




Companies are in need of a fast, reliable, scalable, and easy-to-use workspace for Data Engineers, Data Analysts, and Data Scientists. This is where you will need to understand what is Databricks.
Databricks is used to process and transform extensive amounts of data and explore it through Machine Learning models. It allows organizations to quickly achieve the full potential of combining their data, ETL processes, and Machine Learning. Since Databricks handles large-scale machine learning tasks, data security and privacy management are key concerns and you need to understand the concept of how DSPM and CSPM protect sensitive data in such large-scale operations
From this blog, you will get to know the Databricks Overview and What is Databricks. The key features and architecture of Databricks are discussed in detail.
Table of Contents
What is Databricks?

Databricks, an enterprise software company, revolutionizes data management and analytics through its advanced Data Engineering tools designed for processing and transforming large datasets to build machine learning models. Unlike traditional Big Data processes, Databricks, built on top of distributed Cloud computing environments (Azure, AWS, or Google Cloud), offers remarkable speed, being 100 times faster than Apache Spark. It fosters innovation and development, providing a unified platform for all data needs, including storage, analysis, and visualization.
Integrated with Microsoft Azure, Amazon Web Services, and Google Cloud Platform, Databricks simplifies data management and facilitates machine learning tasks. Notably, it utilizes a LakeHouse architecture to eliminate data silos and provide a collaborative approach to data warehousing in a data lake.
Databricks is a cloud-based platform which can be used for ETL workflows. The Databricks platform provides tools and features for ETL as follows:
- Databricks Delta Live Tables (DLT): It makes ETL development easier by codifying best practices and automating operational complexity.
- Databricks Workflows: It orchestrates tasks for ETL, analytics, and machine learning pipelines.
- Visual Flow: Integrates and operationalizes code and automatically runs Spark operations.
Hevo Data is a fully managed data pipeline solution that facilitates seamless data integration from various sources to Databricks or any data warehouse of your choice. It automates the data integration process in minutes, requiring no coding at all.
Check out why Hevo is the Best:
- Minimal Learning: Hevo’s simple and interactive UI makes it extremely simple for new customers to work on and perform operations.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Live Support: The Hevo team is available 24/7 to extend exceptional support to its customers through chat, E-Mail, and support calls.
- Transparent Pricing: Hevo offers transparent pricing with no hidden fees, allowing you to budget effectively while scaling your data integration needs.
Try Hevo today and experience seamless data migration!
Get Started with Hevo for FreeWho uses Databricks?
Databricks is used by many organizations, including some of the world’s largest companies, such as Shell, Microsoft, and HSBC. It is also used by a variety of startups and other organizations.
What are the Key Features of Databricks?
After getting to know What is Databricks, let us also get started with some of its key features. Below are a few features of Databricks:
- Data Source: It connects with many data sources to perform limitless Big Data Analytics. Databricks not only connects with Cloud storage services provided by AWS, Azure, or Google Cloud but also connects to on-premise SQL servers, CSV, and JSON. The platform also extends connectivity to MongoDB, Avro files, and many other files.
- Language: It provides a notebook interface that supports multiple coding languages in the same environment. Using magical commands (%python, %r, %scala, and %sql), a developer can build algorithms using Python, R, Scala, or SQL. For instance, data transformation tasks can be performed using Spark SQL, model predictions made by Scala, model performance can be evaluated using Python, and data visualized using R.
- Productivity: It increases productivity by allowing users to deploy notebooks into production instantly. Databricks provides a collaborative environment with a common workspace for data scientists, engineers, and business analysts. Collaboration not only brings innovative ideas but also allows others to introduce frequent changes while expediting development processes simultaneously. Databricks manages the recent changes with a built-in version control tool that reduces the effort of finding recent changes.
- Flexibility: It is built on top of Apache Spark that is specifically optimized for Cloud environments. Databricks provides scalable Spark jobs in the data science domain. It is flexible for small-scale jobs like development or testing as well as running large-scale jobs like Big Data processing. If a cluster is idle for a specified amount of time (not-in-use), it shuts down the cluster to remain highly available.
You can learn how to process and transform extensive amounts of data by configuring Databricks clusters effectively by checking out our blog on Databricks clusters.
Key Components of Databricks
1. Database Workspace
An Interactive Analytics platform that enables Data Engineers, Data Scientists, and Businesses to collaborate and work closely on notebooks, experiments, models, data, libraries, and jobs.
2. Databricks Machine Learning
An integrated end-to-end Machine Learning environment that incorporates managed services for experiment tracking, feature development and management, model training, and model serving. With Databricks ML, you can train Models manually or with AutoML, track training parameters and Models using experiments with MLflow tracking, and create feature tables and access them for Model training and inference.
