



One of the most common things in data analytics is running the same analytics queries over and over again by different end users over various times and snapshots of the data. This action, in particular, makes running warehousing solutions expensive and time-consuming at the same time.
How about, we store the results of such expensive queries and make them readily available for us, without having to run the query over the raw data whenever it is needed? This is exactly what Materialized Views in BigQuery does for us. BigQuery serves the pre-computed results, leading to faster performance and reduced query costs. You must generally use it for recurring queries with minimal changes to the underlying data.
In this blog, let’s dive deep into the complexities of Materialized Views in BigQuery to better understand them and determine when and when not to use them.
Table of Contents
What is BigQuery Materialized View?
Every database has a feature known as Views, which are saved queries. A query that is run every time it is called. But this gets expensive if the saved query or say the definition of the view is complex and needs a lot of time and database resources to run. Thus, as the name suggests, a Materialized View in BigQuery materializes the data behind its definition. Unlike regular views, which execute their underlying SQL logic every time you query them, materialized views store the results in BigQuery’s storage layer. Thus, this approach reduces computational overhead and improves performance.
Key Characteristics of Materialized Views
- Incremental Updates: Only the data that has changed since the last computation is refreshed, making updates efficient.
- Performance Boost: Queries on materialized views are significantly faster as they read precomputed results.
- Cost-Effective: Since materialized views reduce the need for repetitive computations, they lower query costs.
- Read-Optimized: Ideal for dashboards or applications requiring low-latency results.
Facing challenges migrating your data to BigQuery? Migrating your data can become seamless with Hevo’s no-code intuitive platform. With Hevo, you can:
- Automate Data Extraction: Effortlessly pull data from 150+ connectors(and other 60+ free sources).
- Transform Data effortlessly: Use Hevo’s drag-and-drop feature to transform data with just a few clicks.
- Seamless Data Loading: Quickly load your transformed data into your desired destinations, such as BigQuery.
Try Hevo and join a growing community of 2000+ data professionals who rely on us for seamless and efficient migrations.
Get Started with Hevo for FreeExamples of Materialized Views in BigQuery
Let us take a look at where we can use Materialised views to enhance our analytics workload, with industry-based examples and use cases.
Scenario 1: E-Commerce Sales Insights
Base Table definition:
- Sales Table
| # | Column Name | Column Type |
| 1. | product_id | STRING (UUID) |
| 2. | category | STRING |
| 3. | sales_amount | FLOAT/DOUBLE |
| 4. | sale_date | DATE |
Usual Query without Materialized Views:
SELECT
category,
SUM(sales_amount) AS total_sales,
COUNT(product_id) AS items_sold
FROM
sales_data
GROUP BY
category; Let us change it into a Materialized view:
CREATE MATERIALIZED VIEW mv_sales_by_category AS
SELECT
category,
SUM(sales_amount) AS total_sales,
COUNT(product_id) AS items_sold
FROM
sales_data
GROUP BY
category; Query using Materialized View:
SELECT category, total_sales
FROM mv_sales_by_category
WHERE category = 'Electronics'; Scenario 2: Tracking Marketing Campaign Performance
Base tables definition:
- Campaigns Table
| # | Column Name | Column Type |
| 1 | campaign_id | STRING |
| 2 | campaign_name | STRING |
| 3 | start_date | DATE |
| 4 | end_date | DATE |
| 5 | budget | FLOAT/DOUBLE |
- Impressions Table
| # | Column Name | Column Type |
| 1 | campaign_id | STRING |
| 2. | impression_date | DATE |
| 3. | impressions_count | INT |
- Clicks Table
| # | Column Name | Column Type |
| 1. | campaign_id | STRING |
| 2. | click_date | DATE |
| 3. | click_count | INT |
| 4. | revenue_generated | FLOAT/DOUBLE |
Usual Query without Materialized Views:
SELECT
c.campaign_id,
c.campaign_name,
SUM(i.impressions_count) AS total_impressions,
SUM(cl.clicks_count) AS total_clicks,
SUM(cl.revenue_generated) AS total_revenue,
SUM(cl.revenue_generated) / c.budget AS roi,
SUM(cl.clicks_count) / NULLIF(SUM(i.impressions_count), 0) AS ctr
FROM
campaigns c
LEFT JOIN
impressions i
ON
c.campaign_id = i.campaign_id
LEFT JOIN
clicks cl
ON
c.campaign_id = cl.campaign_id
WHERE
i.impression_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
AND cl.click_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
GROUP BY
c.campaign_id, c.campaign_name, c.budget; Let us now create the Materialized view to precompute and store the results in BigQuery.
