




Data integration, migration, and business intelligence projects fail on the first try in at least 70% of cases, according to Gartner Group. Business organizations are producing (and demanding) more data than ever before, however, the failure rate is shocking.
In any business today, ETL technologies serve as the foundation for data analytics. Data warehouses, data marts, and other important data repositories are loaded with the data that is extracted from transactional applications and transformed to make it ready for analysis in Business Intelligence applications.
DataOps is the implementation of Agile Development, Continuous Integration, Continuous Deployment, Continuous Testing, and DevOps concepts to a data-oriented project. It includes any data integration or migration project, including those that involve data lakes, data warehouses, big data, ETL, data migration, BI reporting, and cloud migration.
Data is evaluated at each stage of its journey from source to consumption according to its intended purpose, including analytics, data science, and machine learning. As a result, the pipelines become fragile and extremely sluggish to adapt to change. DataOps ETL assists in the development, management, and scalability of data pipelines for reusability, reproducibility, and rollback as needed.
Let’s dive right in to understand how the fundamentals of DataOps can be used to implement DataOps ETL.
Table of Contents
What is DataOps?
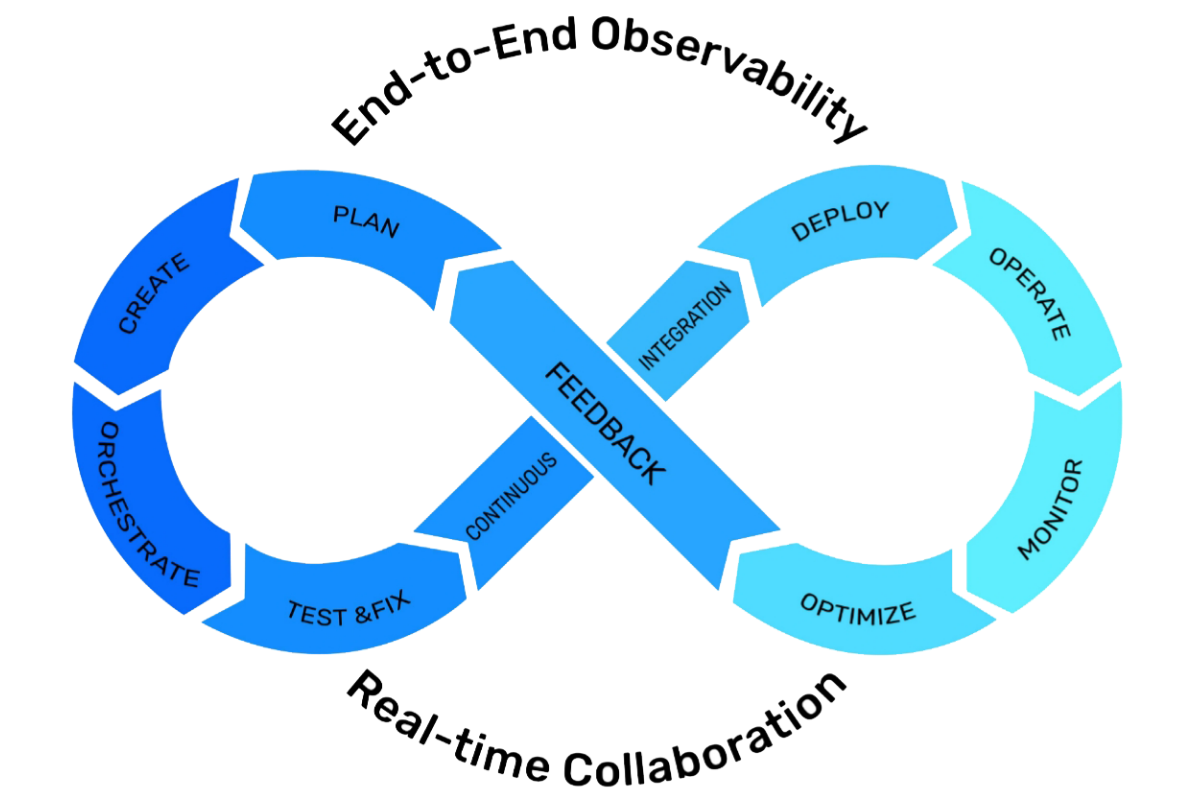
The “purpose” of DataOps is to accelerate the process of extracting value from data. It does so by controlling the flow of data from source to value.
