



Almost all companies today are “data rich.” They have access to exponentially more data than ever before. But they are still information poor, struggling to make sense of it all. One of the main reasons for this is disconnected data silos, acting as barriers that prevent a 360-degree view of their business.
Data integration is the key that brings data together—creating an uninterrupted flow of data from source systems to analysis target. It unlocks insights that can lead your organization to success. Without data integration, your teams may have to spend more time and resources trying to combine data from various sources manually, leading to inefficiency and increased costs.
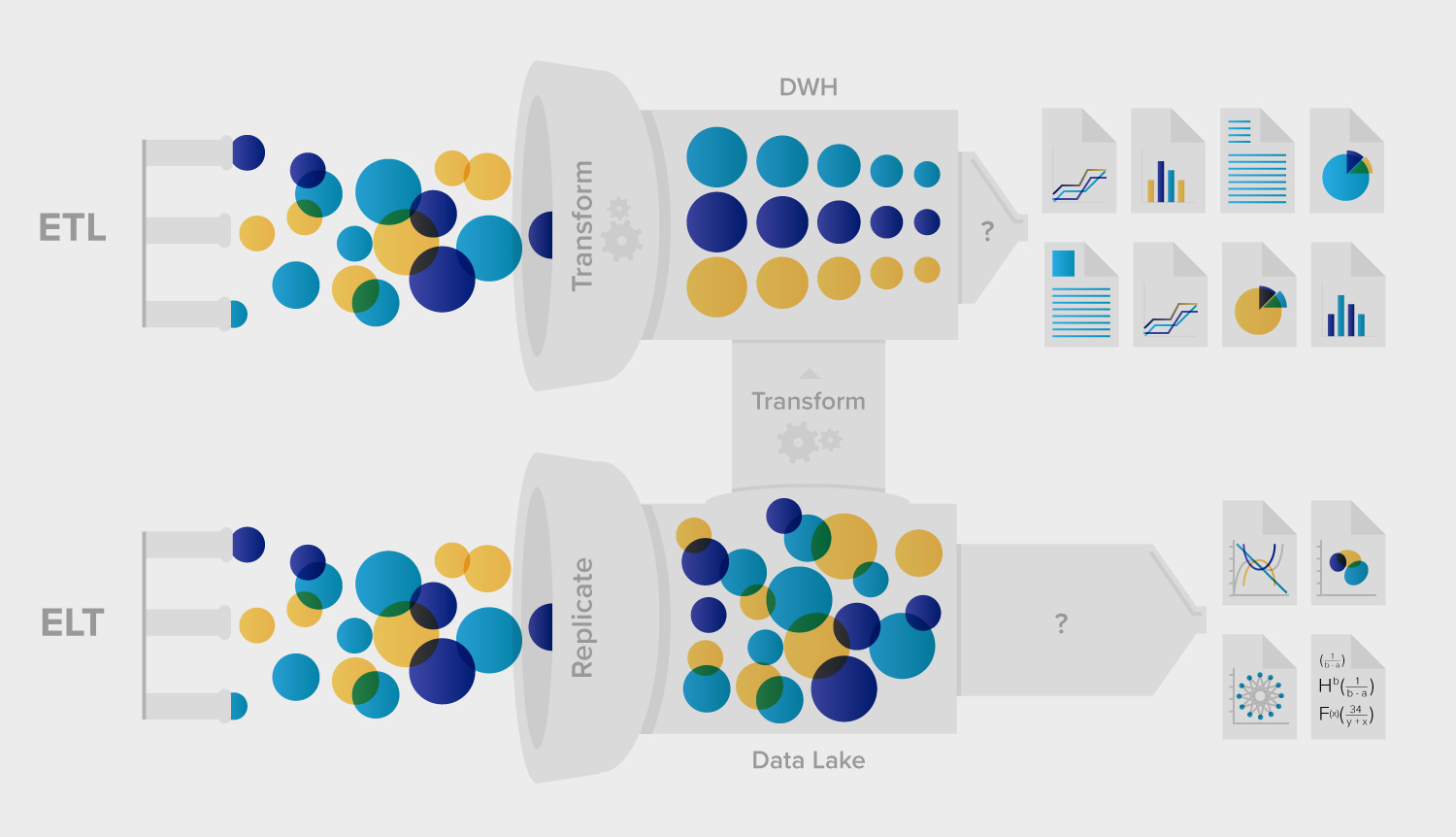
One common paradigm for data integration success is ELT. ELT stands for Extract, Load, and Transform. It represents a modern approach where the transformation step happens after the data is loaded into the lake.
