

Apache Airflow is a powerful and widely used open-source Workflow Management System (WMS) that can author, schedule, orchestrate, and monitor data pipelines and workflows programmatically. Airflow allows you to manage your data pipelines by authoring workflows as task-based Directed Acyclic Graphs (DAGs).
Apache Airflow streams data? NO, it is not a streaming solution. Tasks do not transfer data from one to the other (though they can exchange metadata!). Airflow is not in the same league as Spark Streaming or Storm but is more akin to Oozie or Azkaban.
There is no notion of data input or output – only flow. You manage task scheduling as code and can visualize the dependencies, progress, logs, code, trigger tasks, and success status of your data pipelines.
Apache Airflow, which is written in Python, is becoming increasingly popular, particularly among developers, due to its emphasis on configuration as code. Proponents of Airflow believe it is distributed, scalable, flexible, and well-suited to handling the orchestration of complex business logic.
In this article, you’ll come to know how Apache Airflow streams data and learn ideal use cases for Airflow and its features respectively.
Table of Contents
Prerequisites
- Data Pipeline Basics
What is Apache Airflow?

Apache Airflow is a batch-oriented, pipeline-building open-source framework for developing and monitoring data workflows. Airbnb created Airflow in 2014 to solve big data and complex Data Pipeline problems. They wrote and scheduled processes, as well as monitored workflow execution, using a built-in web interface. The Apache Software Foundation adopted the Airflow project due to its growing success.
Another important feature of Airflow is its backfilling capability, which allows users to easily reprocess previous data. Users can also use this feature to recompute any dataset after modifying the code. In practice, Airflow can be compared to a spider in a web: it sits at the heart of your data processes, coordinating work across multiple distributed systems.
Tired of dealing with Airflow’s complex DAG management and parallelism issues? Simplify your data pipeline with Hevo’s automated ETL platform. Hevo handles concurrent data processing effortlessly, freeing you from the hassle of managing parallel workflows.
Why Consider Hevo
- No-Code Setup: Easily configure data pipelines without writing any code.
- Real-Time Sync: Enjoy continuous data updates for accurate analysis.
- Reliable & Scalable: Handle growing data volumes with Hevo’s robust infrastructure.
Experience smooth scalability and streamlined data operations—no Airflow headaches required.
Get Started with Hevo for FreeKey Features of Apache Airflow
- Dynamic: Airflow pipelines are coded (Python), allowing for dynamic pipeline generation. This enables the creation of code that dynamically instantiates pipelines.
- Extensible: You can easily define your operators and executors, and you can extend the library to fit the level of abstraction that best suits your environment.
- Elegant: Airflow pipelines are short and to the point. The powerful Jinja templating engine is used to parameterize your scripts, which is built into the core of Airflow.
- Scalable: Airflow has a modular architecture and orchestrates an arbitrary number of workers using a message queue. The airflow is ready to expand indefinitely.
You can check out how Airflow ETL works to get a better idea of how Apache Airflow functions.
How Apache Airflow Streams Data?
Apache Airflow is a platform for programmatically authoring, scheduling, and monitoring workflows via DAGs ( Directed Acyclic Graphs ). In other words, an Airflow is a tool that allows you to automate simple and complex processes through the use of a rich UI interface that can execute them regularly.
Apache Airflow Workflows with directional dependencies are known as Directed Acyclic Graphs. In the figure below, for example, we can see that Task 3 is dependent on Task 2, which is dependent on two tasks, Task 1. a and Task 1. b. This is referred to as a workflow, and Airflow represents workflows using DAGs.
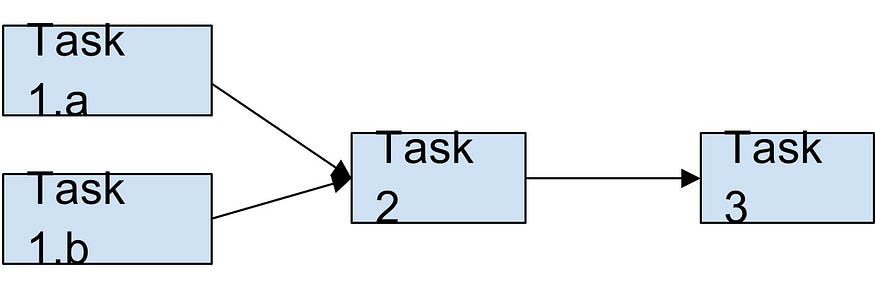
Apache Airflow streams data in a horizontally scalable, distributed workflow management system that enables teams and developers to define complex workflows in Python code. The Airflow scheduler executes your tasks on an array of workers while adhering to the dependencies you specify.
