

In this information age, there has been explosive growth in the rate and type of data generated daily. From mobile devices and IoT sensors to our online content, unprecedented amounts of data are generated.
Traditional databases and warehouse technologies cannot handle this data volume and variety burst. This led to the rise of data lakes and the more recent practice of data lakehouses for modern data architecture.
In this blog, we will get acquainted with what data lakes are.
Table of Contents
What are Data Lakes?
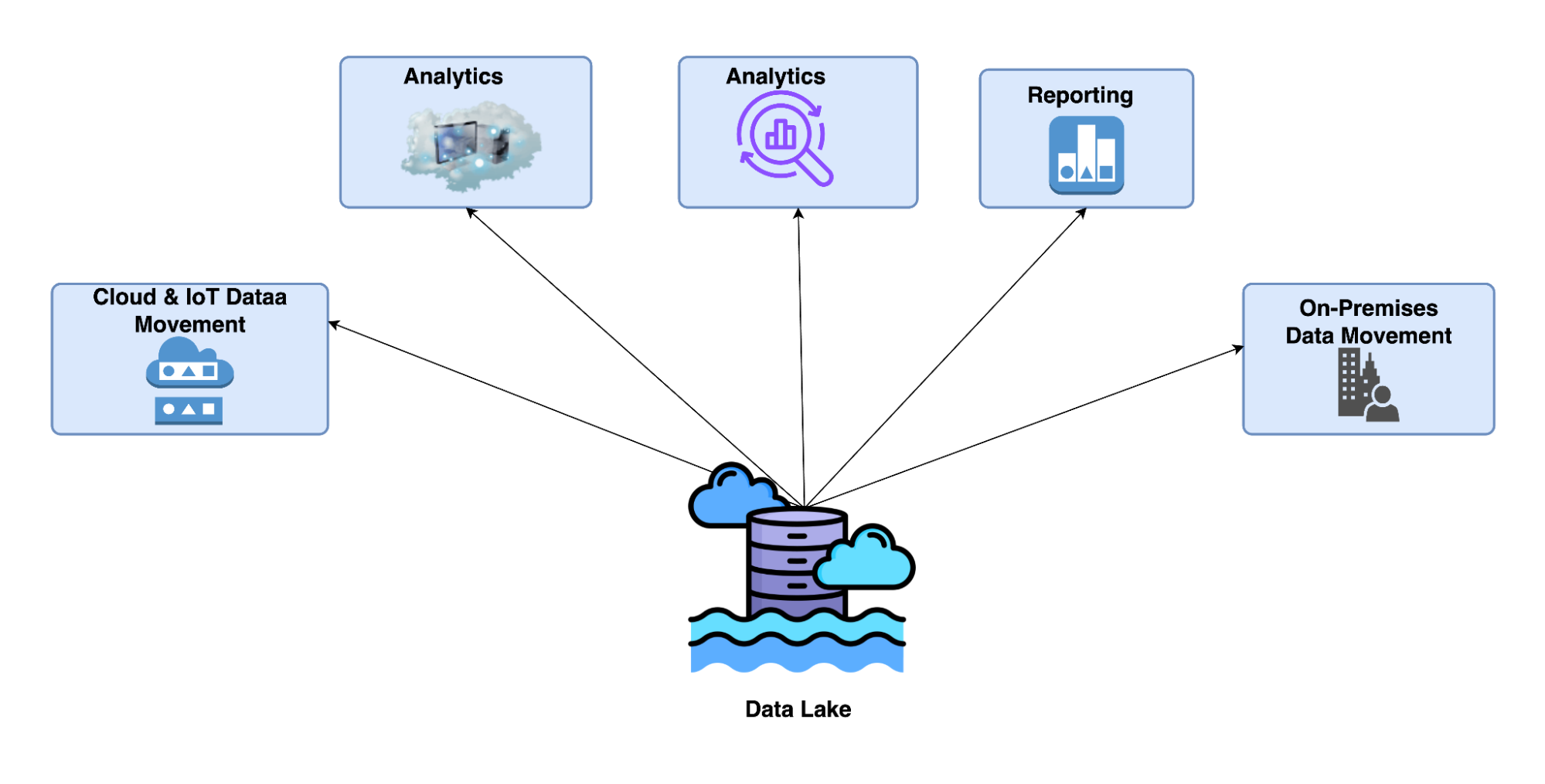
A data lake is a centralized data repository designed to store a massive amount of raw data in its native format, either structured, semi-structured, or unstructured.