In this blog, we’ll uncover the meaning of ELT and examine why it’s rapidly becoming the go-to approach for fast analytics and big data systems where data types are dynamic.
Table of Contents
What is ELT?
You may already be familiar with ETL (extract, transform, load), which has been the mainstream process for managing data pipelines and integrating data for decades. When ETL tools first emerged in the 1990s, there were relatively few operational systems, predictable data (mostly structured), and slower changes in insights.
But today, the varieties and volumes of data have grown significantly, and the need for accelerated insights has grown in tandem. This has resulted in the requirement for faster and more effective data integration processes.
ELT, or extract-load-transform, is an evolution of ETL. It is an improved approach to data warehousing that defers the burden of the transformation step to the data store without requiring a middle-tier server. Instead of following a three-step process of extracting, transforming, and then loading data, ELT condenses the process into two steps:
- Extract-Load (EL) or Replication
- Transform (T)
Here’s how the ELT workflow looks like:
| Extract (E) | Load (L) | Transform (T) |
| Raw data is retrieved from a variety of sources, including message queues, databases, flat files, spreadsheets, data streams, and event streams. | Extracted data is loaded into a data storage system, such as a data lake, warehouse, or non-relational database. | Loaded data is manipulated and cleaned in the data lake or warehouse, typically using scripts to prepare it for analysis or reporting. |
With ELT, businesses can take advantage of the processing power and storage capabilities of modern data platforms to handle large data volumes and perform more complex transformations. ELT is more suited to today’s cloud data warehouses because of advanced, powerful, and affordable computing thanks to the underpinning technological advancements.
ELT allows data engineers and data scientists to perform data transformations in parallel and scale out the computing power as necessary to achieve better performance and a faster time-to-insight. It is particularly useful for large data systems where schema-on-read is applied.
Additionally, ELT has the added benefit of being able to modify existing data with a simple code change to the view instead of having to make significant changes to the whole process, which makes it significantly faster than traditional ETL.
With cheap storage these days, data can be loaded with minimal transformation into a common lake and further transformed using SQL views or equivalent. Now, if a transform breaks or changes, you don’t have to go all the way back to the source and re-import the needed data. It’s all already in the lake; you simply need to edit the SQL file that’s doing the transform on top.
The Informed Company, Dave Fowler and Matt David
How ELT Works
The three stages of ELT include:
- Transform: Converting the data into the format necessary for analysis
- Extract: Retrieving data from the source system
- Load: Inserting the extracted data into the target system
In a typical ELT process,
- Step 1: Raw data is pulled from various data sources (extract) like CRM, ERP, email servers, IoT sensors, XML files, or cloud platforms through APIs or SQL.
- Step 2: Data is then loaded immediately into a data lake (load) to make it available to internal and external users.
- Step 3: Data in the lake undergoes substantial transformations using SQL or other query languages (transform) to match organizational needs and data storage solution requirements.
- Step 4: Transformed data is loaded into a data warehouse for further analysis and reporting.
- ELT shortens the data cycle between extracting and delivering data, but it also requires considerable effort to make the data usable and valuable.
- Any modifications or addition of new fields becomes simple because the data is already stored in the data lake.