When is it Appropriate to use Apache Airflow Streaming?
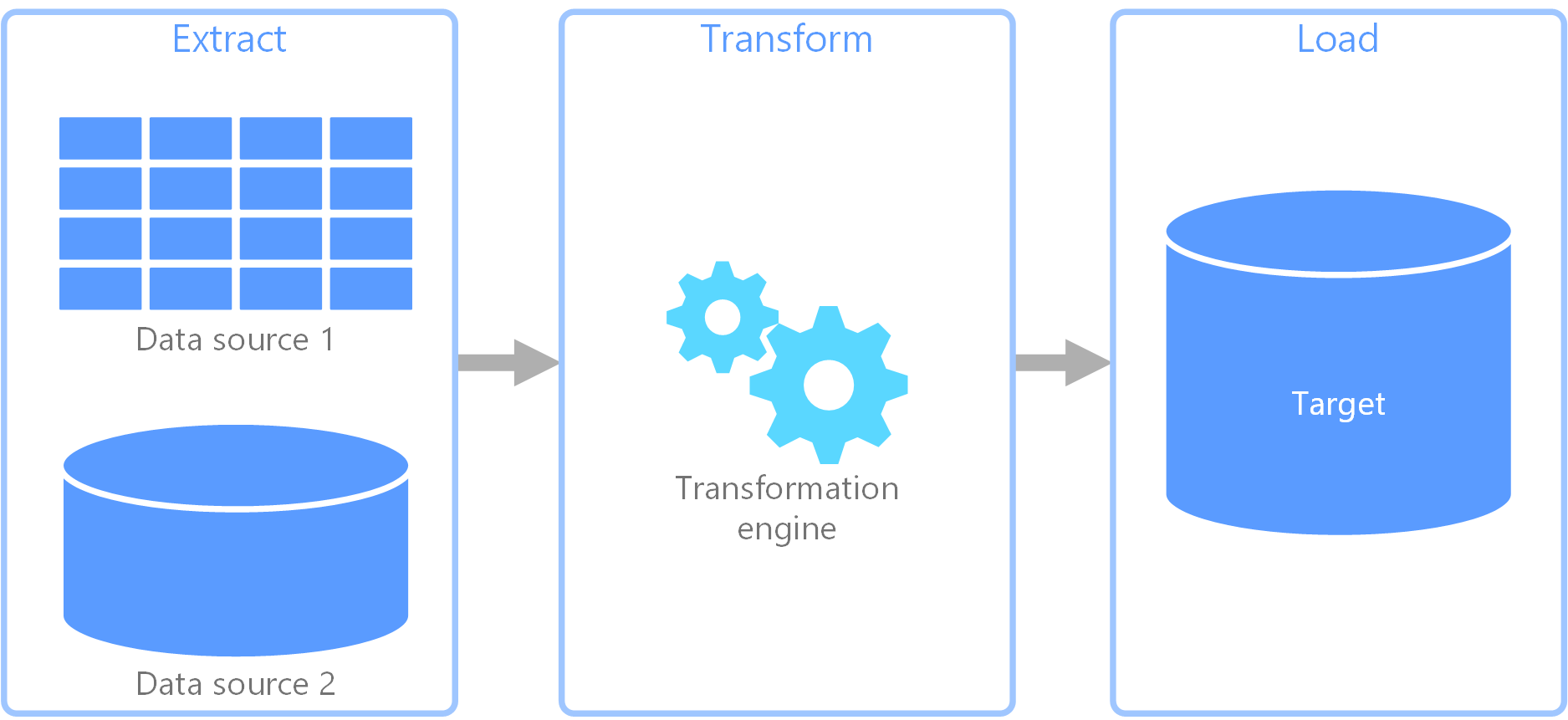
Data Pipelines are becoming more complex as data is pulled in from various sources at different stages of the pipeline. Workflow management systems, such as Apache Airflow, make the job of the data engineer easier by automating tasks.