Scalable, repeatable, and predictable data flows are the end result for data scientists, data engineers, and business users. People play just as big of a role in data operations as do technologies and procedures.
An organization must manage an infinite amount of data flows in the existing environment. Companies require a new approach to handle this complexity as the amount, velocity, and diversity of data increase. Scalability and repeatability of data management are critical for maximizing data efficiency and value development.
Given that this decade has been dubbed the “decade of data,” firms are inevitably making investments to enable data teams to keep up with technological advancements in terms of productivity, efficiency, and creativity. To maximize data efficiency and value creation, DataOps enters the picture in this situation.
Another aspect is the growing number of data consumers within an organization, each with its own set of abilities, resources, and knowledge. The volume, velocity, and variety of data are increasing, and companies need a new way to manage this complexity. Heads of data teams, in particular chief data officers (CDOs), are required to use data to provide value to the company, respond to ad hoc requests, and make sure their teams are productive while overseeing all data management-related activities.
Benefits of DataOps
Focus on Continuous Software Delivery
- To effectively manage data and delivery activities within a DevOps context, DataOps aligns people, processes, and technology.
- The tools required for efficient data management and delivery operations are provided by DataOps.
- Software distribution is automated by DataOps, resulting in a standardized, repeatable, and predictable procedure.
Enhanced Efficiency
- To increase employee productivity, DataOps automates process-oriented approaches.
- Resources can now concentrate on strategic activities rather than wasting time on routine ones thanks to DataOps.
- By using DataOps techniques, human error can be avoided.
- DataOps automates code inspections, controlled rollouts, and the creation of repeatable, automated procedures.
Improved Employee Engagement
- Recognization is the most effective element in predicting employee engagement levels. With DataOps, this will provide a meaningful viewpoint that aids businesses in making informed plans and carrying them out.
- Incorporating tools like employee recognition software can further enhance these efforts by ensuring that achievements are acknowledged, which can drive higher employee engagement and alignment with company goals.
- DataOps develops best practices through automation and agile processes so that workers may deliver better work with more responsibility.
Empower your Data Strategy with Hevo’s no-code ETL platform. Automate data pipelines to ensure real-time data availability and seamless integration across your organization. Hevo makes it easy to manage and scale your data operations without the technical complexity.
- Automate and optimize ETL workflows effortlessly
- Ensure data consistency and reliability in real-time
- Connect and integrate data from 150+ sources
Join over 2000+ customers across 45 countries who’ve streamlined their data operations with Hevo. Rated as 4.7 on Capterra, Hevo is the No.1 choice for modern data teams.
Get Started with Hevo for FreeWhat is ETL?
ETL, or extract, transform, load is the foundation of a data warehouse. It is a three-phase data integration process to extract data from multiple source systems, transform it into an analytically-ready format, and load it into a data warehouse. ETL enforces data quality and consistency standards so that your developers can build applications and business users can make decisions.
Why is ETL Needed?
For many years, businesses have counted on the ETL process to gain a consolidated picture of the data that helps them make better business judgments. This approach of combining data from many systems and sources remains a crucial part of a company’s data integration toolkit today.
- When combined with an enterprise data warehouse (data at rest), ETL offers businesses a rich historical context.
- Business users can more easily assess and report on data pertinent to their projects because of ETL’s unified perspective.
- ETL codifies and reuses data-moving procedures without requiring technical expertise to develop code or scripts, increasing the productivity of data professionals.
- Over time, ETL has evolved to suit new integration needs for new technologies like streaming data.
- In order to combine data, ensure accuracy, and offer the audits normally needed for data warehousing, reporting, and analytics, organizations need both ETL and ETL.
DataOps ETL: DataOps in Automated ETL Testing
The business is what ETL ultimately supports. Success in today’s organizations depends on how efficiently ETL processes are managed inside the wider DataOps and MLOps pipelines that support the operationalization of data and analytics.
Any advanced ETL system should be able to clean, add to, and improve all types of data in order to serve an increasing number of complex applications. According to data management experts who participated in a recent TDWI poll, the main goal of upgrading ETL and other data integration systems is to enhance the efficiency with which different data-intensive applications serve the bottom line.
