
 Upcoming demo days on
“Live Workshop: What Breaks Salesforce Pipelines (And How to Avoid It)”
|
Mar 31, 2026
|
Register Here
Upcoming demo days on
“Live Workshop: What Breaks Salesforce Pipelines (And How to Avoid It)”
|
Mar 31, 2026
|
Register Here
Upcoming demo days on
“Live Workshop: What Breaks Salesforce Pipelines (And How to Avoid It)”
|
Mar 31, 2026
|
Register Here
Upcoming demo days on
“Live Workshop: What Breaks Salesforce Pipelines (And How to Avoid It)”
|
Mar 31, 2026
|
Register Here


Take raw data and turn it into clean, well-structured, and trustworthy datasets that can be used for reporting, dashboards, and analysis.
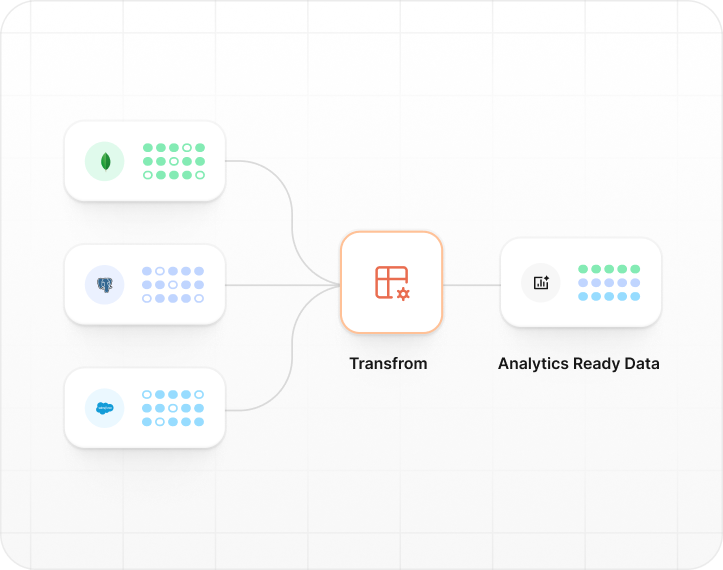
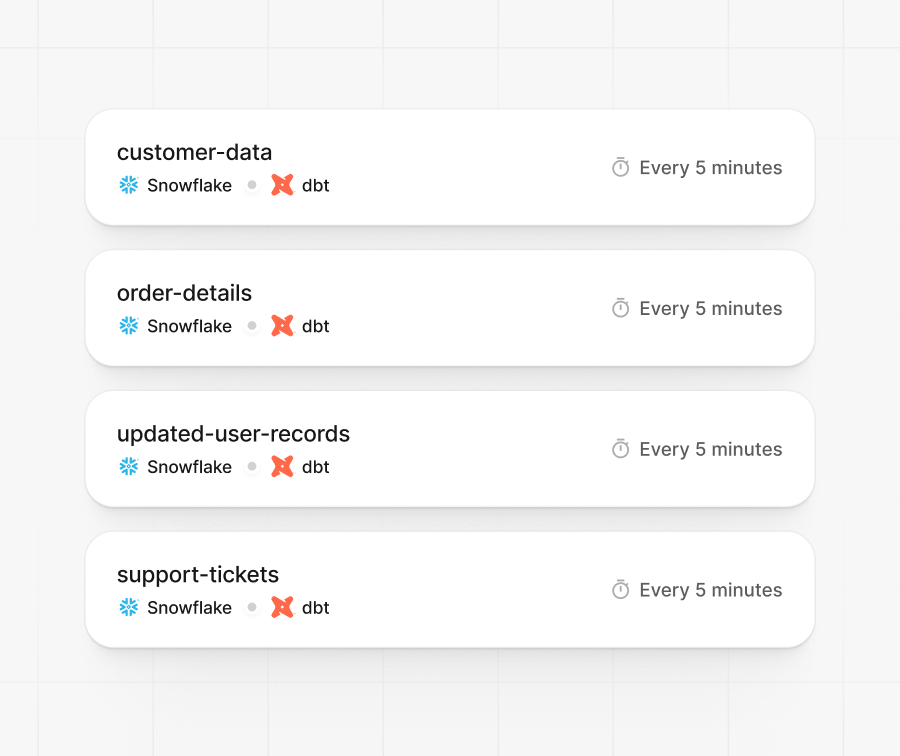
Pipelines, models, tests, and logs visible together so issues never get lost.
Bring SQL models and dbt Core models into Hevo without additional setup or orchestration layers.
Run jobs automatically, keep data always up to date, and deliver analytics faster.
Logs, lineage, run history and real alerts that give you clear visibility end to end.
Built-in retries and automation for consistent data availability.
Team access made simple. No per user fees and no barriers to working together.
Runs existing dbt Core projects and fits your modern data stack.
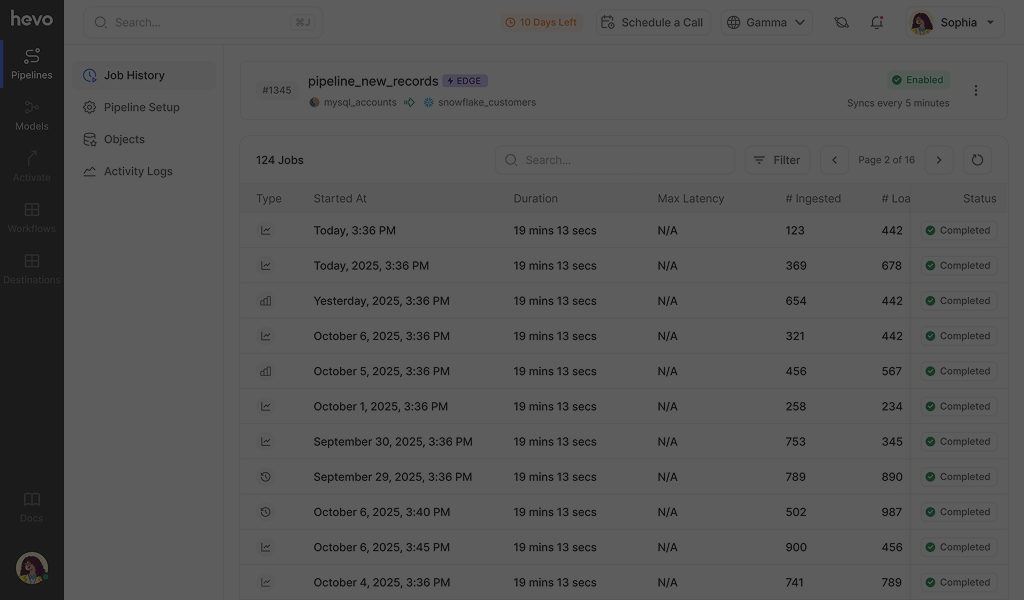
Build and schedule SQL transformations right where your data already flows
Execute models in near real time with support for joins, aggregates, and all query capabilities of your destination.
Deliver reliable, ready-to-use datasets with less manual effort
Native orchestration with complete visibility into lineage and tests
Trigger jobs after load or on flexible schedules
Deploy and scale dbt Core projects without extra infrastructure

With Hevo, we streamlined data workflows, unlocked actionable real time analytics, and enabled teams to focus on innovation instead of ongoing data maintenance.

With Hevo, moving data into our data lake is effortless. It eliminates complex schema management, pipelines, and transformations that would otherwise be time consuming and laborious.

While evaluating data integration tools, Hevo stood out as the fastest for data movement, with transformation capabilities that clearly surpassed every other solution we considered.