CREATE MATERIALIZED VIEW mv_campaign_performance AS
SELECT
c.campaign_id,
c.campaign_name,
SUM(i.impressions_count) AS total_impressions,
SUM(cl.clicks_count) AS total_clicks,
SUM(cl.revenue_generated) AS total_revenue,
SUM(cl.revenue_generated) / c.budget AS roi,
SUM(cl.clicks_count) / NULLIF(SUM(i.impressions_count), 0) AS ctr,
MAX(i.impression_date) AS last_impression_date,
MAX(cl.click_date) AS last_click_date
FROM
campaigns c
LEFT JOIN
impressions i
ON
c.campaign_id = i.campaign_id
LEFT JOIN
clicks cl
ON
c.campaign_id = cl.campaign_id
GROUP BY
c.campaign_id, c.campaign_name, c.budget; Optimized Query using Materialized Views:
SELECT
campaign_name, total_impressions, total_clicks, total_revenue, roi, ctr
FROM
mv_campaign_performance
WHERE
roi > 1.5
AND total_impressions > 100000
AND last_impression_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY); Prerequisites for Using Materialized View in BigQuery
Before you can use this powerful feature, you need to make sure you fulfill the following pre-requisites:
- Google Cloud Account
- IAM Permissions
- bigquery.tables.create
- bigquery.dataEditor
- bigquery.dataOwner
- bigquery.admin
- Basic SQL Knowledge like DDL, DML, and aggregations queries.
- Understand the nuances of Materialized View Query Structure and working mechanism
You can take a look at how you can get started with the BigQuery Create View command to get a better understanding of working with views in BigQuery.
How to Create BigQuery Materialized Views?
Now that you are aware of the prerequisites and the powerful features of BigQuery Materialized views. Lets us dive into step by step guide on how you can create and use a Materialized views in Google Cloud.