You can now use Databricks Workspace to gain access to a variety of assets such as Models, Clusters, Jobs, Notebooks, and more.
3. Databricks SQL Analytics
A simple interface with which users can create a Multi-Cloud Lakehouse structure and perform SQL and BI workloads on a Data Lake. In terms of pricing and performance, this Lakehouse Architecture is 9x better compared to the traditional Cloud Data Warehouses. It provides a SQL-native workspace for users to run performance-optimized SQL queries. Databricks SQL Analytics also enables users to create Dashboards, Advanced Visualizations, and Alerts. Users can connect it to BI tools such as Tableau and Power BI to allow maximum performance and greater collaboration.
4. Databricks Integrations
As a part of the question What is Databricks, let us also understand the Databricks integration. Databricks integrates with a wide range of developer tools, data sources, and partner solutions.
- Data Sources: Databricks can read and write data from/to various data formats such as Delta Lake, CSV, JSON, XML, Parquet, and others, along with data storage providers such as Google BigQuery, Amazon S3, Snowflake, and others.
- Developer Tools: Databricks supports various tools such as IntelliJ, DataGrip, PyCharm, Visual Studio Code, and others.
- Partner Solutions: Databricks has validated integrations with third-party solutions such as Power BI, Tableau, and others to enable scenarios such as Data Preparation and Transformation, Data Ingestion, Business Intelligence (BI), and Machine Learning.
Understanding Databricks Architecture
Databricks is the application of the Data Lakehouse concept in a unified cloud-based platform. Databricks is positioned above the existing data lake and can be connected with cloud-based storage platforms like Google Cloud Storage and AWS S3. Understanding the architecture of databricks will provide a better picture of What is Databricks.

Layers of Databricks Architecture
- Delta Lake: Delta Lake is a Storage Layer that helps Data Lakes be more reliable. Delta Lake integrates streaming and batch data processing while providing ACID (Atomicity, Consistency, Isolation, and Durability) transactions and scalable metadata handling. Furthermore, it is fully compatible with Apache Spark APIs and runs on top of your existing data lake.
- Delta Engine: The Delta Engine is a query engine that is optimized for efficiently processing data stored in the Delta Lake.
- It also has other inbuilt tools that support Data Science, BI Reporting, and MLOps.
All these components are integrated as one and can be accessed from a single ‘Workspace’ user interface (UI). This UI can also be hosted on the cloud of your choice.
Why Databricks Platform is a Big Deal?
After getting to know What is Databricks, you must know why it is claimed to be something big. Databricks platform is basically a combination of four open-source tools that provides the necessary service on the cloud. All these are wrapped together for accessing via a single SaaS interface. This results in a wholesome platform with a wide range of data capabilities.
- Cloud-native: Works fine on any prominent cloud provider
- Data storage: Stores a broad range of data including structured, unstructured, and streaming
- Governance and management: In-built security controls and governance
- Data science tools: Production-ready data tooling from engineering to BI, AI, and ML

All these layers make a unified technology platform for a data scientist to work in his best environment. Databricks is a cloud-native service wrapper around all these core tools. It pacifies one of the biggest challenges called fragmentation. The enterprise-level data includes a lot of moving parts like environments, tools, pipelines, databases, APIs, lakes, warehouses. It is not enough to keep one part alone running smoothly but to create a coherent web of all integrated data capabilities. This makes the environment of data loading in one end and providing business insights in the other end successful.
Databricks provides a SaaS layer in the cloud which helps the data scientists to autonomously provision the tools and environments that they require to provide valuable insights. Using Databricks, a Data scientist can provision clusters as needed, launch compute on-demand, easily define environments, and integrate insights into product development.
What is Databricks Used For?
1. Data Engineering:
- Data Ingestion: Bringing data from various sources (databases, files, streams) into a central location.
- Data Transformation: Cleaning, transforming, and preparing data for analysis.
- Data Warehousing: Building and managing data warehouses for efficient data storage and retrieval.
2. Data Science:
- Data Exploration: Analyzing and visualizing data to gain insights.
- Machine Learning Model Development: Data science modeling involves building, training, and evaluating machine learning models.
3. Machine Learning & AI:
- Model Training: Training large-scale machine learning models on massive datasets.
- Model Deployment: Deploying and managing trained models for real-time predictions and inference.
4. Business Intelligence:
- Data Reporting: Generating reports and dashboards to track key metrics and business performance.
- Data Visualization: Creating interactive visualizations to explore and communicate data insights.