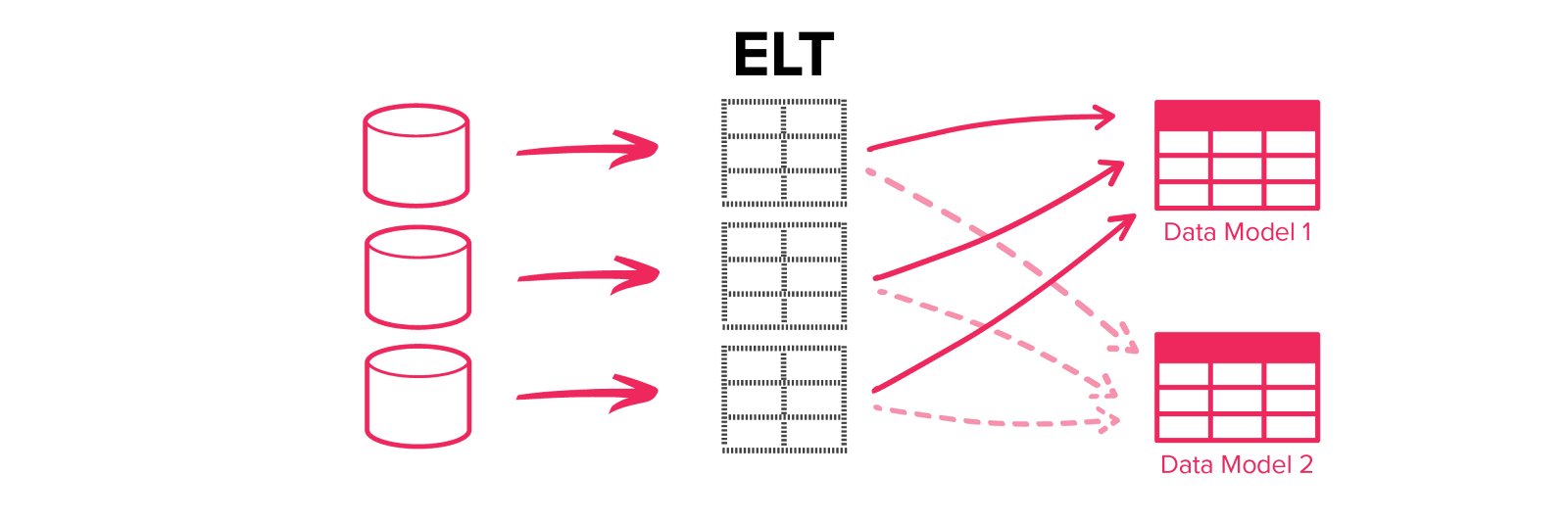
ELT enables the use of a cloud lakehouse (an open architecture that combines the best of a data lake and a data warehouse), where data transformation is accelerated by separating storage and compute resources.

Why Is ELT Better Than ETL?
A typical data transformation step is a complex and lengthy process. It requires:
- Data analysts to first thoroughly document all necessary transformations, columns, and formats.
- Data engineers to write code and deploy it to a staging or QA environment, where it is reviewed by the data analyst for accuracy.
- DevOps to deploy the code to production, which can take several days to a week.
ETL eliminates the need for the previous steps, providing a more efficient method than traditional ETL.
While loading data, you can simultaneously run data transformations and use cloud warehouses’ Massively Parallel Processing (MPP), which can allow for queried transformations to be executed simultaneously across multiple nodes rather than in sequence.
ETL vs ELT: What’s the Difference?
The obvious difference between ETL and ELT is the order in which data is processed. In ETL, data is transformed to fit the target system’s data model before it is loaded into the storage system. In contrast, ELT loads the data into the storage system first and then applies the transformation logic.
This small difference in approach creates a ripple effect, making each architecture pattern ideal for different use cases.
ETL is more rigid and focuses on specific transformation needs, while ELT is more agile and adaptable, allowing data engineers to perform transformations on the data in the data warehouse or lake as required.
Take a closer look at the other differences between ETL and ELT in the comparison table below.
