




As a data engineer, you hold all the cards to make data easily accessible to your business teams. Your team just requested an Amazon S3 to PostgreSQL connection on priority. We know you don’t wanna keep your data scientists and business analysts waiting to get critical business insights. As the most direct approach, you can go straight for by granting IAM Policy. Or, hunt for a no-code tool that fully automates & manages data integration for you while you focus on your core objectives.
Well, look no further. With this article, get a step-by-step guide to connecting Amazon S3 and PostgreSQL effectively and quickly and choose the method that suits your best.
Table of Contents
What is Amazon S3?

Amazon S3 (Simple Storage Service) is an object storage service that Amazon Web Services (AWS) offers. It lets you store and retrieve any amount of data from anywhere on the internet. S3 is great for managing big data without the need for physical infrastructure. Think of an e-commerce site that needs to store product images, customer data, and transaction records. With S3 you can store thousands of high-quality product images and load them fast for a smooth shopping experience.
S3’s adaptability as a central data repository is evident in its integration across the modern data stack, from workflow orchestration tools that use an airflow s3 connection and the s3keysensor for task automation, to large-scale data processing with a databricks s3 link, and finally to business intelligence where both tableau s3 and aws s3 data studio connections enable direct data visualization.
Key Features of S3 That Appeal to Businesses
- Scalability: Scale storage from gigabytes to petabytes as needed.
- Durability and Availability: 99.999999999% durability, data auto-replicates across multiple facilities for safety.
- Storage Classes: Choose from standard for frequently accessed data and S3 Glacier for long-term storage. The introduction of S3 tables has taken the storage feature to a whole new level.
- Data Security: Encryption for data at rest and in transit.
- Integrates with AWS Services: Works with other AWS services like AWS Lambda and Amazon CloudFront.
- Rich Documentation: Programmatic access to S3 is achieved through a well-documented Amazon S3 REST API integration, allowing for custom application development.
What is PostgreSQL?

PostgreSQL is an open-source, general-purpose, object-relational database management system, or ORDBMS. It is widely used and provides advanced features along with standard compliance. These features include complex queries, foreign keys, triggers, and views—all supporting transactional integrity with full ACID compliance. Additionally, it offers extensive customization options, allowing users to define custom data types, functions, and operators, making it highly extensible and adaptable.
Key Features of PostgreSQL
- Provides built-in support for JSON, XML, arrays, hstore, and custom types, making it ideal for modern applications that require complex data models.
- PostgreSQL is released under the PostgreSQL License (similar to MIT), which makes it free to use, modify, and distribute.
- Supports Atomicity, Consistency, Isolation, and Durability (ACID), ensuring reliable transactions and data integrity.
Ditch the manual process of writing long commands to connect your Amazon S3 and PostgreSQL and choose Hevo’s no-code platform to streamline your data migration.
With Hevo:
- Easily migrate different data types like CSV, JSON etc.
- 150+ connectors like PostgreSQL and Amazon S3(including 60+ free sources).
- Eliminate the need of manual schema mapping with the auto-mapping feature.
Experience Hevo and see why 2000+ data professionals including customers, such as Thoughtspot, Postman, and many more, have rated us 4.3/5 on G2.
Get Started with Hevo for FreeMethod 1: Using Third Party Tools Like Hevo
Step 1: Configure Amazon S3 as your Source
Fill in the attributes required to configure Amazon S3 as source.

Step 2: Configure PostgreSQL as your Destination
Now, you need to configure PostgreSQL as the destination.

After implementing the two simple steps, Hevo will take care of building the pipeline for replicating data from Amazon S3 based on the inputs given by you while configuring the source and the destination.
The pipeline will automatically replicate new and updated data from Amazon S3 to PostgreSQL every 5 mins (by default). However, you can also adjust the data replication frequency as per your requirements.
Data Pipeline Frequency
| Default Pipeline Frequency | Minimum Pipeline Frequency | Maximum Pipeline Frequency | Custom Frequency Range (Hrs) |
| 5 Mins | 5 Mins | 3 Hrs | 1-3 |
Method 2: Using IAM Policy
Step 1: Create an AWS S3 Bucket
- Log in to your Amazon Console.
- Click on “Find Services” and search for S3.
- Now, click on the “Create Bucket” button.
