




As a data engineer, you hold all the cards to make data easily accessible to your business teams. Your team just requested a BigCommerce to Redshift connection on priority. We know you don’t wanna keep your data scientists and business analysts waiting to get critical business insights. As the most direct approach, you can go straight for the CSV files exporting if this is a one-time thing. Or, hunt for a no-code tool that fully automates & manages data integration for you while you focus on your core objectives.
Well, look no further. With this article, get a step-by-step guide to connecting BigCommerce to Redshift effectively and quickly, delivering data to your marketing team.
Table of Contents
Methods of Replicating Data from BigCommerce to Redshift:
Method 1: Replicate Data from BigCommerce to Redshift Using CSV
Method 2: Replicate data from BigCommerce to Redshift Using an Automated ETL Tool
Use Hevo’s no-code data pipeline platform, which can help you automate, simplify, and enrich your data replication process in a few clicks. You can extract and load data from 150+ Data Sources, including BigCommerce, straight into your data warehouse, such as Redshift.
Why Choose Hevo?
- Offers real-time data integration which enables you to track your data in real time.
- Get 24/5 live chat support.
- Eliminate the need for manual mapping with the automapping feature.
Discover why BeepKart chose Hevo over Stitch and Fivetran for seamless data integration. Try out the 14-day free trial today to experience hassle-free data replication.
Method 1: Replicate Data from BigCommerce to Redshift Using CSV
- Step 1: You can export the data as CSV or XML file. You can export data of all the objects such as Products, Orders, Customers, E-Commerce, etc.
- Step 2: You can upload the CSV to Redshift using an Amazon S3 bucket. Firstly, you must upload the CSV data to the Amazon S3 bucket. To do so, create a manifest file(preferably gzip file) that contains the data of the CSV file to be uploaded. Once loaded into S3, run the COPY command to pull and get the file from S3 and load it into the desired table. If you have used gzip, your code will be of the following structure:
COPY <schema-name>.<table-name> (<ordered-list-of-columns>) FROM '<manifest-file-s3-url>'
CREDENTIALS'aws_access_key_id=<key>;aws_secret_access_key=<secret-key>' GZIP MANIFEST;
Here the use of the CSV keyword is important as it helps Amazon Redshift to identify the file format. You also need to specify any column arrangements layouts or row headers to be discarded as shown below:
COPY table_name (col1, col2, col3, col4)
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
CSV;
-- Ignore the first line
COPY table_name (col1, col2, col3, col4)
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
CSV
INGOREHEADER 1;
This 2-step process using CSV files is a great way to replicate data from BigCommerce to Redshift effectively. It is optimal for the following scenarios:
- One-Time Data Replication: When your marketing team needs the BigCommerce data only once in a long period of time.
- No Data Transformation Required: If there is a negligible need for data transformation and your data is standardized, then this method is ideal.
In the following scenarios, using CSV files might be cumbersome and not a wise choice:
- Data Mapping: Only basic data can be moved. Complex configurations cannot take place. There is no distinction between text, numeric values, and null and quoted values.
- Two-way Synchronization: To achieve two-way synchronization, the entire process must be run frequently to access updated data on the destination.
- Time Consuming: If you plan to export your data frequently, the CSV method might not be the best choice since it takes time to recreate the data using CSV files.