| ETL | ELT | |
| Process Overview | ETL extracts data to a staging area and transforms it before loading it into the target system. | ELT extracts and loads all data into the target system and then applies any needed transformations. |
| Supported Data Structure | Best suited for structured (relational) data | Adaptable to all types of data: structured, semi-structured, and unstructured data. |
| Supported Data Volumes | Work with data sizes in the ranges of megabytes (MB) or gigabytes (GB). | Works with much larger data volumes ranging from terabytes (TB) to petabytes (PB). |
| Pipeline Speed | Slow, since transformations are applied to data before loading, which is a time-consuming process. | Faster since minimal processing is done before loading data into the storage layer. |
| Processing Time | High. Increases as data volumes grow. | Significantly less. |
| Flexibility | Less flexible, as data constraints on sources and types of transformations, need to be defined before the start of the process. | More flexible, since you can ingest data from sources without defining any transformation logic. |
| Scalability | Slow, since the transformation layer becomes a bottleneck while ingesting large-scale data. | Faster, since no transformation layer isn’t required while ingesting data. |
| Implementation Costs | Higher, since you need to design the target destination and necessary transformations, which can be challenging for small to medium-sized businesses due to the increased complexity. | Offers lower startup costs and downstream costs because most components operate in the cloud. |
| Maintenance | May require continuous changes because of constraints on data sources and transformations. | Comparatively fewer changes are required because there are no hard rules for ingesting raw data. |
| Compliance-readiness | Offers easy compliance since sensitive data is either removed or gets masked before importing it into the target destination. Almost all available ETL tools are compliant with international data standards like HIPAA, CCPA, and GDPR. | More prone to issues since all raw data is imported, regardless of whether it contains sensitive information. You may face international compliance issues if your warehouse resides in a different country. |
Gain deeper insights into the differences between ETL vs. ELT in the following guide: ETL vs. ELT: 7 Major Differences Simplified.
Benefits of Using an ELT Approach
- Greater Flexibility: With ELT, you don’t need any prior knowledge of how you are going to transform data. You can extract and load data from any source or format and then clean or enrich it later into a unified form for analysis. This approach is incredibly helpful for businesses running agile methodologies.
- Scalability: ELT handles large volumes of data from diverse sources like databases and Saas applications like Salesforce, HubSpot.
- Faster Time-to-insight: ELT’s ability to perform data transformations faster can also result in faster time-to-insight compared to ETL. ELT can support real-time data processing, allowing organizations to make quicker decisions based on the most recent data.
- Improved Performance: ELT allows for data transformations to be performed in parallel and at scale, using cloud services in the warehouse that can facilitate scalability in a cost-efficient manner.
- Less Maintenance: ELT processes are often simple and automated, making it easier to fix bugs in the transformation pipeline. Unlike ETL, in ELT, only the updated transformation needs to be re-run to achieve the correct output.
- Democratised Access to Transformations: Since ELT pushes transformation to the end, most data transformation models using SQL can be run by a broader range of individuals like data analysts, engineers, and scientists independently without relying on a dedicated data integration team.
- More Savings: ELT is often implemented using cloud-based components, which eliminates the need to worry about processing and storage costs. ELT utilizes the compute resources of the data store, which can be more cost-effective than ETL, which requires separate compute resources for data transformation.
- Easier Data Governance: ELT allows for more data governance to be concentrated in the data store rather than requiring an enterprise-wide data governance framework in place.
When Do You Know ELT is the Right Choice?
Choosing between ETL and ELT can be a difficult decision. Therefore, it’s important to take into account various factors such as your current business requirements, data maturity levels, specific use cases, available data architecture, engineering expertise, and essential data security standards.
If your business requires regular analysis of smaller to medium-sized data sets with well-defined source data and operations that don’t change frequently, ETL is the best option. On the other hand, if your business deals with large amounts of semi-structured or unstructured data and big data environments with frequent changes in data operations and requirements, ELT is a more suitable choice.
Consider the following questions while making a wise choice between ETL and ELT:
- What are my business requirements and specific use cases for the data?
- How do the performance and time-to-insight compare between ETL and ELT
- Is ingestion speed and agile analytics my number one priority?
- What are my current data maturity levels, and what are the possibilities for growth in the future?
- How often does the data change, and how frequently does it need to be updated?
- How active will the data warehouse be in handling user requests?
- What are the costs of implementation, maintenance, and scalability for each approach?
- What tools and resources are available to simplify the process?
- What is the desired level of data governance, quality, compliance, and security?
When making the final decision, it’s important to consider all the available tools, your existing data architecture, resources, and your budget that can simplify the process. It’s worth noting that ETL and ELT are not mutually exclusive, and some organizations often use a combination of both approaches depending on their specific use cases and data architectures.