By centralizing the storage layer of the data architecture, it breaks down the data silos, allowing stakeholders for easier data integration and access across the organizational needs.
They are now a common playground for data scientists, analysts, and engineers to wrangle around the data and collaborate more effectively. It can handle real-time data streams and batch processing, catering to various analytical needs and accelerating time-to-insights for any business.
Hevo Data, a No-code Data Pipeline helps to load data from any data source such as Salesforce, Databases, SaaS applications, Cloud Storage, SDKs, and Streaming Services and simplifies the ETL process.
Why choose Hevo?
- Supports 150+ data sources (including 60+ free data sources)
- Hevo has a fault-tolerant architecture that ensures zero data loss.
- Provides 24/5 live chat support.
Explore why POSTMAN chose Hevo over other data pipelines for easy data ingestion pipeline creation and robust Role-Based Access Control (RBAC).
Get Started with Hevo for FreeImportance of Data Lakes in Modern Data Architecture
Unlike traditional databases, a data lake’s storage and compute layers are separate entities and can be scaled independently. As a result, it is best suited for a long-term data archiving solution with regulatory and compliance in check. Discussed below are some reasons why data lakes play an important role in modern data architecture:
- Cost-Effective and Scalability: Data lakes are built on top of cost-efficient cloud services like AWS S3 and Azure blob storage. Virtually, they can scale to infinity. In simpler terms, there is virtually no limit to the amount of data you can store in a data lake, as the storage can scale up to exabytes of data.
- Flexibility: Organizations can have various data sources generating multiple varieties of data. They can handle data in multiple formats, including but not limited to text, images, videos, binary sensor data, etc.
- Data Integration & Advanced Analytics: The Data Lake democratizes data access and experimentation across the organization. A wide range of data connectors are available as sinks or sources. Upstream applications and end users across the organization can run analytics and machine learning workloads on diverse datasets.
Components of a Data Lake
Data Lake has several components that work together to store, manage, and analyze vast volumes of diverse data. Some of the significant elements of a data lake are:
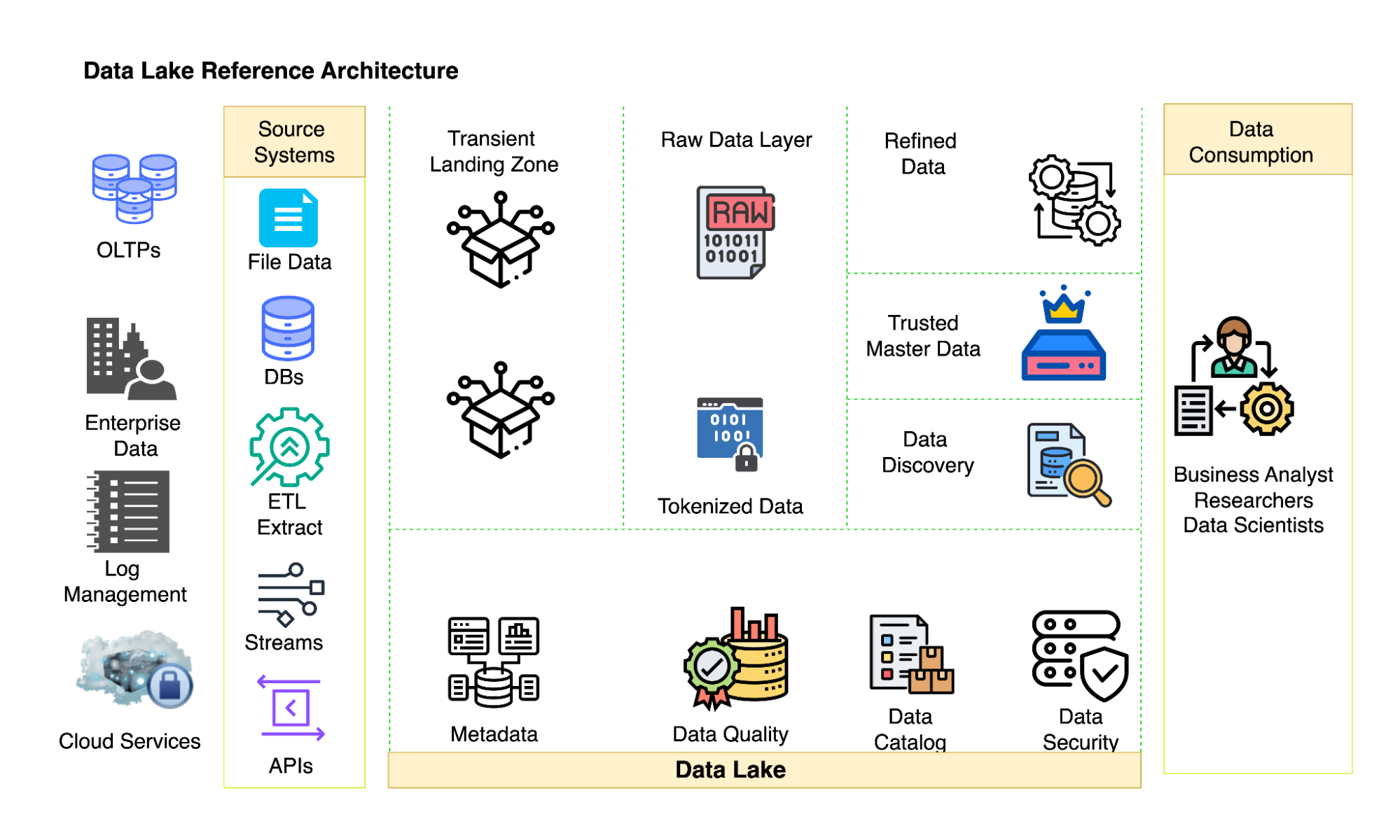
1. Data Lake Integration & Ingestion