Apache Airflow enables easy monitoring and failure handling to keep track of the dependency of a live intelligent system assisting in the data-productionization. pipeline’s
Furthermore, Apache Airflow allows for simple integration with Jupyter notebooks, as well as easy parameterization using tools such as paper mill, which aids in hyperparameter testing for a model. Airflow can use Canary testing to ensure that new models are superior to older models, which is useful in the productionization of ML models.

Creating Apache Airflow Streaming Data Pipelines
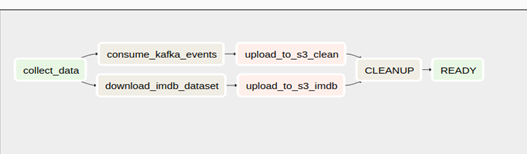
To keep things simple, we’ll use a sequential data pipeline. Within our DAG, we have the following components for Apache Airflow:
Airflow Streaming Step 1: Use a BashOperator to run an external Python script that consumes the Kafka stream and dumps it to a specified location.
Airflow Streaming Step 2: Using the cURL command and a BashOperator, download the IMDB dataset to a specified location.
Airflow Streaming Step 3: Run a data cleaning procedure. Python function that reads these files and converts them to the required format using a PythonOperator.
Airflow Streaming Step 4: Using a PythonOperator, upload the processed training data to an S3 bucket.
Airflow Streaming Step 5: Clean up the raw and processed data with a BashOperator and a bash command

Pitfalls of Airflow Streaming
- The Execution date is a strict time requirement for Apache Airflow. No DAG can run in the absence of an execution date, and no DAG can run twice for the same execution date.
- The Scheduler handles scheduled jobs and backfill jobs separately. This can lead to strange results, such as backfills failing to respect a DAG’s max active runs configuration.
- If you want to change the schedule, you must rename your DAG. Because the previous task instances will no longer correspond to the new interval.
- It is not simple to run Apache Airflow natively on Windows. However, by utilizing Docker, this can be mitigated.
Use Cases of Airflow Streams
- Real-Time Data Processing: Automate workflows for streaming data from IoT devices, logs, or social media.
- ETL Pipelines: Process, transform, and load streaming data into data warehouses or lakes.
- Event-Driven Workflows: Trigger tasks based on real-time events, like user actions or system updates.
- Data Monitoring: Track and respond to anomalies or trends in live data streams.
- Machine Learning: Train models with continuously updated data for real-time predictions.
Also, take a look at the key differences between Apache Kafka vs Airflow to get a comprehensive understanding of the two platforms.
Conclusion
In this article, you learned how Apache Airflow streams data and the best use cases for Airflow and its features. Apache Airflow’s strong Python framework foundation enables users to easily schedule and run any complex Data Pipelines at regular intervals. Data Pipelines, represented as DAG, is critical in Airflow for creating flexible workflows.
The rich web interface of Airflow allows you to easily monitor the results of pipeline runs and debug any failures that occur. Many companies have benefited from Apache Airflow today because of its dynamic nature and flexibility.
Companies need to analyze their business data stored in multiple data sources. The data needs to be loaded to the Data Warehouse to get a holistic view of the data. Hevo Data is a No-code Data Pipeline solution that helps to transfer data from 150+ sources to desired Data Warehouse. It fully automates the process of transforming and transferring data to a destination without writing a single line of code.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. Can Airflow be used for streaming?
Airflow is primarily designed for batch processing and is not ideal for real-time streaming workflows. It’s better suited for orchestrating periodic tasks rather than handling continuous data streams.
2. What is the difference between Airflow and StreamSets?
Airflow is a workflow orchestration tool for batch processing, while StreamSets is a data integration platform designed for real-time streaming and batch data flows. StreamSets offers more capabilities for handling real-time data streams compared to Airflow.
3. What are the 4 principles of Apache Airflow?
Dynamic Pipelines: Pipelines are defined in Python code, offering flexibility and control.
Extensible: Easily extendable with custom plugins and operators.
Scalable: Capable of scaling out to manage large workloads.
Modular: Components like workers, schedulers, and the web server are modular, allowing for flexible deployment.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