- Enter the bucket name and select the region.
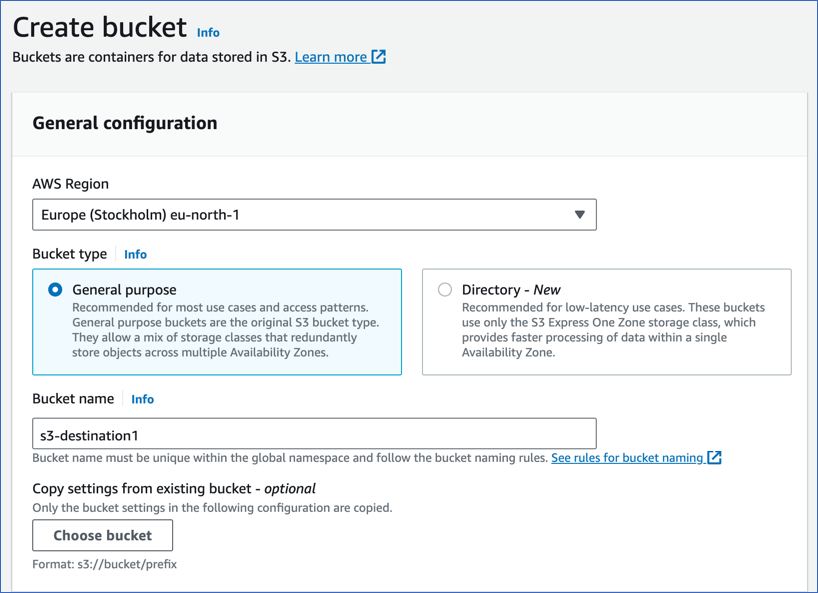
- Click on the “Create” Button.
- Search for the Bucket, and check for access. It should not be public.
Step 2: Add Sample Data as CSV Files in S3 Buckets
- Create a file “employee_Hevo.csv.”
- Add the following components:
Employee_Id,Employee_First,Employee_Last,Employee_Title
1,Jane,Doe,Software Developer
2,Vikas,Sharma,Marketing
3,Rajesh,Kumar,Project Manager
4,Akshay,Ram,Customer Support
- In the S3 console, select the bucket name you just created.
- Click on the “upload” option and follow the onscreen instructions.
Step 3: Configure PostgreSQL Database Tables & Objects
- Open PostgreSQL Management Studio, run the script below, or create a similar table.
CREATE TABLE [dbo].[Employees](
[Employee_Id] [int] IDENTITY(1,1) NOT NULL,
[Employee_First] [varchar](25) NULL,
[Employee_Last] [varchar](25) NULL,
[Employee_Title] [varchar](50) NULL,
CONSTRAINT [PK_Employees] PRIMARY KEY CLUSTERED
(
[Employee_Id] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
Step 4: Create the IAM Policy for Accessing S3
- Before the data is migrated from S3 to PostgreSQL, you need to set up IAM policies so that the bucket you created earlier is accessible.
- Click on AWS search and search IAM.
- In the policies section, click on “Create Policy.”
- Click on the “Choose a service” button to search for S3.
- Complete and fill all the access levels and parameters.
- In the resources tab, select the bucket name and click on the “Add ARN” button. Enter the bucket name.
- Add the CSV file by specifying the ARN. Then specify the Bucket name and Object name.
- Go to the review policy section and click on “Create Policy.”