Organizations have many data sources, including multiple OLTP databases, SaaS Applications, IoT devices, etc. Data Engineers use multiple integration mechanisms and connectors to integrate the data sources into the central data repository.
Depending on the business needs, data can be ingested in seconds (real-time/near real-time) or in a matter of hours/days (batch-ingestion).
Apache Kafka, Apache NiFi, AWS Kinesis, Azure Event Hubs, and Google Pub/Sub are some of the famous and widely used tools for data ingestion.
2. Storage
If the entire organization’s data must be stored in one central location, we can imagine how big that would be.
Data lake storage layers are designed to house exabytes of data in their raw, native format. It is infinitely scalable and cost-effective. Extremely famous cloud-based solutions for storing data in lakes are Hadoop Distributed File System, or HDFS; Amazon S3; Azure Blob Storage, or ADLS; etc.
4. Cataloging & Metadata management
A data lake captures details about the data, such as its location, schema, format, etc., in the form of metadata using technologies like Hive Metastore. Metadata management in Data Lakes helps users understand the data’s context, quality, and lineage in their data lakes.
A Data Catalog is a collection of metadata. In simpler terms, it is an organized inventory of all your data assets. The Data Catalog is the core of a data lake, making it more discoverable and understandable.
Apache Atlas, AWS Glue Data Catalog, Azure Data Catalog, etc., are some metadata management tools that offer a searchable/queryable interface, data lineage tracking, and data quality metrics, ensuring stakeholders can efficiently find and understand the data they need.
5. Processing & Transformation
Business use cases sometimes require data to be transformed into a format different from the native format in the data lake. Thus, the data processing component of the lakes needs to support various processing paradigms, including batch processing, micro-batching, and real-time data processing.
Apache Spark, Hadoop MapReduce, AWS Glue, Azure Data Factory, etc., are generally used for batch processing extensive datasets. On the other hand, Apache Kafka Stream, Apache Flink, Amazon Kinesis, etc., are used for real-time data processing.
6. Security & Access Control
As the data from across the organization and verticals are stored in the central data repository, data lake, security, and access control should be the top priority to ensure compliance with the organization’s regulations.
