Analytics, Customer Management, etc. This platform allows you to transfer data from 150+ multiple sources to Cloud-based Data Warehouses like Snowflake, Google BigQuery, Amazon Redshift, etc. It will provide you with a hassle-free experience and make your work life much easier.
Want to take Hevo for a spin? Get a 14-day free trial and experience the feature-rich Hevo suite firsthand.
You can also have a look at our unbeatable pricing that will help you choose the right plan for your business needs!

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