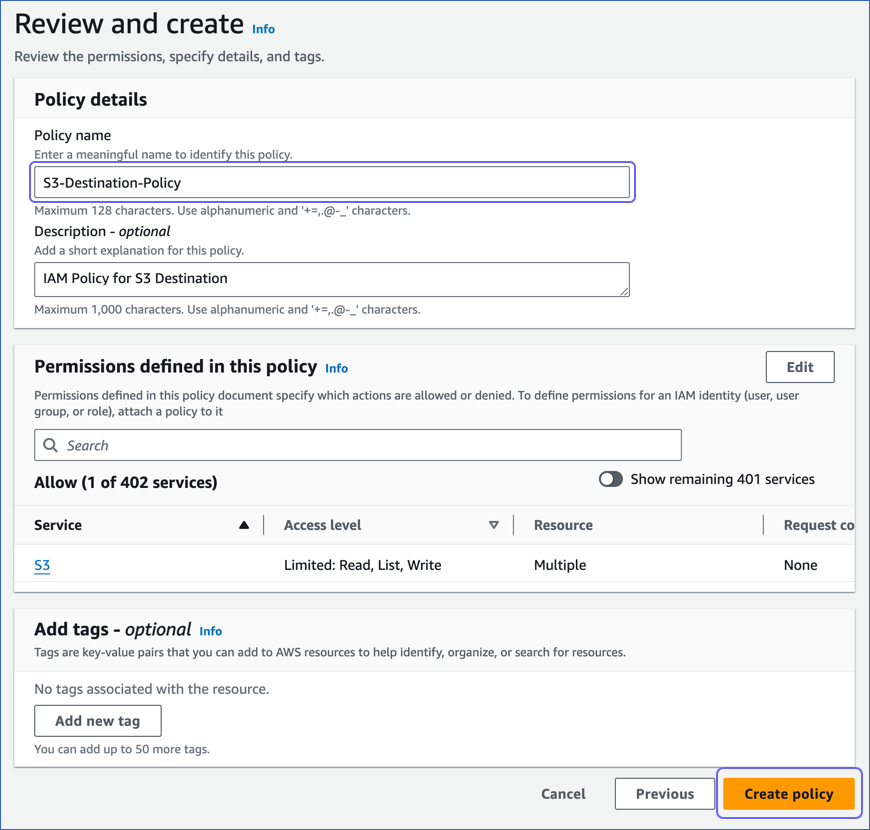
- Create the IAM role to use the policy. Open the AWS Console, and go to IAM. Select the Roles tab.
- Click on create the role. Follow the below-mentioned order:
- AWS service (at the top.)
- RDS (in the middle list, “select a service to view use cases.”)
- RDS — Add Role to Database (towards the bottom in the “Select your use case” section.)
- Click on the “next: permission” button. Attach the permission policies by entering the name of the policy.
- Follow the instructions on the screen. Click on “Review role,” enter the values, and then click on “Create the role.”
Step 5: Push Data from S3 to PostgreSQL Instance
- Open the AWS Console and click on RDS.
- Choose the PostgreSQL instance name.
- Select the IAM roles in the security and connectivity tab and click on “Add IAM Roles.”
- Choose S3_integration in the feature section.
- Click on the “Add Role” button.
- Go to PostgreSQL and run the “aws_s3.table_import_from_s3” command in order to import the CSV file into Postgres.
SELECT aws_s3.table_import_from_s3(
'POSTGRES_TABLE_NAME', 'event_id,event_name,event_value', '(format csv, header true)',
'BUCKET_NAME',
'FOLDER_NAME(optional)/FILE_NAME',
'REGION',
'AWS_ACCESS_KEY', 'AWS_SECRET_KEY', 'OPTIONAL_SESSION_TOKEN'
)
This 5-step process using CSV files is a great way to replicate data effectively. It is optimal for the following scenarios:
- One-Time Data Replication: This method suits your requirements if your business teams need the data only occasionally.
- No Data Transformation Required: This approach has limited options in terms of data transformation. Hence, it is ideal if the data in your spreadsheets is clean, standardized, and present in an analysis-ready form.
- Dedicated Personnel: If your organization has dedicated people who have to manually download and upload CSV files, then accomplishing this task is not much of a headache.
- Ample Information: This method is appropriate for you if you already have knowledge about how to grant IAM access to S3 and where to find your AWS Access key & Secret key.
This task would feel mundane if you had to regularly replicate fresh data from Amazon S3. It adds to your misery when you must constantly transform the raw data. You have to continue going through this lengthy process of moving a CSV file each time. With the increased data sources, you would have to spend a significant portion of your engineering bandwidth creating new data connectors. Just imagine — building custom connectors for each source, transforming & processing the data, tracking the data flow individually, and fixing issues. Doesn’t it sound exhausting?
How about you focus on more productive tasks than repeatedly writing custom ETL scripts, downloading, cleaning, and uploading CSV files? This sounds good, right?
Method 3: Using Python
Prerequisites
Before diving in, make sure you have the following:
- Amazon S3 bucket with the data you want to work with.
- PostgreSQL database ready to store the data.