Step 1: Access the Google Cloud Console
Go to the Google Cloud Console and sign in with your Google account. Do create a new account if you don’t have already.
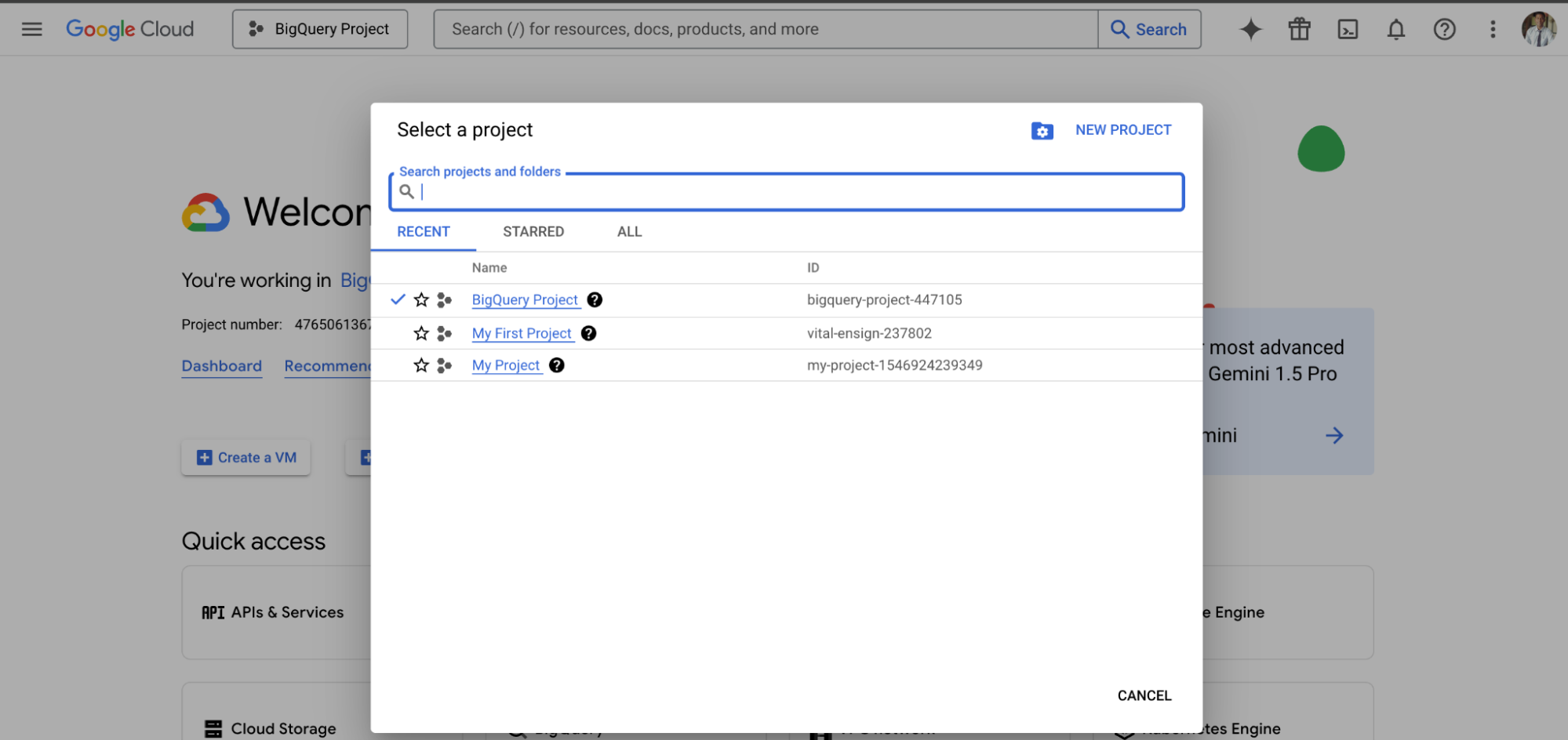
Step 2: Select Your Project
Once you are logged in, click on the project dropdown in the top navigation bar and select the project where you want to create the materialized view.
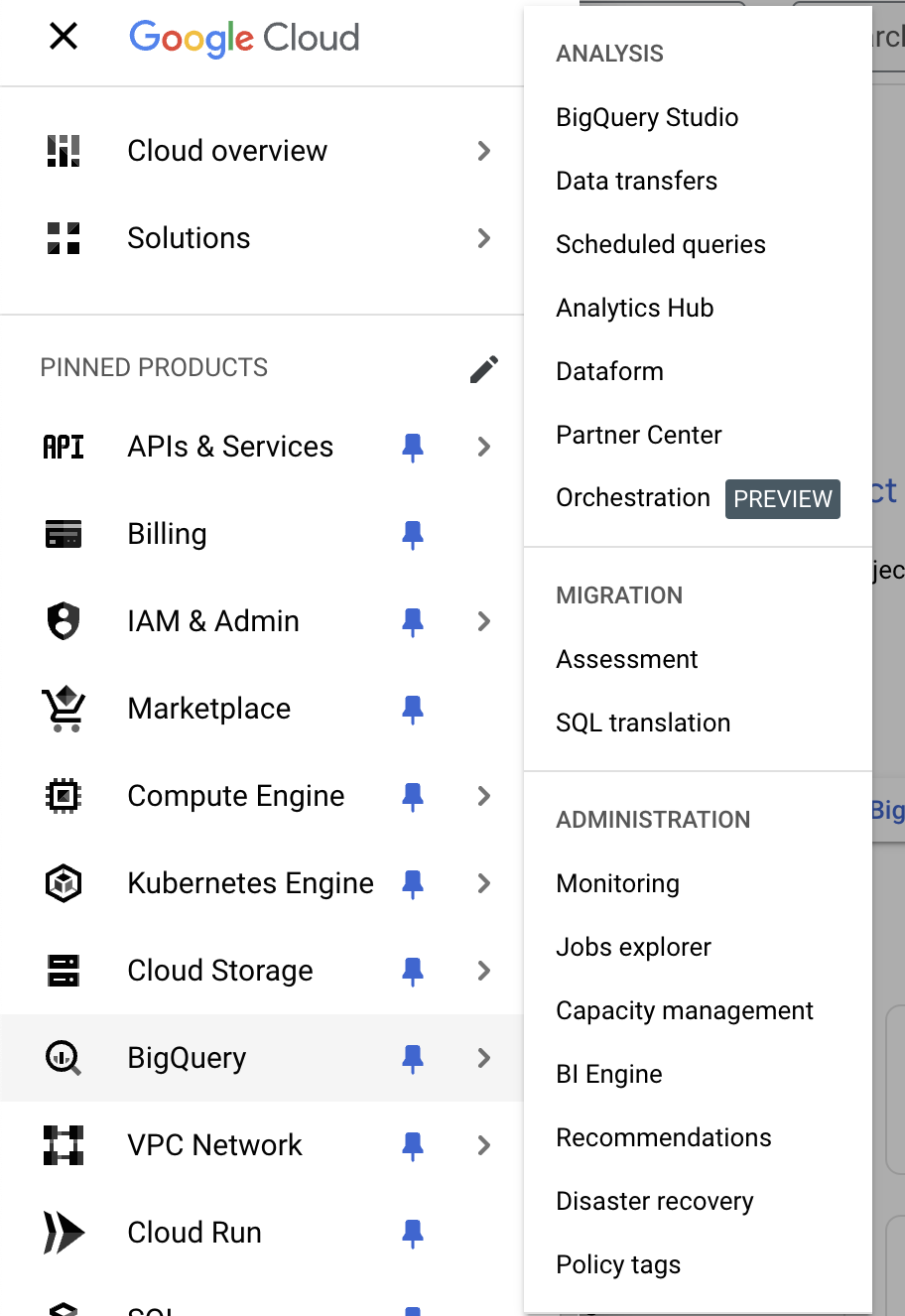
Step 3: Navigate to BigQuery
Once you’re in the project you want to work on, in the left sidebar, scroll down and click on BigQuery. This will open the BigQuery console.
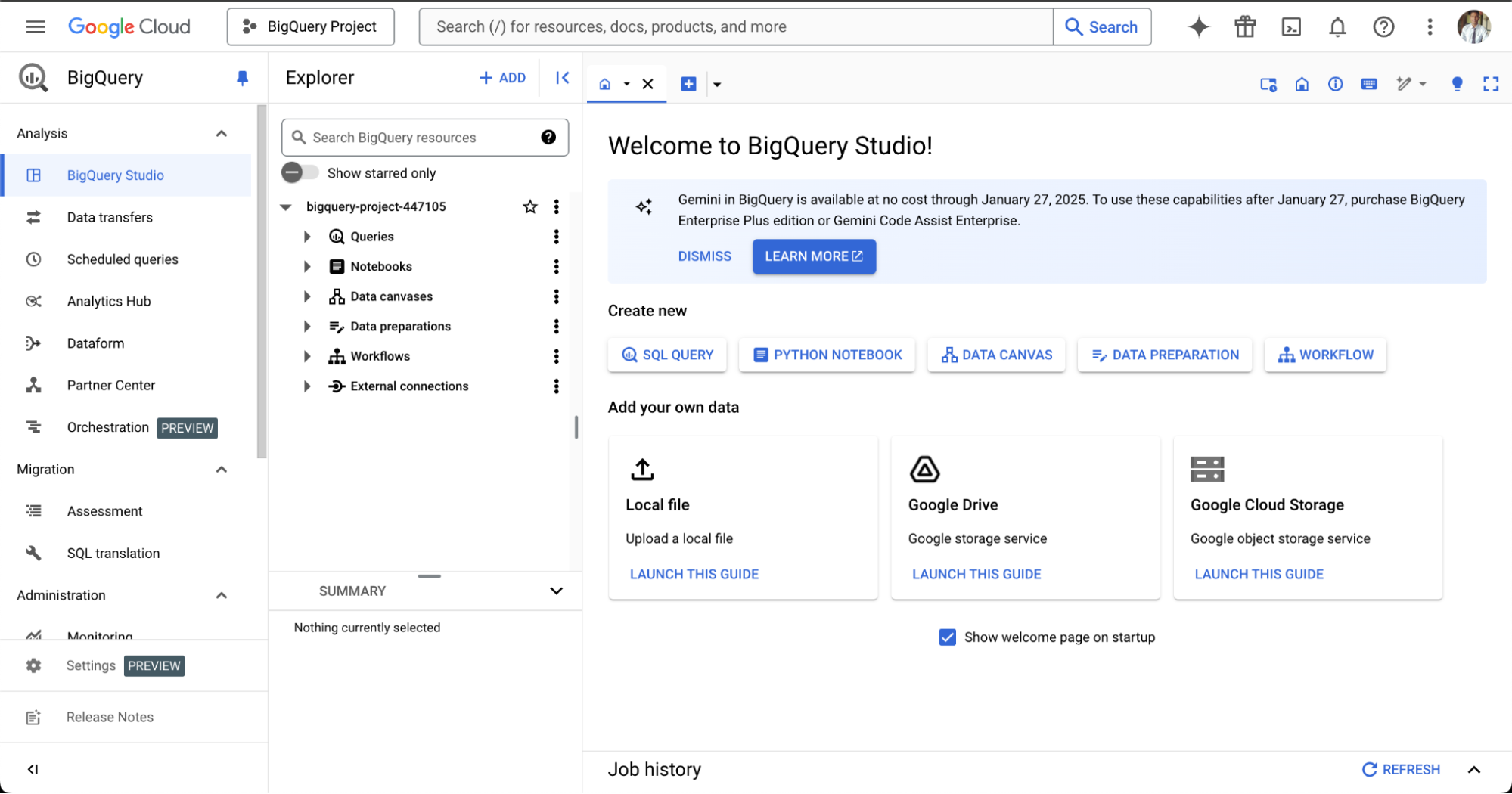
You should be able to see, the BigQuery console like this:
Step 4: Locate Your Dataset
In the Explorer panel, find the dataset where you would like to create the materialized view.
