



Do you have a fascination with Databricks architecture but you get lost with all the terms being used out there? Let’s break it down simply! If you are just getting familiar with cloud computing or just need a refresher, in this blog, let’s try distilling the key aspects of Databricks architecture in simple, easy-to-understand concepts. We shall proceed to examine the major parts of the platform, give details on what sets the platform apart, and provide answers to some frequently asked questions.
Table of Contents
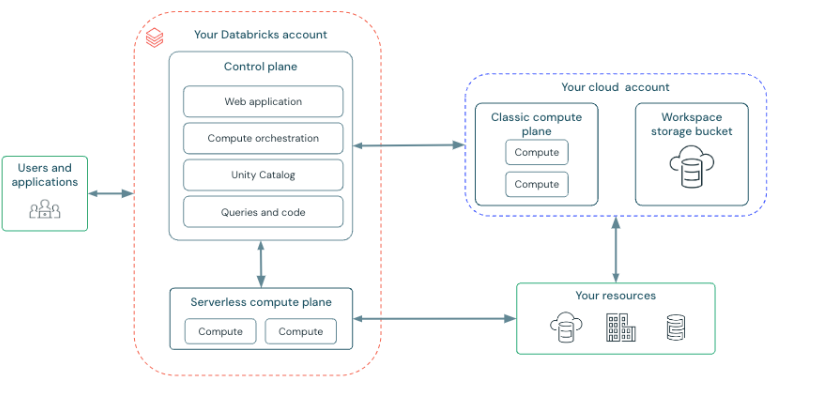
What is Databricks Architecture?
To address it in simple terms, Databricks architecture is the plan of its working and data flow in which Databricks exists. Note that Databricks itself is a cloud-based collaborative data science platform that enables users to work with both data warehouses, which serve as repositories for structured data, and data lakes, used for handling all kinds of data. This combination is called a Lakehouse architecture and allows working with all types of data without negatively impacting speed and convenience.
In other words, what Databricks is doing is, that it’s like your one-stop solution for anything and everything data and related work, be it engineering, data science, or even if you are creating ML models.
Are you looking for ways to connect Databricks with Google Cloud Storage? Hevo has helped customers across 45+ countries migrate data seamlessly. Hevo streamlines the process of migrating data by offering:
- Seamlessly data transfer between Salesforce, Amazon S3, and 150+ other sources.
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
- In-built transformations like drag-and-drop to analyze your CRM data.
Don’t just take our word for it—try Hevo and experience why industry leaders like Whatfix say,” We’re extremely happy to have Hevo on our side.”
Get Started with Hevo for FreeCore Components of Databricks Architecture
Databricks architecture involves the following few core components, although they may have their specific responsibilities. Here’s a breakdown:
1. Workspace
Consider your work environment as a headquarters where your team deliberates and completes the work. It is not just a place to earn money, for people to be sitting around doing their thing, or get things done. At its core, the workspace proves useful for data engineers, scientists, or simply anyone who needs to better understand what someone else does. you can enhance your Workspace experience by leveraging Databricks SQL for data analysis.
Here’s the magic of it:
- You’ve got shared notebooks, dashboards, and files altogether. None of that searching with the hope of finding where that one file was again.
- It is designed for collaboration, so everybody has everything they need to manage to increase efficiency rather than trying to reduce the workload.
- And frankly, that just creates less hassle for everybody. They can just concentrate on the content, and its comprehensiveness and efficacy as a tool and a business-analysis workhorse without worrying about losing what they have.
Perhaps it is something like always having a friend who is a super slob pick up their things before inviting you over. Sounds good, right?
2. Data Lake Integration
This is where your data resides untouched, unadulterated, and waiting for something to be done with it! Databricks works well with cloud storage platforms such as AWS S3 or Azure Data Lake which gives you an opportunity to store any kind of data (relational and non-relational). With data lake integration, you can get access to your data anytime and from any place of your convenience. Understand how Data Lake Integration is structured using the Medallion Architecture.
3. Compute Resources (Clusters)
Clusters are the “powerhouse” of Databricks Everything concerning computation is managed by clusters: all the work related to data processing takes place here. Due to workload, calculations, certain code, or machine learning, Databricks clusters adjust their size, and managing that is time-saving and relatively cheaper.
4. Job Scheduling
This shows how important the degree of automation is in the continued proper running of datasets. In job scheduling, you may schedule such tasks as data ingestion or data transformation tasks where you bring in new data or clean and organise existing data. This keeps everything perfectly fine-tuned and on ready to make your data fresh and available for analytical purposes.
Why Choose Databricks? Key Features That Stand Out
Essentially, Databricks is more than another data platform. Here’s what makes it unique and why so many companies are embracing it:
- Unified Platform: Databricks provides a single environment to address a wide spectrum of data-related processes relevant to a typical enterprise – thus bridging the gap of having to deal with multiple tools. Every step of the pipeline, from designing big data pipelines, and building and training ML models, to doing complex analytics can be accomplished in Databricks. On top of this, it also makes it cleaner to organize tasks and collaborate, which is amassed within one application for data engineers, data scientists, and analysts.