There is a tendency in the DataOps domains to focus heavily on technologies that aid in testing automation. In addition, there is a problem with how project quality control and particular tests fit into the product lifecycles of DataOps. How can teams get an adequate understanding of the possible flaws that little incremental modifications can bring about without bogging down the process? The tester’s reaction should consist of developing a testing plan that reflects shared objectives amongst project teams.
As far as feasible, DataOps procedures should automate ETL testing while taking into account the IT solutions chosen for the project. Automated testing may be trustworthy, but the caliber and scope of the tools and tests will determine how effective they are. Members of the project team in a DataOps-practicing organization spend at least 20% of their time preparing and creating tests. New tests are introduced whenever an issue is found and fixed, and then regression tests need to be executed.
The key benefit of automated ETL testing is that it is easy to conduct frequently and on a regular schedule. Regular manual testing is sometimes too expensive and time-consuming. You must constantly and frequently verify your data and ETL logic to guarantee good quality.
The testing process itself might be difficult to automate, but it is crucial for enhancing development speed and consistency. Visit this blog to learn more about this.
Organizations should prioritize the following business criteria when preparing to update their DataOps ETL systems:
- COMPLIANCE: Organizations need ETL and other DataOps solutions that assist them in adhering to data privacy and industry-specific data usage requirements while supporting enterprise-wide data governance standards.
- AGILITY: The unpredictable and the ordinary coexist in business. DataOps ETL and other DataOps operations must enable both repeatable orchestration and ad hoc workloads in order to cover the full range of ETL requirements, allowing businesses to react to urgent demands.
- SIMPLICITY: Businesses operate most effectively when data analytics are made available to all types of consumers. This necessitates visible, self-service, coding-free, and intuitive DataOps ETL and other DataOps tools. It should make it easier for consumers to consume data and prevent them from becoming confused by sloppy, conflicting, and poorly specified data.
- AUTOMATION: Data integration is a daunting task, but thankfully it can be automated. Users should no longer be required to do pointless, manual, time-consuming data integration tasks thanks to DataOps ETL systems. DataOps ETL solutions should be adapted to the requirements of certain DataOps stakeholders, such as data engineers and data scientists, in order to decrease the time and expense needed to design, implement, and maintain processes.
Construct Your DataOps ETL Roadmap
ETL modernization can be a cumbersome process. There are many different technical, operational, and business challenges that overlap or depend on one another.
The following components of a modern DataOps ETL pipeline should be taken into account as business DataOps specialists construct their ETL road maps:
- UNIFIED: ETL pipelines should manage workloads across the hybrid cloud, multi-cloud, and other complicated topologies in a single DataOps framework. Additionally, they should seamlessly interact with MLOps pipelines for machine learning operations (MLOps) for more effective data preparation and ML model training into intelligent applications.
- FLEXIBLE: DataOps demands should be supported by flexible scalability in ETL pipelines. Computational, storage, and other cloud resources should be elastically provisioned as required. They ought to have the capacity to take in and process information from organized, semi-structured, and unstructured sources. Any form of ETL flow, including those requiring data cleansing, profiling, monitoring, cataloging, and preparation, should be able to be built and executed by businesses using pipelines. They should also make it possible to create, manage, and orchestrate several ETL pipelines concurrently, as well as rearrange the order in which ETL jobs are executed.
- GOVERNED: All governance tasks for ingestion, preparation, and delivery to downstream applications data assets should be supported by ETL pipelines. They have to be integrated with the existing infrastructure for business glossaries, master data management, data profiling, data cleaning, data lineage, and master data management, across all domains.
- ACCELERATED: ETL pipelines should be designed for continuous, real-time, low-latency processing. They ought to be capable of running migrated workloads in a distributed, in-memory, cloud-native architecture that comes standard with support for Spark, Flink, Kafka, and other stream computing backbones.
- OBSERVABLE: Intelligent data observability tools should be used to monitor ETL pipelines from beginning to finish. This is essential for identifying data anomalies, foreseeing problems in advance, and, resolving problems with ETL pipelines as well as the closed-loop handling of certain workloads.