Or you can click on the +ADD button to create/add a new dataset to work on.
Step 5: Define Your Base Query
Let us now define a base query, the SQL query that will serve as the basis for your materialized view. This query can include various transformations, filters, and aggregations.
Example Base Query:
SELECT
c.customer_id,
c.customer_name,
SUM(oi.quantity * oi.price) AS total_sales,
COUNT(DISTINCT o.order_id) AS total_orders
FROM
`bigquery_dataset.customers` AS c
JOIN
`bigquery_dataset.orders` AS o ON c.customer_id = o.customer_id
JOIN
`bigquery_dataset.order_items` AS oi ON o.order_id = oi.order_id
GROUP BY
c.customer_id, c.customer_name;Step 6: Use the Base Query To Create a Materialized View
Click on the SQL Query button from the Create New Section of the console.
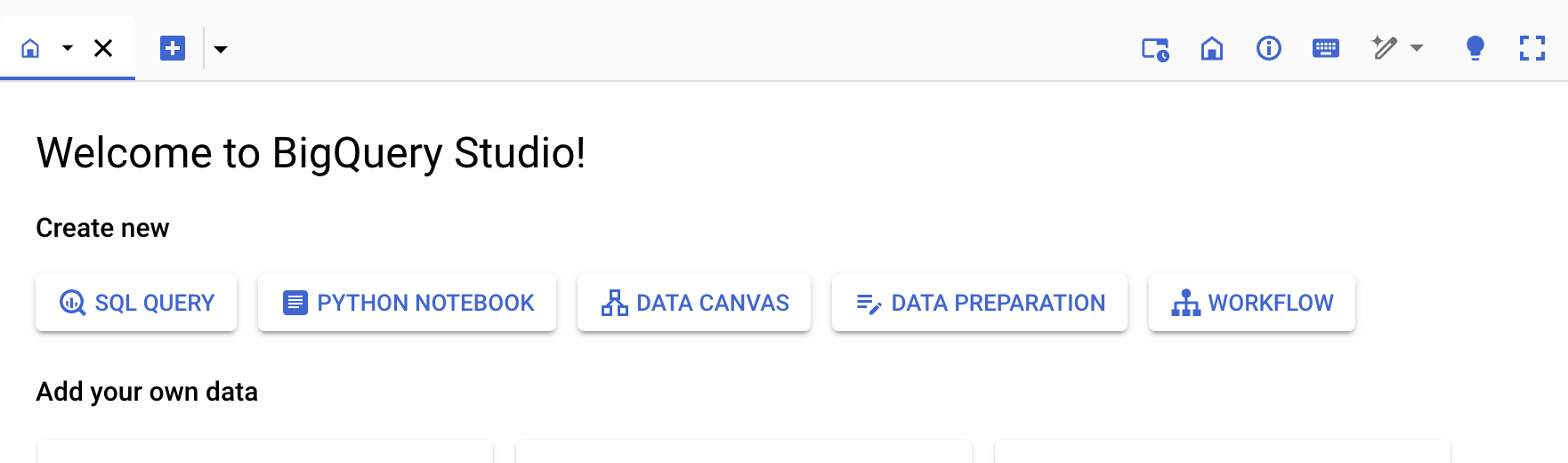
Run the Materialized view query to create.