5. Stream Processing:
- Real-time Data Processing: Analyzing and reacting to data as it arrives in real-time.
- Stream Pipelines: Building and managing pipelines for continuous data processing.
6. Collaborative Analytics:
- Team Collaboration: Enabling teams to collaborate on data projects and share insights.
- Reproducibility: Ensuring that data analysis and model building can be reproduced reliably.
7. Data Lakehouse:
- Data Governance: Ensuring data quality, security, and compliance.
- Unified Data Management: Combining the best of data lakes and data warehouses into a single data lakehouse platform.
How to Get Started with Databricks 101
In this blog on What is Databricks, Get to know the steps to set up Databricks to start using it. Generally, Databricks offer a 14-day free trial that you can run on your preferable cloud platforms like Google Cloud, AWS, Azure. In this tutorial, you will learn the steps to set up Databricks in the Google Cloud Platform.
Step 1: Search for ‘Databricks’ in the Google Cloud Platform Marketplace and sign up for the free trial.
Step 2: After starting the trial subscription, you will receive a link from the Databricks menu item in Google Cloud Platform. This is to manage setup on the Databricks hosted account management page.
Step 3: After this step, you must create a Workspace which is the environment in Databricks to access your assets. For this, you need an external Databricks Web Application (Control plane).
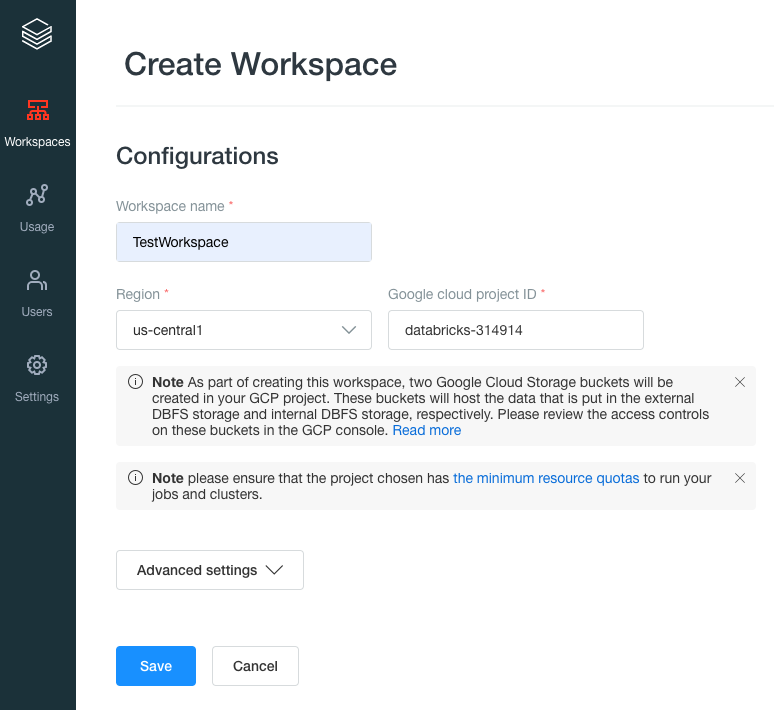
Step 4: To create a workspace, you need three nodes Kubernetes clusters in your Google Cloud Platform project using GKE to host the Databricks Runtime, which is your Data plane.
It is required to ensure this distinction as your data always resides in your cloud account in the data plane and in your own data sources, not the control plane — so you maintain control and ownership of your data.

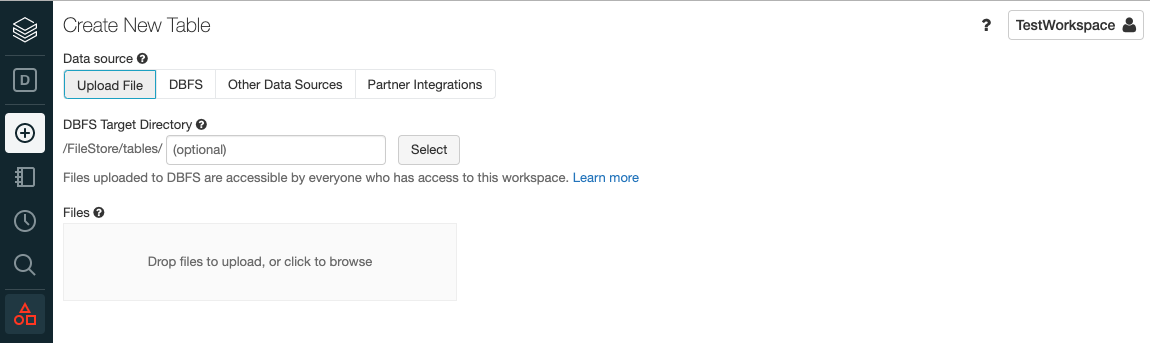
Step 5: Next to create a table in the Delta Lake, you can either upload a file, or connect to supported data sources, or use a partner integration.