7. Compliance & Governance
Data governance is a set of practices, policies, and strategies that ensure the proper management of data within a data lake. It enforces data quality standards and ensures that the data in the lake remains accurate, complete, and reliable.
As the data transforms from one format to another, it keeps track of lineage and maintains traceability. It adheres to industry-specific standards and regulatory requirements such as GDPR, HIPAA, etc.
8. Data Delivery
The data lake is a center of data experimentation and innovation and provides data for various purposes, including reporting, analytics, and machine learning. It provides an interface that enables different stakeholders to interact with the data according to their needs and capabilities using tools like Apache Hive, Presto, Amazon Athena, Azure SQL Warehouse, etc., over a SQL Query, BI Tools like Tableau, PowerBI, and Looker Studio for reporting, and tools like Tensorflow, Databricks, and AWS Sagemaker for Machine Learning workload.
Challenges of a Data Lake:
A Data Lake must seem fascinating and full of wonders till now, but as with every technology, the adoption of a data lake in our data architecture comes with various challenges; let’s discuss some of them in brief:
- Complex Data Integration
Integrating data from diverse sources (structured, semi-structured, unstructured) into the data lake requires robust ETL (Extract, Transform, Load) processes. In addition, when a pipeline needs real-time data integration, it can bring in a more significant challenge of consistency and maintaining data quality.
- Pipeline Orchestration
Data lakes are an aggregated concept of multiple components working together to move data through different stages. Some stages function independently, while others are dependent on the other. Thus, orchestrating each stage while keeping dependency, reliability, scalability, and fault tolerance in check presents a more significant challenge.
- Inconsistent Data Quality
Aggregating data from different sources, with other formats, schemas, and quality standards, into one big data lake creates inconsistency in managing a common validation and cleansing process and ensuring data quality.
- Query Performance
Query processing time is directly proportional to the amount of data the query is run over. Optimizing query performance across the larger data sets in the data lake is thus often addressed using partitioning, indexing, and appropriate storage formats.
- Data Security
With a centralized data lake, having all the data across the organization, including every critical and sensitive business data, in one plane brings a challenge in maintaining reliable security practices against unauthorized access, data breaches, and critical data malfunction. Some industries have particular data regulatory and security compliance (e.g., GDPR, HIPAA), which adds to the complexity of data security, requiring careful data handling and auditing practices.
- Lack of concurrent transaction support
Concurrent translation support refers to the ability to handle multiple simultaneous read and write operations. A data lake does not support concurrent transactions, so when many users try to access or modify the underlying data simultaneously, it can lead to data inconsistency or integrity issues.
Data Lake vs. Data Warehouse
Data lakes and warehouses are integral to modern data architecture; however, they serve different purposes and have distinct characteristics. Let’s discuss some to differentiate when to choose one over the other:

| Aspect | Data Lake | Data Warehouse |
|---|---|---|
| Structure and Schema | Data lakes store data in their native formation without any predefined schemas. | A predefined schema and structure of the data is required before it can be stored and queried. |
| Supported Data Types | Data lakes store data in their native format, in the form of files and objects, and can store structured, semi-structured, or unstructured data. | Data Warehouses are primarily designed to store structured data. |
| Business Use Cases | Use data lakes when you want the data for data exploration, machine learning, and experimentation, along with real-time/big data analytical processing. | A data warehouse solution is best for business intelligence, reporting, and structured query-based analysis. |
| Cost considerations | It is powered by inexpensive storage solutions, such as Amazon S3, Azure Blob Storage, etc., which power data lakes. | Data warehouse solutions are built upon a large-scale storage and computing resource for optimized, high-performance queries, making them more expensive. |
| Data Processing | Lakes can power both batch and a real-time workload for upstream and downstream applications. | Data warehouses are designed for batch processing and structured data queries. |
Data Lake Use Cases
Let’s explore some use cases of data lakes in various industries:
1. Healthcare
Healthcare is where almost everything, from patient data points like medical records and histories, is stored for future use cases. Data lakes empower democratization with phenomenal volumes of data across medical researchers, doctors, and practitioners within the organization.
Following the data lake strategy, healthcare bodies can capture and standardize a wide range of data, from claims and clinical data to health surveys, administrative data, patient registries, and data from EHRs and EMRs.