ELT and ETL Use Cases
ELT Use Cases
- Cloud Migration: Moving data from monolithic legacy systems to cloud storage like a warehouse for faster processing and cost-efficiency.
- Elimination of Data Silos: Combining data from multiple marketing and sales applications and integrating it into a central repository for unified customer profiles.
- Database Replication: Replicating data from your source databases, like MySQL, SQL Server, and MongoDB, into your cloud data warehouse.
- Stable, Predictable BI: Analyzing smaller data sets containing structured data to make data-driven decisions.
ELT Use Cases
- Big Data Processing: Loading large amounts of raw data into a data lake and then using distributed processing tools, such as Apache Spark or Hive, to perform transformations.
- Agile Analytics: Loading data first and running transformation services in parallel for faster data analysis.
- IoT Data Integration: Integrating different types of data from IoT devices and sensors into a single place.
- ML & AI Modeling: Using ML and AI tools to analyze data without requiring to program analytical models.
How to Choose the Right ELT Tool?
Keep in mind these five priorities when trying to choose the right ELT tool for your business:
- Your Business Requirements and Data Integration Use Cases: Identify your specific needs, data architecture, and use cases for data integration, then select a tool with the necessary features. If you’re integrating data on the cloud, ensure that your tool can handle cloud-based data stores and play well with different cloud providers.
- User-Friendliness: Complexity is the enemy of progress, and no one wants a tool that’s impossible to wrap their head around. When evaluating your ELT tool, think about the level of technical expertise needed to make it hum.
- Cost: An intuitive and highly effective tool can cost a hefty price tag. Choose ELT tools like Hevo Data that don’t cost a fortune and offer a fully automated solution with 150+ plug-and-play integrations.
- User Roles and Permissions: User roles ensure that only authorized users have access to sensitive data and can perform specific actions within the tool. This helps to maintain data security and integrity, as well as ensure compliance with regulatory requirements.
- Support and Maintenance: Lastly, a tool is only as good as the support it comes with. Your ELT vendor should be a reliable partner, providing regular software updates and maintenance so you can focus on extracting insights and not fixing data pipelines.
It’s always a good idea to try out a few tools and test them with sample data sets to get a better understanding of how they work and how well they fit your needs.
Best ELT Tools Available in the Market
Ready, set, integrate! Try these top ELT tools and get your data in shape.
- Hevo Data: Experience effortless data flow with our no-code pipeline platform. Enjoy easy setup and over 150 connections, all backed by round-the-clock support at unbeatable prices.
Hevo was the most mature Extract and Load solution available, along with Fivetran and Stitch, but it had better customer service and attractive pricing. Switching to a Modern Data Stack with Hevo as our go-to pipeline solution has allowed us to boost team collaboration and improve data reliability and with that, the trust of our stakeholders in the data we serve.
– Juan Ramos, Analytics Engineer, Ebury
- Blendo: Simplifies data integration from sales, marketing, support, or accounting applications to a cloud data warehouse for faster intelligence.
- Matillion: A push-down ELT tool designed to migrate data from on-premise to modern cloud-based data warehouses.
- Talend: A modern, scalable, big data management solution for data integration across the cloud and on-premises.
- Airflow: An open-source platform to programmatically author, schedule, and monitor ETL/ELT workflows. Designed for data engineers.
What are the Best Practices of Designing an ELT Pipeline?
Now that we have discussed the ELT process, its advantages, challenges, and use cases in detail, let’s look at some of the best practices your organization can follow while designing an ELT pipeline.
- Understand Your Business Needs: Before designing your ELT pipeline, you must first understand why you need the ELT approach. What kind of transformations do you hope to perform with the pipeline? What type of data do you need to collect? You can begin designing your pipeline once you have answers to these questions.
- Ensure You Audit Your Data Sources: To avoid errors in the pipeline, you must audit your data sources. See to it that the data is accurate and complete.
- Decide on Your Approach to Data Extraction: One of the more important things to do before designing your pipeline is to determine the approach of data extraction. Depending on the volume, complexity and velocity of your data, you must decide if the pipeline should be batch based or streaming.