- Python installed (preferably Python 3.x).
- Libraries like
boto3,pandas, andpsycopg2installed.
Step 1: Setting Up AWS Credentials
First, I needed access to my S3 bucket. I created an IAM user in AWS and downloaded the access and secret keys. I then configured them using the AWS CLI or directly in my Python script.
Here’s how I set up my credentials:
import boto3
# Configure S3 client
s3_client = boto3.client(
's3',
aws_access_key_id='your-access-key',
aws_secret_access_key='your-secret-key'
)Step 2: Downloading Data from S3
Next, I fetched a file from my S3 bucket. For this example, I assumed I had a CSV file in the bucket.
import pandas as pd
bucket_name = 'your-bucket-name'
file_key = 'path/to/your-file.csv'
# Download the file and load it into a DataFrame
response = s3_client.get_object(Bucket=bucket_name, Key=file_key)
data = pd.read_csv(response['Body'])
print(data.head()) # Preview the dataStep 3: Connecting to PostgreSQL
Now, I connected to my PostgreSQL database using psycopg2. Make sure you have the database URL, username, and password handy.
import psycopg2
# PostgreSQL connection details
conn = psycopg2.connect(
host='your-db-host',
database='your-db-name',
user='your-username',
password='your-password'
)
cursor = conn.cursor()
print("Connected to PostgreSQL!")Step 4: Inserting Data into PostgreSQL
Finally, I transferred the data from the Pandas DataFrame to PostgreSQL. I used the to_sql method from Pandas for simplicity, but you can also write raw SQL queries.
from sqlalchemy import create_engine
# Create SQLAlchemy engine for easier integration
engine = create_engine('postgresql+psycopg2://your-username:your-password@your-db-host/your-db-name')
# Write DataFrame to PostgreSQL
data.to_sql('your_table_name', engine, if_exists='replace', index=False)
print("Data transferred successfully!")
What Can You Achieve by Migrating Your Data from Amazon S3 to PostgreSQL?
Here’s a little something for the data analyst on your team. We’ve mentioned a few core insights you could get by this replication. Does your use case make the list?
- Tighter integration of storage and processing – Rather than extracting data from S3 before it can be analyzed, which adds latency, storing it directly in PostgreSQL allows instant access and analysis with SQL queries. This can enable real-time applications.
- Integrating transactional data from different functional groups (Sales, marketing, product, Human Resources) and finding answers. For example:
- Which development features were responsible for an app outage at a given duration?
- Which product categories on your website were most profitable?
- How does the Failure Rate in individual assembly units affect Inventory Turnover?
- Improved analytics performance – Purpose-built database systems like PostgreSQL are optimized specifically for fast aggregations, joins, and analytical queries, whereas object stores like S3 are not.
Read More about: Amazon S3 to RDS
Summing It Up
Using IAM Policy is the right path for you when your team needs data from Amazon S3 once in a while. But with increase in frequency, redundancy will also increase. To channel your time into productive tasks, you can opt-in for an automated solution that will help accommodate regular data replication needs. This would be genuinely helpful to support & product teams as they would need regular updates about customer queries, experiences and satisfaction levels with the product.
Even better, your support teams would now get immediate access to data from multiple channels and thus deliver contextual, timely, and personalized customer experiences.
So, take a step forward. And here, we’re ready to help you with this journey of building an automated no-code data pipeline with Hevo. Hevo’s 150+ plug-and-play native integrations will help you replicate data smoothly from multiple tools to a destination of your choice. Try Hevo’s 14-day free trial feature.
We hope that you have found the appropriate answer to the query you were searching for. Happy to help!
FAQs
1. How to transfer data from S3 to PostgreSQL?
You can use Hevo to easily transfer data from Amazon S3 to PostgreSQL. It automates the process by connecting S3 as the data source and PostgreSQL as the destination.
2. What is the difference between S3 and PostgreSQL?
Amazon S3 is a cloud-based storage service designed for storing large amounts of unstructured data like files, images, and backups. PostgreSQL, on the other hand, is a relational database used to store structured data with relationships between tables
3. How to connect S3 and PostgreSQL?
With Hevo, you can connect Amazon S3 and PostgreSQL in just a few steps. Hevo’s no-code platform allows you to set up S3 as a source and PostgreSQL as a destination.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