- Scalability: Databricks’ primary proposition is scalability. One of the problems of big data processing is the distribution of the computational force required for analyzing records. It erases this pain by being able to take advantage of the cloud-based clusters that can scale up or down as they are used. It is this self-orchestrating mechanism that allows even extremely large paradigms to be addressed with simplicity, with little or no use of the underpinning system on the part of the user. It also means that many teams can focus on their data tasks without worrying about performance hitches.
- Interoperability: Of particular great interest is the compatibility of the Databricks platform with leading cloud providers such as AWS, Microsoft Azure, and Google Cloud. This compatibility makes certain that an organization can easily adopt Databricks into the existing cloud solutions, and enjoy its powerful endowment without incurring the need to overhaul their systems. Additionally, Databricks excels at handling the orchestration of different systems and allowing the integration of the systems, so for enterprises that are utilizing multi-cloud or hybrid-cloud environments, this business option is perfect for the company.
- Lakehouse Architecture: Databricks introduces a revolutionary Lakehouse architecture that combines the best of both worlds: the weaknesses of data lakes and strong aspects of data warehouses, as well as the strong aspect of data lakes and the weaknesses of data warehouses. The traditional data lakes are ideal for housing a diverse set of big data but bring problems with data governance and retrieval. Data warehouses on the other hand are only capable of structured querying and are not able to house unstructured data. Databricks fills this gap by allowing users to handle structured, semi-structured, and unstructured data all through a single platform. This makes it easy to use, maintain data ownership, and get insights out of all types of data instead of having to move from one tool to another.
Incorporating all these features allows Databricks to present itself as a potent, productive, and easy-to-use tool for emerging and existing unprecedented data tasks hence making it deserving for an organization wishing to ease its data operations.
For a deeper understanding of the foundational principles, check out “What is Data Architecture? Types, Components, and Benefits.
Databricks vs. Other Data Warehouses
It is quite extraordinary when we compare it to other rivals such as Snowflake or Amazon Redshift, for instance, that the concept of the Lakehouse architecture stands out. Let’s break it down in a way that’s easy to digest:
| Feature | Databricks (Lakehouse) | Snowflake | Amazon Redshift |
| Data Support | Handles everything—structured, semi-structured, and unstructured data | Great for structured and semi-structured data | Also solid for structured and semi-structured data |
Architecture | Think of it as a data lake and data warehouse had a smart, flexible baby | A cloud data warehouse with separate computing and storage | Traditional warehouse with some cloud perks |
| Scalability | Scales automatically—no sweat required | Scales compute and store separately, so you’ve got options | Can scale too, but you might need to tinker a bit |
| Data Processing | Built for everything from ETL and ELT to hardcore ML/AI | Analytics and BI are its sweet spot | Primarily built for OLAP and querying |
| Machine Learning Integration | Comes with built-in ML/AI tools and plays nice with other frameworks | Basic ML support—bring your own tools | Pretty minimal ML support, external tools needed |
| Cloud Compatibility | Works with AWS, Azure, and Google Cloud—pick your favourite | Also plays across all major clouds | Mostly sticks to AWS |
| Concurrency | High concurrency and efficient resource use—it’s a multitasking pro | Handles high concurrency, but costs can add up | Concurrency is limited depending on the setup |
| Cost Model | Pay-as-you-go, and it adjusts resources automatically | Pay-as-you-go too, but storage and computing are separate | Pay-as-you-go, though compute-heavy tasks can get pricey |

Conclusion
Let me briefly explain Databricks architecture as it is as simple as it is powerful. It also saves time because it provides a single place to store all raw data, process it, and implement machine learning, helping teams speed up their decision-making process. Databricks is quite versatile due to the Lakehouse architecture, and most organisations can use it no matter their size. As such, if you are new to big data or a veteran this is a place that has information that can get you started or enhance what you already know.
To learn more about maximizing Databricks’ capabilities, explore how its overwrite feature can be fully leveraged.
So what to wait for, just explore it further and see how it can transform your data journey? Tools like Hevo can help you integrate your data into Databricks effortlessly, ensuring accuracy and efficiency. Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, check out our unbeatable pricing to choose the best plan for your organization.
FAQs
1. What application does Databricks architecture serve?
Databricks architecture serves as a starting point for big data, analytics, data processing and AI tasks in the cloud.
2. What is relative between Databricks and Snowflake?
Although both are cloud-based data platforms, Databricks mainly adopts the Lakehouse model, which mixes data lake and data warehouse, while Snowflake mainly provides data warehousing.
3. Are Databricks aws or azure?
Databricks utilizes many cloud providers, such as Amazon Web Services, Microsoft Azure, and Google Cloud.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