Data can then be utilized to paint a complete holistic picture of a patient, which can be helpful in various user cases, such as arriving at better results, cost-effective measures, medical decisions, and quality improvement activity.
2. Media and Entertainment
Media and entertainment companies can store vast amounts of data, such as Advertisements, Social Media Trends, Search Trends, and Viewer Engagement Metrics, in a centralized data lake.
Based on those metrics, the recommendation engine would provide appropriately targeted content to the end user. Such a recommendation system is sophisticated in that it requires access to enormous amounts of data, including consumer streaming habits and behavior on social media, and, of course, all these depend on the user’s consent preferences. Based on these analytics, media houses can retarget ads, make better ads, and learn more about audience behavior. This enables focused marketing campaigns and, therefore, more revenue and customer satisfaction.
3. Telecommunication
Telcos monitor data from network operations, customer interactions, and communication and store it in a data lake. Data analysts can query the data lake to monitor the performance of their network in real-time, identify equipment failure patterns at the network level, and optimize network resources.
Running an analysis of this data can help reduce and prevent downtime, thus increasing the quality of service. Furthermore, data lakes facilitate the development of new data-driven services and offerings out of said data, including creating personalized plans and targeted promotions that drive loyalty and rise in revenue.
4. Financial Services
The usage of data lakes in financial institutions has surged with the rise of fintech technologies. These lakes store, manage, and analyze large data sets about transactions, customer mastering, market feeds, and associated regulatory reports.
For example, a data lake would help a bank merge its data from different departments, even sources outside the organization, to have complete enterprise-wide visibility of customer behavior and financial risk. This, in turn, leads automatically to more fraud detection, more personalized banking, and greater compliance with regulatory requirements.
Best Practices For Data Lake Integration
1. Establish Clear Architecture & Governance
Define a robust data lake architecture with well-documented policies for data ownership, quality, and compliance. Implement governance frameworks to manage metadata, data lineage, and regulatory adherence.
2. Develop Data Ingestion Strategies
Utilize scalable ETL/ELT tools to handle data ingestion from multiple sources, supporting both batch and real-time processes. Ensure your ingestion workflows include thorough validation and error handling to maintain data integrity.
3. Implement Effective Metadata Management
Maintain a comprehensive data catalog and metadata repository. This enables users to easily locate and understand available data, thereby supporting self-service analytics and data trust.
4. Prioritize Data Quality
Incorporate automated data cleansing and quality checks during ingestion. Regular monitoring for accuracy, consistency, and completeness is essential to ensure reliable data.
5. Enhance Security and Access Controls
Apply encryption, role-based access, and auditing measures to safeguard sensitive information. Establish clear access policies and track user activities to ensure data security and compliance.
Conclusion
Data lakes are pivotal in modern data architecture, serving as a center of data experimentation and innovations by enabling the storage and analysis of vast amounts of diverse data along with the flexibility to explore and experiment with organizational data without the constraints of traditional data warehouses, empowering data scientists, analysts, engineers, and other data stakeholders to collaborate and uncover insights, drive business decisions and foster innovations.
Interested in learning about data warehouse, data lake, and data lakehouse? Read our comprehensive guide to discover how these data storage solutions compare and which one suits your requirements best.
To learn more about data lakes and seamlessly migrate your data from them, sign up for Hevo’s 14-day free trial now!
Extra Information to Enhance your Understanding
- Explore Data Lake Architecture
- Read about Snowflake Data Lake
- Emerging Technologies to Address Data Lake Challenges
Frequently Asked Questions (FAQs):
1. Does AWS have a data lake?
AWS offers a data lake solution called Amazon S3 (Simple Storage Service), often integrated with other AWS services like AWS Glue, Amazon Redshift, and Amazon Athena.
2. Is Snowflake a Data Lake?
Snowflake is not precisely a data lake but more of a unified data platform for data warehousing and ML workload. However, it can offer similar capabilities by connecting it to data lake sources like Amazon S3, Azure Blob storage, etc.
3. Is Databricks a Data Lake?
Databricks is a unified data platform that can connect to different data lake sources to fetch and store data for its Engineering, Analytics, and Machine Learning workloads.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





