




Braintree is one of the most popular payment gateway payment systems for mobile and web transactions. It provides advanced features like chargebacks and fraud detection to secure online payment processing. With options to accept bank transfers and ACH with a reduced transaction fee for recurring donations, Braintree is a leading candidate for processing payments for nonprofits.
Since vast payment data is on these online platforms, you can draw insights by connecting Braintree to Redshift. Redshift supports multi-cloud infrastructure environments and enables quick and efficient data analysis by running its queries on multiple compute clusters.
This article discusses the two integration methods you can use for Braintree to Redshift migration.
Table of Contents
What is Braintree?
Braintree is an online payment gateway owned and operated by PayPal since 2013. However, it features additional payment methods, some of which are not supported by Paypal. It is an excellent option for businesses seeking a merchant account with a no-cost PayPal integration. Braintree offers web technology solutions to enterprises for their mobile and web payments. It is a full-stack platform that does not necessitate traditional models of sourcing payment gateways.
Braintree services cover international payments, reduced nonprofit transaction rates, affordable rates for ACH deposits, and credit card data portability. An existing merchant can obtain customer information and credit card data upon request in a PCI-compliant manner.
If you are interested in availing of Braintree services, it offers a “sandbox” version that lets you try the software without creating a merchant account. To use Braintree services, you can later sign up with an official ID, address proof, bank statements, and IRS SS4 letter.
What is Amazon Redshift?
Amazon Redshift is a cloud-based and fully managed petabyte-scale Data Warehousing service. It enables you to begin with a few gigabytes of data and scale up to a petabyte or more. Amazon Redshift organizes data into clusters that can be examined simultaneously. As a result, Amazon Redshift data may be retrieved quickly and easily. Users and apps can access each node independently.
Amazon Redshift can be utilized with a variety of SQL-based clients, as well as a variety of Data Sources and Data Analytics tools. It has a solid architecture that makes interacting with a variety of business intelligence tools a breeze.
Each Amazon Redshift Data Warehouse is fully managed, which means administrative chores such as backup creation, security, and setup are all handled automatically.
What are the Methods to Connect Braintree to Redshift?
Integrating Braintree to Redshift opens doors for in-depth analysis in a no-shared architecture of virtual warehouses. You can carry out multiple computations simultaneously without compromising on resources and efficiency.
Method 1: Connect Braintree to Redshift using Hevo Data
Hevo enables you to seamlessly integrate data from Braintree to Redshift in real-time, with no code necessary. Its data pipeline enriches and transfers your data automatically and securely.
Method 2: Manually Connect Braintree to Redshift
This method lets you extract, process, and load data into Redshift using APIs and SQL queries. It requires technical knowledge and takes a lot of time.
Method 1: Connect Braintree to Redshift using Hevo Data
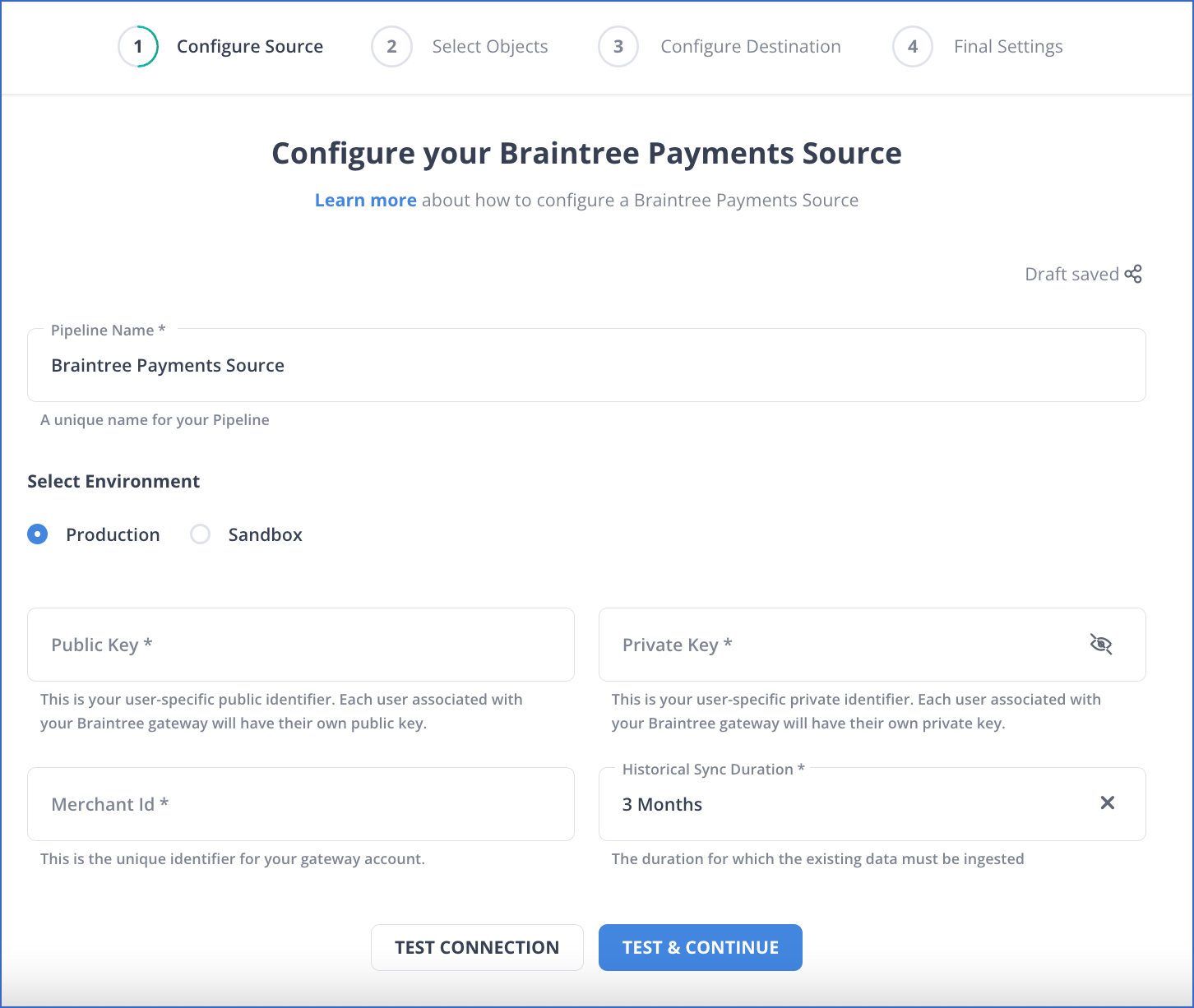
Configure Braintree as the Source
To configure Braintree as a source in Braintree to Redshift Integration, follow the steps given below:
- To configure Braintree as a source in Braintree to Redshift Integration, follow the steps given below:
- Step 1.1: Click PIPELINES in the Asset Palette.
- Step 1.2: Next, click +CREATE in the Pipelines List View to connect Braintree to Redshift.
- Step 1.3: Then, on the Select Source Type page, select Braintree Payments.
- Step 1.4: In the Configure your Braintree Payments Source page in Braintree to Redshift Integration.
- Step 1.5: Click TEST & CONTINUE to complete Braintree to Redshift Connection.
Configure Redshift as a Destination
To set up Amazon Redshift as a destination in Braintree to Redshift Connection, follow these steps:
- Step 2.1: In the Asset Palette, select DESTINATIONS.
- Step 2.2: In the Destinations List View, click + CREATE to connect Braintree to Redshift.
- Step 2.3: Select Amazon Redshift from the Add Destination page.
- Step 2.4: Set the following parameters on the Configure your Amazon Redshift Destination page.
- Step 2.5: To test connectivity with the Amazon Redshift warehouse, click Test Connection in Braintree to Redshift Connection.
- Step 2.6: When the test is complete, select SAVE DESTINATION to finish Braintree to Redshift Integration.

Method 2: Manually Connect Braintree to Redshift
To connect Braintree to Redshift manually, follow the steps given below:
Extracting Data From Braintree
The first step in Braintree to Redshift Connection is extracting data from Braintree. Braintree, much like other payment gateways, makes its application programming interface (API) available to developers so that its products can be integrated with various forms of payment. The following are some of the clients or SDKs that Braintree provides in order to gain access to this API:
Client SDKs:
- iOS
- Android
- Web/Javascript
Server SDKs:
- Ruby
- Python
- PHP
- JS
- Java
- .NET
Preparing the Data
The next step in Braintree to Redshift Integration is to prepare the data. Amazon Redshift is designed to manage very large datasets and provide high-performance analysis. It is built on top of the industry-standard query language SQL and includes additional functionality. You will need to follow its data model, which is a typical relational database model, in order to load your data into it so that it can be accessed.
You should map the data that you extract from your data source into tables and columns after you have done so. In this case, you can think of the table as a map that leads to the resource that you want to store, and the columns will be the attributes of that resource.
You need to be careful about the data that you feed into Amazon Redshift and make sure that you have mapped your types into one of the data types that are supported by Amazon Redshift. This is because your data are probably coming in a representation such as JSON, which supports a much smaller range of data types. The process of designing a Schema for Amazon Redshift and mapping the data from your data source to it is one that you should take seriously because it has the potential to affect both the performance of your cluster as well as the questions you are able to answer.
When designing an Amazon Redshift database, it is always a good idea to keep in mind the best practices that Amazon has published regarding the structure of the database. As soon as you have reached a decision regarding the structure of your database, you will need to load your data onto one of the data sources that Redshift is able to accept as input. These data sources are as follows:
- Amazon S3
- Amazon DynamoDB
- Amazon Kinesis Firehose
Loading Data into Redshift
The last step in Braintree to Redshift Connection is to load the data into Amazon Redshift. Amazon Redshift allows users to load data using one of two different methods. The first way is to carry out an operation known as an INSERT command. You can perform an INSERT command for your data after connecting your client to your Amazon Redshift instance using either a JDBC or an ODBC connection. You have the option of using either one of these connections.
insert into category_stage values
(12, 'Concerts', 'Comedy', 'All stand-up comedy performances');Amazon Redshift is not intended to be used for operations similar to INSERT. On the contrary, the most time- and resource-effective method for loading data into Redshift is to perform bulk uploads using the COPY command. You can use the COPY command to copy data that is stored in flat files on S3 or that comes from a table in Amazon DynamoDB. Amazon Redshift is able to read multiple files simultaneously when you perform COPY commands, and it automatically distributes the workload to the cluster nodes and performs the load in parallel.
This is made possible by the fact that Amazon Redshift is able to read multiple files in parallel. The COPY command is extremely versatile and can be used in a variety of different ways, depending on the context in which it is being applied. The following command is all that is required to perform a COPY operation on Amazon S3 to connect Braintree to Redshift:
copy listing
from 's3://mybucket/data/listing/'
credentials 'aws_access_key_id=;aws_secret_access_key=';Limitations of Connecting Braintree to Redshift Manually
Unfortunately, there are no direct ways for a non-technical person to connect Braintree to Redshift. It is, however, feasible to retrieve Braintree data manually and then importing to Redshift. The above steps to fetch Braintree data seem convenient, but it will take a lot of time if you manually search and download the required data.
Additionally, you will have to do the same repeatedly for each section in Braintree to Redshift Connection, Vault, Verifications, Subscriptions, etc. Manual integration of Braintree to Redshift is, therefore, a time-ineffective process. This is why you may opt for assistance from low-code or no-code integration service providers like Hevo, which can work as a connector for Braintree and Redshift.

What can you achieve by replicating data from Braintree to Redshift?
By migrating your data from Braintree to Redshift, you will be able to help your business stakeholders find the answers to these questions:
- How does CMRR (Churn Monthly Recurring Revenue) vary by Marketing campaign?
- How much of the Annual Revenue was from In-app purchases?
- Which campaigns have the most support costs involved?
- For which geographies are marketing expenses the most?
- Which campaign is more profitable?
- How does your overall business cash flow look like?
- Which sales channel provides the highest purchase orders?
Conclusion
This article discusses two online solutions: Braintree, a web payment gateway that provides user-friendly interfaces for businesses to receive payments online, and Redshift, a cloud data warehouse, and how to connect Braintree to Redshift. Amazon Redshift can enhance your data analysis by providing secure and controlled data access throughout the enterprise. However, you need to fetch Braintree data using third-party ETL tools and store it in Redshift, as manually integrating would only bring several data quality issues.
However, as a Developer, extracting complex data from a diverse set of data sources like Databases, CRMs, Project management Tools, Streaming Services, and Marketing Platforms to your Database can seem to be quite challenging. If you are from non-technical background or are new in the game of data warehouse and analytics, Hevo can help!
FAQ
How do I transfer data to Databricks?
You can transfer data to Databricks by uploading files directly through the Databricks interface, using connectors to cloud storage services like AWS S3 or Azure Blob Storage, or using ETL tools like Apache Airflow, Hevo Data, or Talend for automated data pipelines.
What type of data is stored in BrainTree?
Braintree primarily stores payment-related data, including transaction details (amounts, dates, payment methods), customer information (names, emails, billing addresses), and data for recurring billing and subscriptions.
How can I connect Braintree to Databricks?
To connect Braintree to Databricks, you can use Braintree’s API to extract data programmatically. You would need to set up an API connection using a programming language like Python or Java, retrieve the data, and then load it into Databricks via a suitable data format (e.g., CSV, JSON) or directly using a data connector.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