- Have a Robust Cleansing Mechanism in Place: You will need to cleanse and transform your data quite a lot before using it to make data-driven decisions. Therefore, it is important to have a cleansing mechanism in place that is compatible with your pipeline.
- Automate Your Pipeline: Enabling or introducing features like auto schema management can help automate the entire ELT pipeline and reduce the risk of human errors.
- Make Sure Your Pipeline is Always Up and Running: Try to build an ELT pipeline with very low to zero downtime. Have a system in place that monitors the health of your pipeline, and identifies and troubleshoots problems early on.
The Potential Drawbacks of ELT
Faster Analytics Can Come With Stealthy Costs
Although loading data directly into the data store like a data lake does help fast-track the analytics, with an EL-fed data store, there will be more data to sift through compared to ETL-fed data stores. This can be tedious and may require generating basic summaries every time they’re needed.
Even if your data engineers are able to transform the data and place it into a data store, they would still need to separate these intermediate results from the remaining raw data. This increase in work is not just on the end of the data store, but also on the part of the engineer, and the end consumer. The queries that a data consumer may need to put together may be very complex, depending on how long the path is from raw data to the desired measurement.
Data Management Can Get Complex
With ELT, organizations need to use advanced data management and transformation tools, which can be more complex to set up and maintain than traditional ETL tools.
This added complexity can also increase the risk of data quality issues, as it may not have the same level of data validation and cleansing that is built into traditional ETL processes.
Data Privacy and Security Concerns
With an ELT approach, sensitive data is often stored in a more vulnerable location during the transformation process, which increases the risk of data breaches and unauthorized access. Additionally, ELT may not have the same level of data encryption and masking capabilities as ETL, which further increases the risk of data breaches.
What are ELT services?
The set of services that encompass the data integration process of Extract, Load, and Transform (ELT) is called ELT services. These can include
- Data Extraction Services that extract data from various sources such as databases, files, and APIs.
- Data Loading Services that load data into a data store such as a data lake, data warehouse, or cloud-based data platform.
- Data Transformation Services that transform data like data cleaning, data normalization, and data aggregation.
- Data Quality and Governance Services for data validation, data profiling, and data auditing.
- Data Security Services for data encryption, data masking, and data access control.
- Monitoring and Maintenance Services to monitor the performance of the data integration pipeline and troubleshoot any issues that may arise.
Conclusion
In summary, ELT stands for Extract, Load, and Transform, which represents a faster approach to data pipeline management. With ELT, you can:
- Defer the transformation step to the data store
- Benefit from faster analytics and efficient data processing
- Handle massive volumes of data
- Allow data consumers to transform data as per their needs
Unlike traditional ETL, this method is low-maintenance, scalable, and ingests data at a speed that does not depend on data size or type. However, it also has its drawbacks, such as the need to sift through more data and the increased complexity of data management.
It is, therefore, important to weigh the pros and cons of ELT and decide if it’s the right approach for your organization’s needs.
Only 26.5% of organizations report having established a data-driven organization. Make sure your organization is one of those success stories.
Simplify your data pipeline management by using Hevo Data. Hevo Data can automate and scale your ELT pipelines while providing 150+ plug-and-play connectors and 24*7 support at unbeatable prices.
FAQs
1. what does elt stand for in business?
In Business ELT stands for Extract, Load, and Transform. It is another type of data integration process by which raw data is extracted from one or more sources, loaded directly into a destination data store like a data lake or a data warehouse, and then transformed to make it suitable for analysis.
2. Which is better, ETL or ELT?
It depends on your specific use case, business goals, and data architecture.
ELT is the best choice for your business if you:
1. Prefer agile analytics.
2. Deal largely with semi-structured or unstructured data in big data environments.
3. Need constant revisions in data operations.
On the other hand, ETL is a more suitable option if you:
1. Have well-controlled source data and data operations that need no revisions.
2. Work in smaller-to-medium-size data environments.
3. Deal mostly with structured data.
3. What is ELT management?
ELT management refers to the process of managing and maintaining the Extract, Load, and Transform (ELT) pipeline in a data warehousing environment. This includes tasks such as monitoring the data flow, ensuring data quality, managing the data pipeline schedule, and troubleshooting any issues that arise.
Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link