- INTELLIGENT: An ETL pipeline should dynamically adjust to shifting contexts, workloads, and needs inside a modern DataOps architecture. This entails integrating machine learning knowledge into each process and pipeline node. Depending on the data, the time, and the circumstances, the ETL architecture should be able to adapt to cross-pipeline dependencies.
It should also be able to automatically find new and updated data assets that need to be retrieved into the pipeline & validate data as it is imbibed into the pipeline. Moreover, it should be able to adjust its logic to new sources, contextual factors, and processing needs, and pre-emptively fix technical, workload, and performance issues before they become crippling ones. Last but not least, an intelligent DataOps ETL pipeline should automatically produce in-the-moment contextual recommendations that assist DataOps specialists in managing, improving, and resolving complicated processes and ETL workflows.
Guidelines for Implementing a DataOps ETL
One of the most important aspects of cloud modernization is the evolution of a conventional ETL platform into an intelligent DataOps ETL pipeline. A modern ETL platform migration might be a challenging task. Existing ETL procedures must be seamlessly transferred to a new platform without interfering with technical or business processes. In this quest, important steps include:
- PLANNING: When selecting the ideal ETL modernization target architecture for their requirements, Enterprise DataOps experts should consider factors like the target environment—on-premises, in the public cloud, or in a hybrid or multi-cloud configuration—where the target ETL pipeline will function. They should choose the finest options for automating as much of this labor as they can while preparing a migration to the target design. ETL specialists should prioritize which ETL jobs will be migrated (and in what order) to the target environment once the preferred solution has been determined and migration tools have been chosen.
- IMPLEMENTATION: ETL migration often entails transferring several processes and related activities. DataOps experts may decide to start from scratch when rebuilding ETL procedures on the target platform. They may decide to transfer workflows in their exact form from the legacy environment to the target environment. As a substitute, they may automate the transfer of current ETL workloads from conventional tools to the intended platform. DataOps specialists should make sure that moving ETL workloads to the target environment won’t affect the availability of data for users, stakeholders, and downstream applications. After the new DataOps ETL environment has been launched, it has to be extensively checked to make sure it functions satisfyingly with all of the current ETL jobs.
- OPTIMIZATION: ETL migration does not always have to be a simple lift-and-shift operation. To benefit from the scalability, speed, and other advantages of the new platform, new ETL procedures may and ought to be created. At the very least, redundant ETL processes would need to be integrated to conserve bandwidth, storage, and processing resources.
Final Thoughts
The main goals of data operations are to streamline the data engineering pipeline and eliminate data organization silos. CDOs, business users, and data stewards are involved at an early stage in the life cycle of data generation. This is extremely beneficial to the data dev team, as well as the operations and business units dealing with ETL challenges in production situations.
To gain a deeper understanding of the DataOps approach, check out our comprehensive overview of the DataOps framework.
Enterprises must transition to a flexible, fully managed, cloud-native DataOps infrastructure in order to modernize ETL. To enable the development, training, and deployment of data-driven intelligent apps on which modern business depends, this infrastructure should ideally be united with cloud-based MLOps pipelines and data lakehouses.
FAQ on DataopsETL
What is meant by DataOps?
DataOps (Data Operations) is an approach to managing and delivering data that emphasizes collaboration, automation, and continuous improvement across the entire data lifecycle. It integrates DevOps principles with data management practices to streamline workflows, enhance data quality, and speed up data delivery. DataOps aims to improve the efficiency, reliability, and agility of data analytics and data-driven decision-making.
What is the difference between Agile and DataOps?
– Agile: A software development methodology focusing on iterative development, collaboration, and flexibility. Agile emphasizes quick delivery, continuous feedback, and adaptation to changing requirements.
– DataOps: While inspired by Agile principles, DataOps applies explicitly to data management and analytics. It goes beyond software development to include data engineering, integration, and quality processes. DataOps integrates data workflows with DevOps and Agile practices to ensure faster and more reliable data delivery and analysis.
What are the three pipelines of DataOps?
– Data Pipeline: This pipeline manages the data flow from sources to destinations, including extraction, transformation, and loading (ETL).
– Development Pipeline: This pipeline supports creating and deploying data-related code and configurations.
– Monitoring & Validation Pipeline: This pipeline ensures that data quality, accuracy, and performance are maintained throughout the data lifecycle.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link