Step 6: Then to analyze your data you must create a ‘Cluster‘. A Databricks Cluster is a combination of computation resources and configurations on which you can run jobs and notebooks. Some of the workloads that you can run on a Databricks Cluster include Streaming Analytics, ETL Pipelines, Machine Learning, and Ad-hoc analytics.
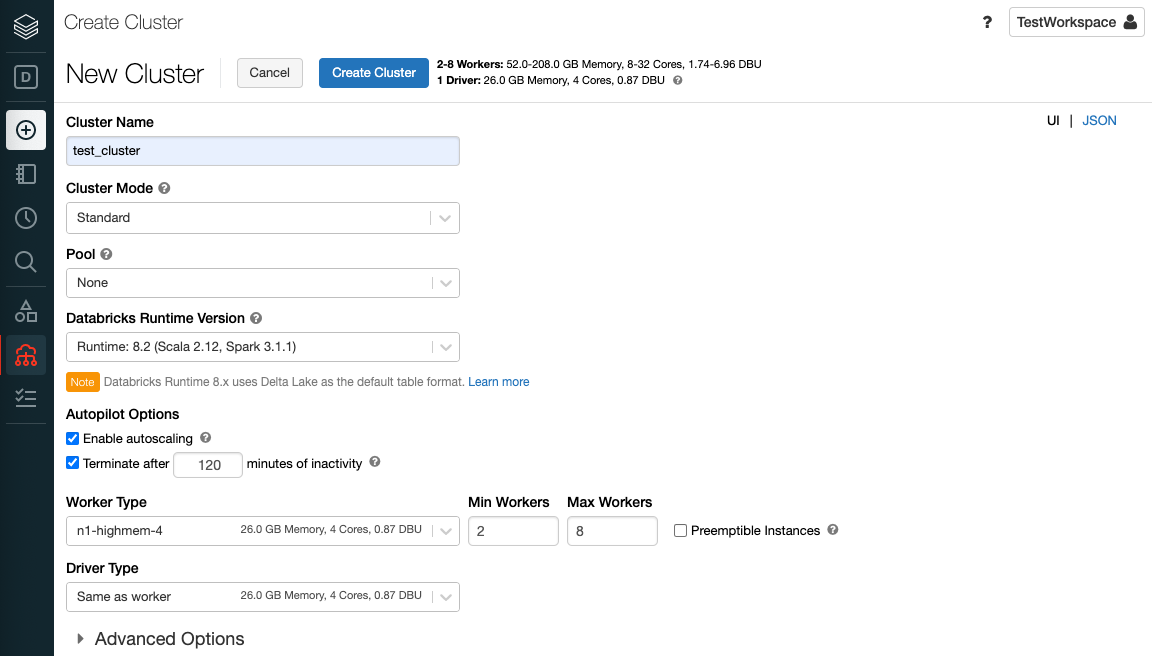
Step 7: In these Databricks, the runtime of the cluster is based on Apache Spark. Most of the tools in Databricks are based on open source technologies and libraries such as Delta Lake and MLflow.
Benefits of Databricks
After getting to know What is Databricks, let’s discuss more on its benefits.
- Databricks provides a Unified Data Analytics Platform for data engineers, data scientists, data analysts, business analysts.
- It has great flexibility across different ecosystems – AWS, GCP, Azure.
- Data reliability and scalability through delta lake are ensured in Databricks.
- Databricks supports frameworks (sci-kit-learn, TensorFlow, Keras), libraries (matplotlib, pandas, NumPy), scripting languages (e.g.R, Python, Scala, or SQL), tools, and IDEs (JupyterLab, RStudio).
- Using MLFLOW, you can use AutoML and model lifecycle management.
- It has got basic inbuilt visualizations.
- Hyperparameter tuning is possible with the support of HYPEROPT.
- It has got Github and bitbucket integration
- Finally, it is 10X Faster than other ETL’s.
You should discover the benefits of Databricks by implementing effective cost optimization strategies.

How is Databricks Different from other Databases and Data Warehouses?
Databricks, while similar to other databases and data warehouses, offers unique features and capabilities that set it apart. Here’s a tabular comparison:
| Feature | Databricks | Traditional Databases (e.g., MySQL, PostgreSQL) | Data Warehouses (e.g., Snowflake, Redshift) |
| