

 Key Takeaways
Key TakeawaysLoading CSV data into BigQuery usually involves selecting the right ingestion method based on file size, automation needs, and how often the data needs to be updated. While manual options work for small or one-time uploads, automated approaches are better suited for recurring or large-scale workloads.
Method 1: Automated Pipelines
Best for recurring or production-grade ingestion. Automated pipelines handle schema changes, retries, and ongoing updates with minimal manual effort.
Method 2: BigQuery Web UI
Works well for quick tests, proofs of concept, or small one-time CSV uploads. Offers a simple, no-code interface with schema auto-detection.
Method 3: bq CLI or Client Libraries
Suitable for teams with scripting or programming expertise that need more control over how CSV data is loaded and managed programmatically.
Method 4: Google Cloud Storage with SQL LOAD DATA
Ideal for large CSV files stored in Cloud Storage. This approach improves reliability and performance and fits SQL-driven workflows.
Loading CSV data into BigQuery is a common starting point for analytics and reporting. While uploading a file may seem simple, teams often run into questions around schema detection, file size limits, load configurations, and the right tools to use.
Whether you are performing a one time analysis, importing external datasets, or building a repeatable data workflow, the method you choose to load CSV files into BigQuery impacts reliability, scalability, and ongoing maintenance.
This guide walks through the most practical ways to load CSV data into BigQuery, from manual uploads to automated, production-ready pipelines, so you can select the approach that best matches your data volume, automation requirements, and technical experience.
Below, you will also find a short walkthrough video demonstrating how a CSV to BigQuery load works in practice.
Table of Contents
Prerequisites for Loading CSV Data into BigQuery
Before loading CSV files into BigQuery using any of the methods covered in this guide, make sure you have the following in place:
- A Google Cloud Platform (GCP) account with access to BigQuery
- A BigQuery dataset created in the target GCP project
- Required permissions, such as:
- BigQuery Data Editor or BigQuery Admin
- BigQuery Job User (to run load jobs)
- A well-formatted CSV file, including:
- A consistent delimiter (comma by default)
- A single header row (if applicable)
- Consistent data types across rows
Top Methods To Load Data From CSV to BigQuery
- Method 1: How to load CSV Data into BigQuery Using Hevo Data
- Method 2: How to load CSV Data into BigQuery Using Command Line Interface
- Method 3: How to load CSV Data into BigQuery Using BigQuery Web
- Method 4: How to load CSV Data into BigQuery Using Web API
- Method 5: How to load CSV into BigQuery from Google Cloud Storage
Method 1: How to load CSV Data into BigQuery Using Hevo Data
Hevo’s no-code data pipeline makes it easy to connect Google Sheets to BigQuery without writing scripts or worrying about maintenance. The setup takes just a few minutes.
Step 1: Configure Google Sheets as your Source.
- Select Google Sheets in Hevo and provide access permissions.
- Choose the sheet(s) you want and set refresh intervals for near real-time sync.

Step 2: Configure BigQuery as your Destination details
- Pick BigQuery as your target, enter project details, and select the dataset.
- Hevo auto-maps the schema, so no manual setup is required.

After the pipeline has completed ingesting, you can preview your loaded table by opening BigQuery and previewing it. Once configured, Hevo continuously syncs your Sheets data into BigQuery. You can preview loaded tables in the BigQuery console and start querying or building dashboards instantly.
Seamlessly migrate your data to BigQuery. Hevo elevates your data migration game with its no-code platform. Ensure seamless data migration using features like:
- Seamless integration with your desired data warehouse, such as BigQuery.
- Transform and map data easily with drag-and-drop features.
- Real-time data migration to leverage AI/ML features of BigQuery.
Join 2000+ users who trust Hevo for seamless data integration, rated 4.7 on Capterra for its ease and performance.
Get Started with Hevo for FreeMethod 2: How to load CSV Data into BigQuery Using Command Line Interface
Step 1: Google Cloud Setup
First, install the gcloud command line interface. Authenticate yourself to Google Cloud. For that, run the command we have given below. Then, sign in with your account and give all permissions to Google Cloud SDK.
gcloud auth loginAfter you complete all these steps, this window should appear:

Step 2: Command Prompt Configurations
First, run this command bq to enter in Google’s BigQuery configuration. Now, to check the number of datasets in your projects, run this command:
bq ls <project_id>: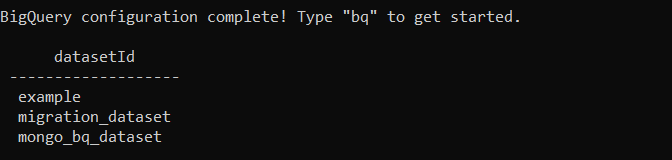
This is a method to create a new dataset. In order to do so, you can run the command:
Bq mk <new_dataset_name>

Step 3: Load the data into the dataset
First, go to your cloud SDK directory and add the CSV file that you want to upload. We have uploaded a picture of our directory for reference. Now, to load the file, go back to your command line and run the command we have provided below. The output of this command will be “Upload Complete”.
bq load --source_format=CSV example_cli.bank demo.csv ID: integer,NAME:string,AGE:integer
Step 4: Preview of the data
First, check whether the table has been created. You can use the following command:
bq ls example_cli
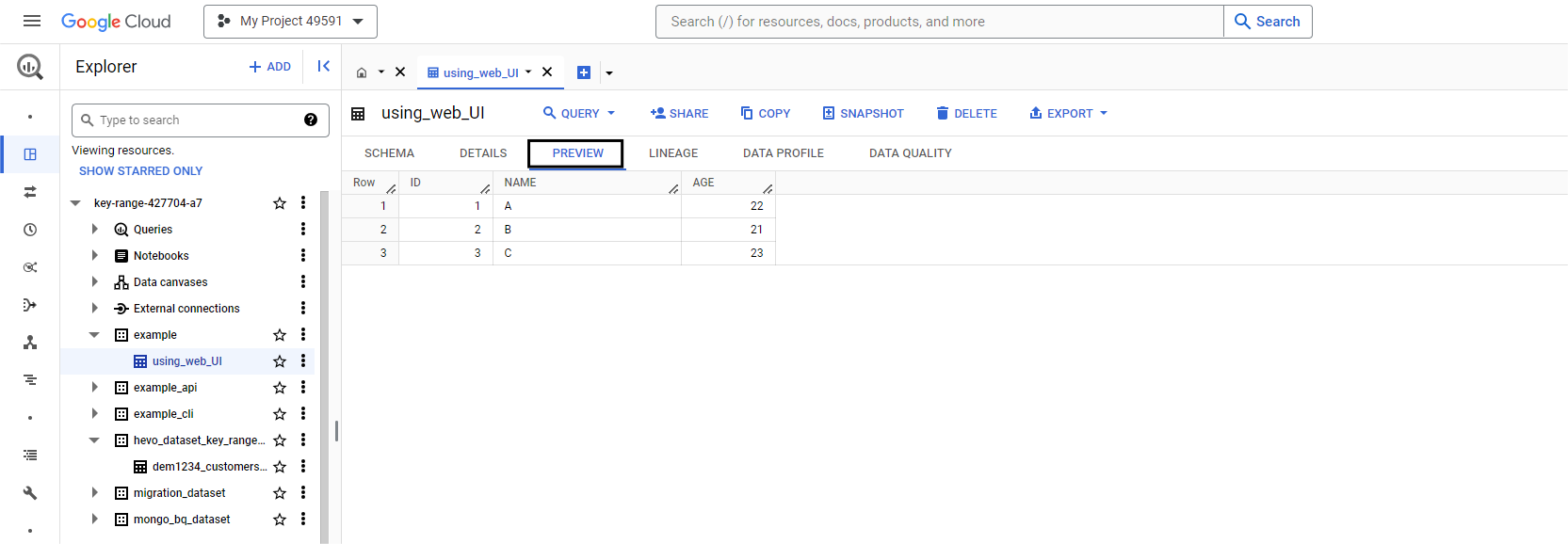
If you want to see the schema of the table, you can do so by using the command below. To preview your table, go back to BigQuery, go to tables, and click on preview.
bq show <dataset_name>.<table_name>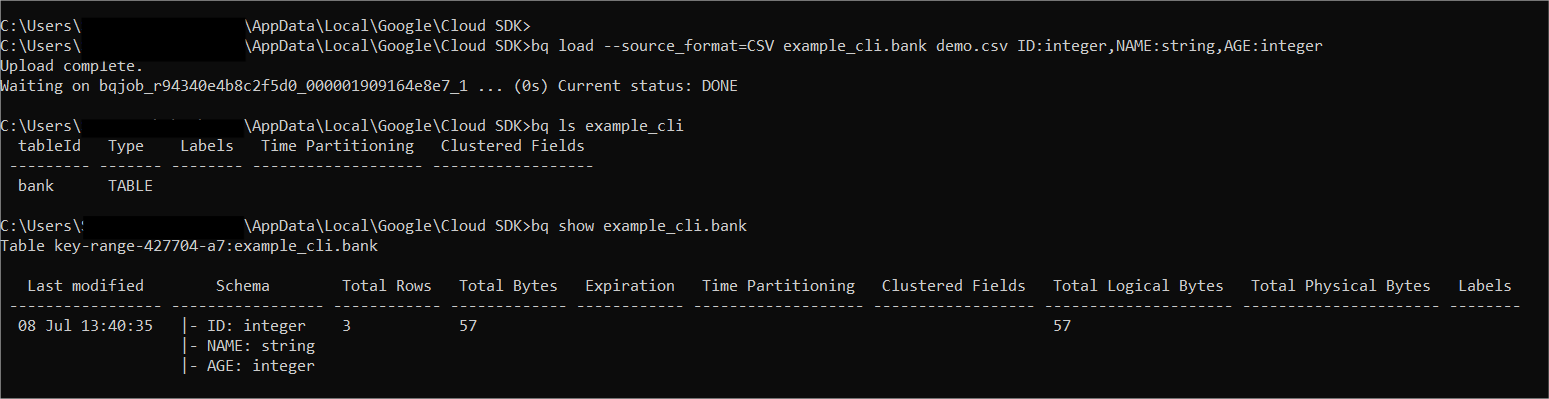
Method 3: How to load CSV Data into BigQuery Using BigQuery Web
Step 1: Create a new Dataset
To create a new dataset in BigQuery, go to your BigQuery studio, click on the three dots beside your project ID, and click Create Dataset.
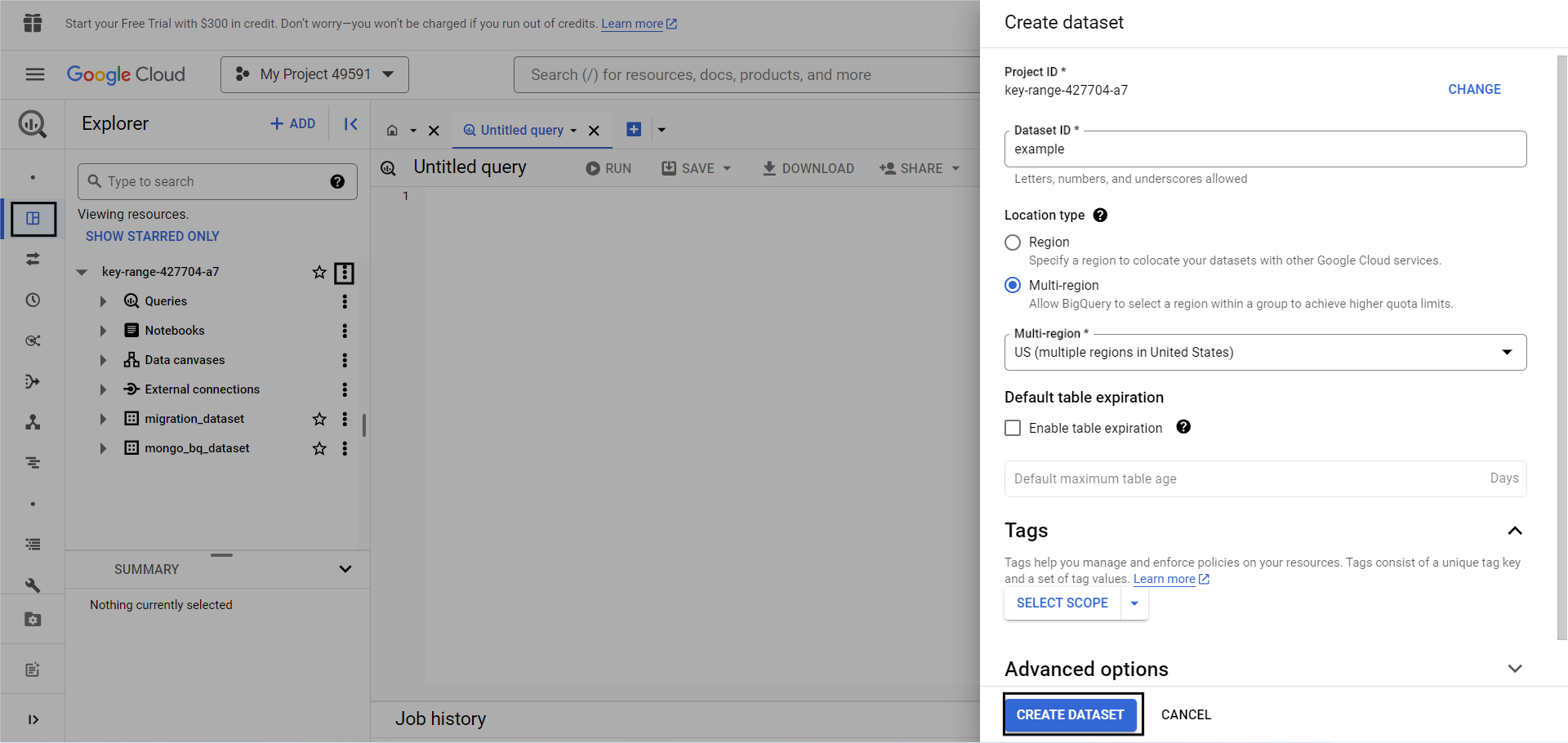
Step 2: Create a Table
To create a new table, click on the three dots next to your dataset name and click on Create Table.
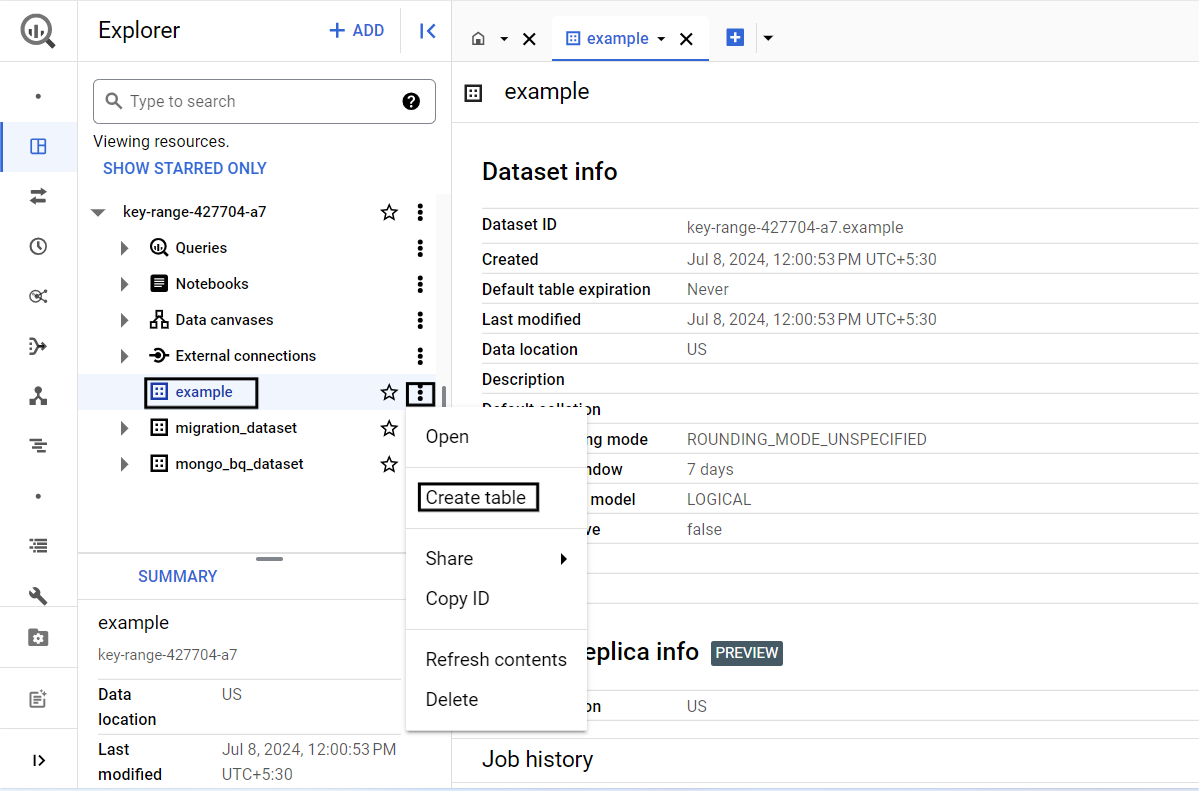
Note:
- Keep the file format as CSV.
- Turn on auto-detect. This will automatically detect the incoming table schema and generate a schema accordingly.
- Change create table ” to Upload”. Upload the file that you want to load into BigQuery.
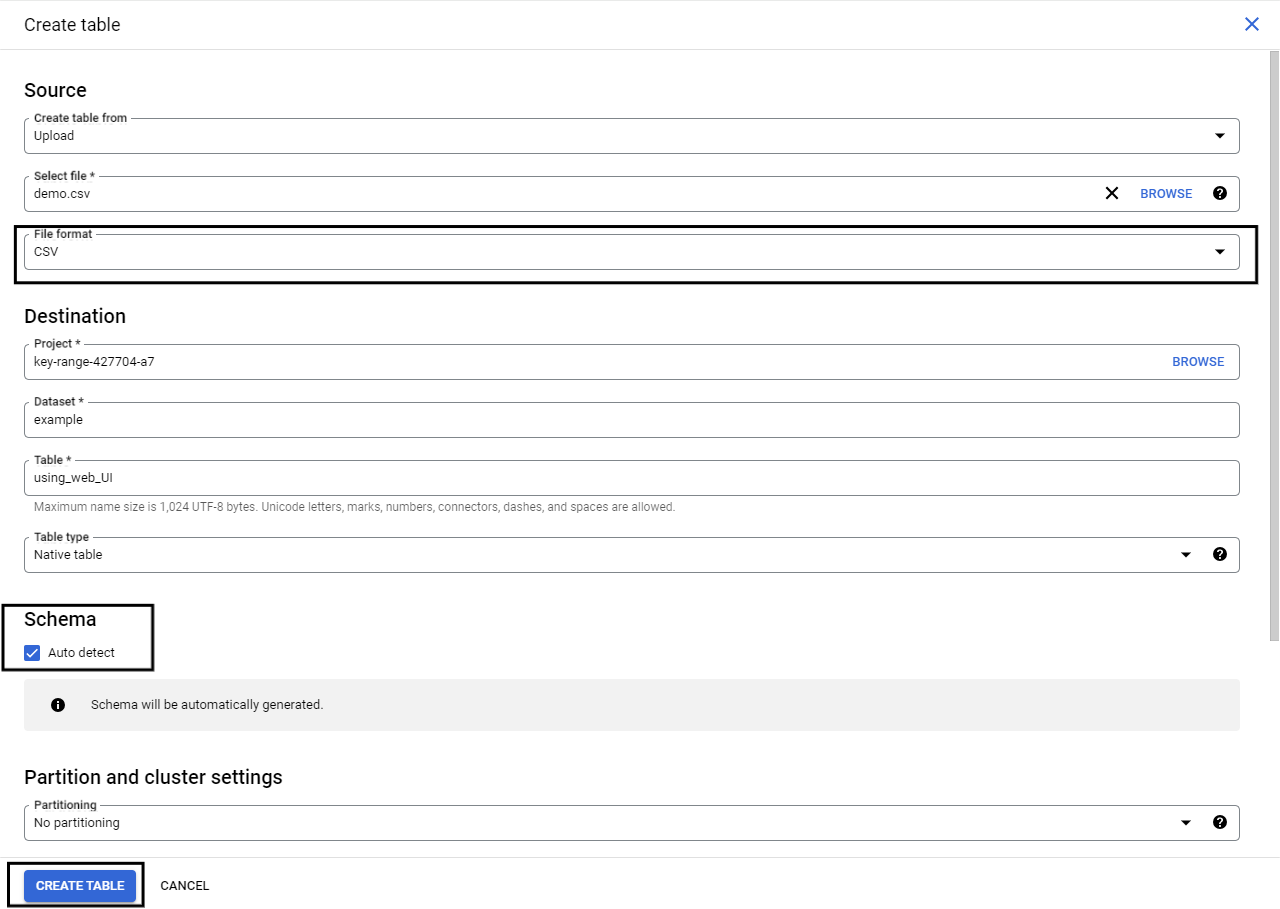
Step 3: Preview Table
- You can edit the schema you just created. To do so, click on the table name and click on the schema tab. You can make changes to the schema as you like from here, and finally, click on edit schema.
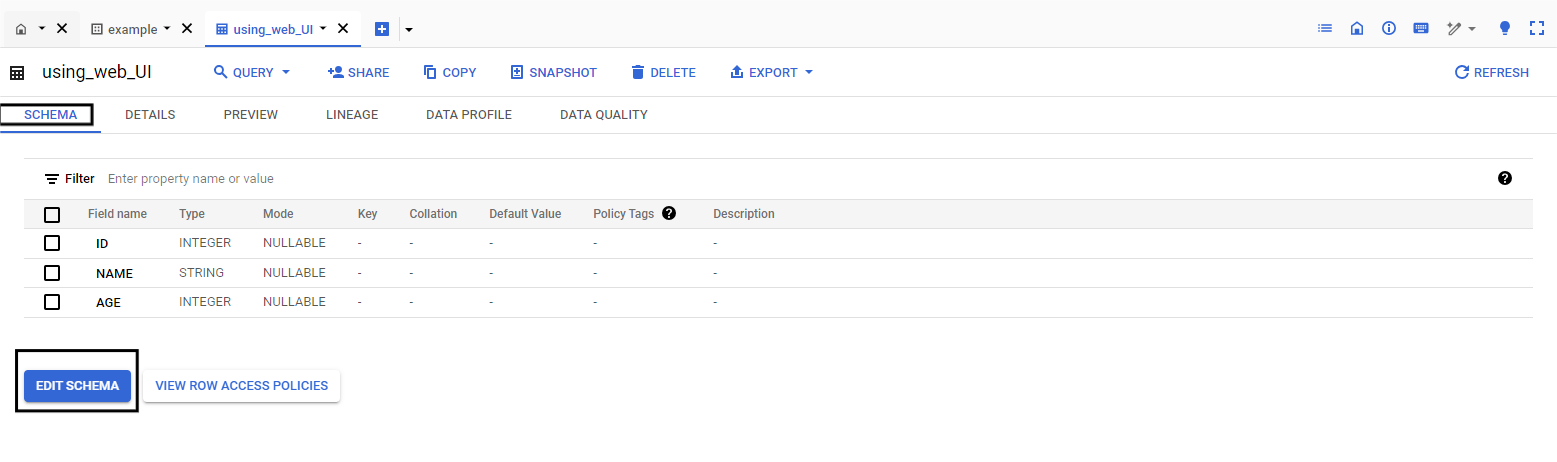
- To preview the table, click on the “preview tab” beside the details tab.
Method 4: How to load CSV Data into BigQuery Using Web API
Step 1: Configure BigQuery API
Go to Google Cloud Console and look for APIs and services. Search for BigQuery and click on BigQuery API.
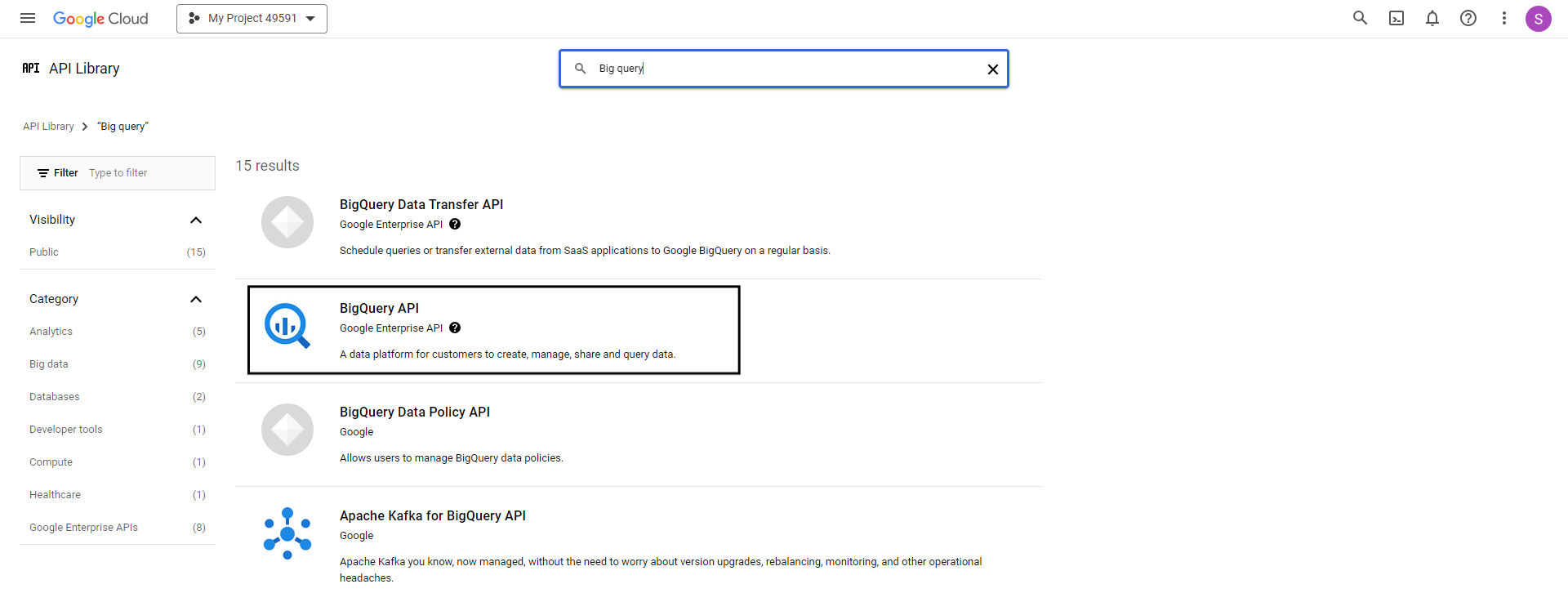
Note: Make sure that the service is enabled.
Step 2: Configuring the Python script
Open your code editor and type the given Python script.
from google.cloud import bigquery
import os, time
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your-service-account.json'
client = bigquery.Client()
table_id = 'your-project.your_dataset.your_table'
job_config = bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.CSV,
skip_leading_rows=1,
autodetect=True,
)
with open('demo.csv', 'rb') as source_file:
job = client.load_table_from_file(source_file, table_id, job_config=job_config)
job.result() # Waits for the job to complete
table = client.get_table(table_id)
print(f"Loaded {table.num_rows} rows and {len(table.schema)} columns to {table_id}")
Note:
- In Google application credentials, provide your service account’s json key.
- In
table_id.Give a new table name for what you want to create.
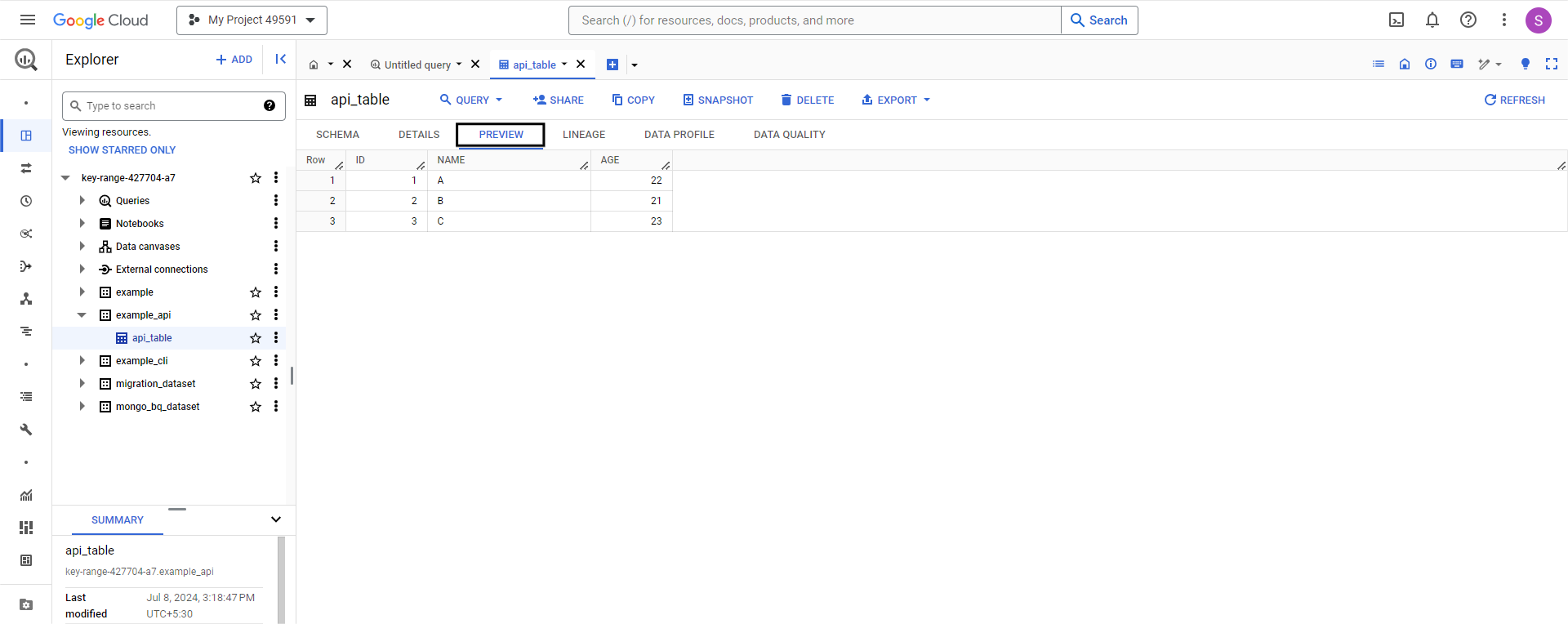
Step 3: Preview the table
You can now preview the table you created by following the steps mentioned in this blog.
Learn more on How to unload and Load CSV to Redshift and Import CSV File Into PostgreSQL Table
Method 5: How to Load CSV Data into BigQuery from Google Cloud Storage (GCS)
This method involves uploading your CSV file to Google Cloud Storage and then loading it into BigQuery. It is the recommended approach for large files and production workloads.
Step 1: Create or Select a Google Cloud Storage Bucket
- Log in to the Google Cloud Console.
- Navigate to Cloud Storage → Buckets.
- Create a new bucket or select an existing one.
- Choose the appropriate:
- Project
- Region
- Storage class
Step 2: Upload the CSV File to GCS
- Open the selected bucket.
- Click Upload files.
- Select your CSV file from your local system.
- Wait for the upload to complete.
You will now have a GCS URI in the format:
gs://your-bucket-name/your-file.csvStep 3: Open BigQuery in the Google Cloud Console
- Go to BigQuery in the Google Cloud Console.
- In the Explorer panel, select your target project.
- Choose an existing dataset or create a new one.
Step 4: Create a New Table from GCS
- Click Create table.
- Under Create table from, select Google Cloud Storage.
- In the Select file from GCS bucket field, enter the GCS URI of the CSV file.
Step 5: Configure Source and Destination Settings
- File format: CSV
- Destination table name: Provide a new table name
- Schema:
- Enable Auto-detect to let BigQuery infer the schema, or
- Define the schema manually for precise control
Step 6: Configure Advanced CSV Options (Optional)
Adjust settings as needed:
- Skip header rows (usually set to 1)
- Specify field delimiter (comma by default)
- Enable quoted newlines if the CSV contains line breaks within fields
- Choose write disposition:
- Append to table
- Overwrite table
- Write only if table is empty
Step 7: Load the Data
- Click Create table.
- BigQuery starts a load job.
- Monitor job status in the Job history panel.
Step 8: Validate the Loaded Data
- Check for rejected records or schema mismatches.
- Run a SELECT query on the new table.
- Verify row counts and column values.

Why move data from CSV to BigQuery?
- Scalability: Features like real-time analytics, on-demand storage scaling, BigQuery ML, and optimization tools make it easier to manage and scale your data analysis processes as needed.
- Enhances overall efficiency: Uploading CSV files to BigQuery simplifies data management and enhances the efficiency of your analytical workflows, making it easier to handle and analyze large datasets.
- Performance: BigQuery is designed to handle massive volumes of data efficiently, offering quick query execution that reduces the time needed to gain insights from your data.
- Advanced Analytics: BigQuery provides advanced analytics tools, such as ML and spatial data analysis, which deliver deeper insights to inform wise decision-making.
- Cost-Effective: BigQuery’s pay-as-you-go pricing approach ensures you only pay for the storage and queries you use, eliminating the need for expensive hardware or software.
Conclusion
Loading CSV data into BigQuery may start as a simple task, but it quickly becomes more complex as file sizes grow, schemas evolve, and refresh frequency increases. Choosing the right approach early can reduce manual effort, prevent data inconsistencies, and make your ingestion workflows more reliable over time.
For teams that need repeatable and low-maintenance CSV ingestion, manual uploads and custom scripts often introduce operational overhead around monitoring, retries, and schema handling.
This is where Hevo Data fits naturally. When CSV data is available through supported cloud storage or file-based sources, Hevo provides a fully managed, no-code way to load data into BigQuery. It handles schema detection, pipeline monitoring, and automated loading, so teams can focus on analytics instead of maintaining ingestion workflows.
Sign up for a 14-day free trial and try it yourself now!
FAQ
1. How do I append a CSV file to a BigQuery table?
You can append additional data to an existing table by performing a load-append operation.
2. What is the fastest way to load data into BigQuery?
Bulk Insert into BigQuery is the fastest way to load data.
3. How to connect data to BigQuery?
On your computer, open a spreadsheet in Google Sheets.
In the menu at the top, click Data Data connectors. Connect to BigQuery.
Choose a project.
Click Connect.
4. How do I export CSV to storage in BigQuery?
Open the BigQuery page in the Google Cloud console. In the Explorer panel, expand your project and dataset, then select the table. In the details panel, click Export and select Export to Cloud Storage.
5. How do I import large CSV files into BigQuery?
For large CSV files, you can use the Google Cloud CLI (bq load) or Hevo Data for automated real-time ingestion. Avoid gzip-compressed CSVs over 4 GB, as BigQuery has limitations with compressed files.
6. What formats besides CSV can be loaded into BigQuery?
BigQuery supports formats like JSON, Avro, Parquet, ORC, and AVRO, but CSV remains the most common for simple table imports.
7. Does BigQuery support nesting, repetitive data, and BOM characters in CSV files?
No. CSV files cannot include nested or repeated data, and any BOM (byte order mark) characters should be removed before loading, as they may cause unexpected errors.
8. How does gzip compression affect loading CSV data into BigQuery?
BigQuery cannot read gzip-compressed CSV files in parallel, so loading them takes longer than uncompressed files. Additionally, you cannot mix compressed and uncompressed files in the same load job.
9. What is the maximum size limit for a gzip-compressed CSV file in BigQuery?
A single gzip file can be up to 4 GB. Larger datasets must be split into multiple gzip files before loading.
Share your thoughts on loading data from CSV to BigQuery in the comments!
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