Method 2: Replicate data from BigCommerce to Redshift Using an Automated ETL Tool
Here, are the following benefits of leveraging a no-code tool:
- Automated pipelines allow you to focus on core engineering objectives while your business teams can directly work on reporting without any delays or data dependency on you.
- Automated pipelines provide a beginner-friendly UI. Tasks like configuring and establishing connection with source and destination, providing credentials and authorization details, performing schema mapping etc. are a lot simpler with this UI. It saves the engineering teams’ bandwidth from tedious preparation tasks.
For instance, here’s how Hevo, a cloud-based ETL tool, makes BigCommerce to Redshift data replication ridiculously easy:
Step 1: Configure BigCommerce as a Source
Authenticate and Configure your BigCommerce Source.
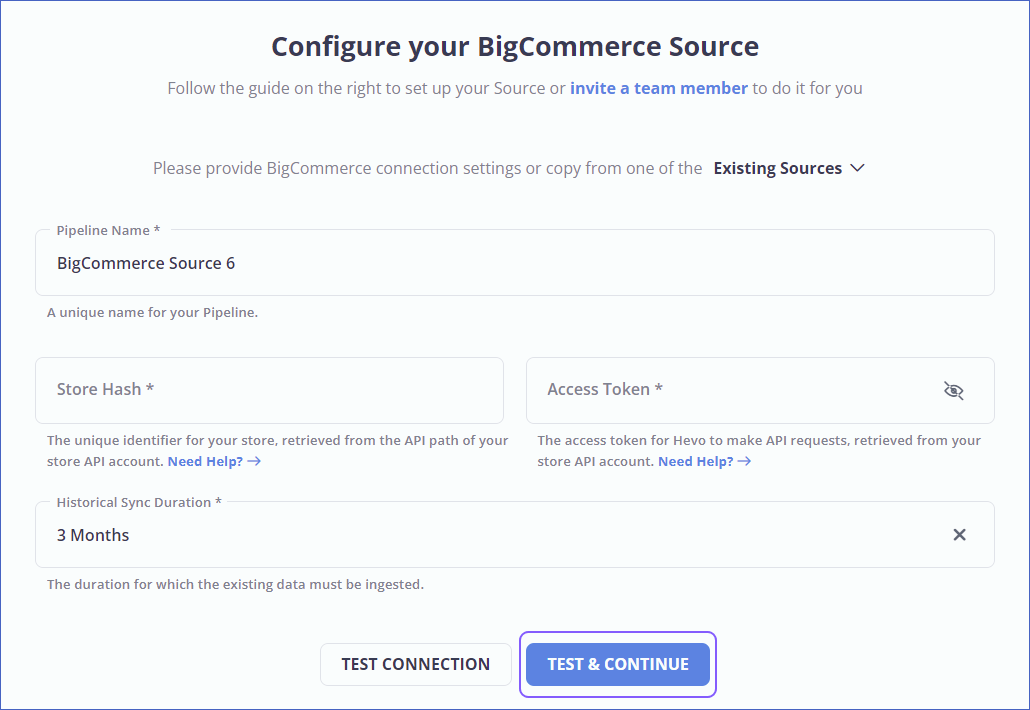
Step 2: Configure Redshift as a Destination
Now, we will configure Redshift as the destination.

Step 3: All Done to Setup Your ETL Pipeline
Once your BigCommerce to Redshift ETL Pipeline is configured, Hevo will collect new and updated data from BigCommerce every five minutes (the default pipeline frequency) and duplicate it into Redshift . Depending on your needs, you can adjust the pipeline frequency from 5 minutes to an hour.
Data Replication Frequency
| Default Pipeline Frequency | Minimum Pipeline Frequency | Maximum Pipeline Frequency | Custom Frequency Range (Hrs) |
| 1 Hr | 15 Mins | 24 Hrs | 1-24 |
What Can You Achieve by Migrating Your Data from BigCommerce to Redshift?
Here’s a little something for the data analyst on your team. We’ve mentioned a few core insights you could get by replicating data from BigCommerce to Redshift. Does your use case make the list?
- What percentage of customers from a region have the most engagement with the product?
- Which features of the product are most popular in a country?
- Your power users are majorly from which location?
- What are the custom retention trends over a period of time?
- What is the trend of a particular feature adoption with time?
You can also take a look at how you can easily move your BigCommerce data to other destinations, such as Google BigQuery.
Summing It Up
Exporting and importing CSV files is the right path for you when your team needs data from BigCommerce once in a while. However, an ETL solution becomes necessary if there are rapid changes in the source and frequent data replication needs to be done to meet data demands of your product or marketing channel. You can free your engineering bandwidth from these repetitive & resource-intensive tasks by selecting Hevo’s 150+ plug-and-play integrations.
Saving countless hours of manual data cleaning & standardizing, Hevo’s pre-load data transformations get it done in minutes via a simple drag n drop interface or your custom python scripts. Try a 14-day free trial to explore all features, and check out our unbeatable pricing for the best plan for your needs.
Frequently Asked Questions
1. What kind of insights can I gain from this integration?
This can be as informative as knowing the trends in sales, customer behavior, and inventory levels so that one can understand much to do with strategic planning and optimizing operations.
2. Is coding required for integration?
Generally, ETL tools require less coding as it provides a relatively friendly user interface. However, if you opt for the custom API-based approach, then some knowledge of programming is required for the purpose of data extraction and loading.
3. Why integrate BigCommerce with Redshift?
It allows an effective eCommerce data analysis to be used for data-driven decisions aimed at improving marketing and sales strategies.
Share your experience of replicating data from BigCommerce to Redshift! Let us know in the comments section below!

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link