Example:
CREATE MATERIALIZED VIEW `bigqueryproject.bigquery_dataset.sales_summary_mv` AS
SELECT
c.customer_id,
c.customer_name,
SUM(oi.quantity * oi.price) AS total_sales,
COUNT(DISTINCT o.order_id) AS total_orders
FROM
`bigquery_dataset.customers` AS c
JOIN
`bigquery_dataset.orders` AS o ON c.customer_id = o.customer_id
JOIN
`bigquery_dataset.order_items` AS oi ON o.order_id = oi.order_id
GROUP BY
c.customer_id, c.customer_name;Step 7: Query Materialized view
Once you run the above query you can now use the created materialized view to query the underlying data by using the query below:
SELECT
customer_name,
total_sales,
total_orders
FROM
`bigqueryproject.bigquery_dataset.sales_summary_mv`
WHERE
total_sales > 1000;Use Case of Materialized Views
There are various use cases in which engineers use the materialized view. Let us discuss a few use cases where it is used the most.
- Pre-Aggregating Data: Instead of aggregating data every time it is required, materialized views cache aggregated data for future use.
Scenario: Calculate daily sales totals from a streaming sales dataset. - Pre-Filtering Data: Materialized views are generally used to store a frequently requested subset of a table’s data based on filtering techniques.
Scenario: Filter transactions for a specific product category. - Pre-Joining Data: SQL joins are very expensive as they require a shuffle of data, thus materialized views are used to store pre-joined datasets to optimize performance.
Scenario: Joining customer information and transaction data for quick access to the complete picture. - Pre-Clustering Data: Materialized views can reorganize data using a clustering strategy better suited for specific query patterns.
Scenario: Speed up time-series analysis of web server logs.
Limitations of Materialized Views
Materialized Views is a powerful tool, however, it does come with some limitations. Let us now look at some limitations that we need to consider while working with it.
- Storage Costs: Materialized Views store the cached data, and thus incur cost based on the size of cached data.
- Limited Flexibility: You will have to re-create and run the entire view if the underlying query logic changes at some point.
- Update Overhead: Frequent changes to source tables can lead to higher refresh costs.
- Query Constraints: Materialized views cannot reference other views or temporary tables.
You can also take a look how you can easily work with Databricks Materialized Views and Snowflake Materialized Views if you are looking for alternatives of BigQuery.
Conclusion
To summarize, Materialized Views in BigQuery is a very powerful tool for optimizing query performance and reducing costs in scenarios that involve repeated queries. From precomputing results to leveraging incremental updates, they provide a seamless experience for data analysts and engineers.
However, they come with their own set of limitations and best-use cases, making it essential to evaluate your specific needs before implementation.
If you want to integrate your data from various sources and load it in Google BigQuery, then try Hevo.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions (FAQs)
1. What is the difference between a view and a materialized view in BigQuery?
A view executes its query every time it’s accessed, fetching live data. However, a materialized view stores pre-computed results, making repeated queries faster and more cost-effective.
2. Why use a materialized view instead of a table?
Materialized views are updated incrementally, reducing the overhead of managing a table manually. Thus, making it ideal for precomputing frequently queried data.
3. What is the difference between a scheduled query and a materialized view?
A scheduled query runs periodically, storing results in a table—however, a materialized view updates automatically when the underlying data changes and serves pre-computed results.
4. What is the difference between a materialized view and a normal view?
A Materialized view stores results physically in storage. However, a Normal view only stores the query logic and computes results on demand.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





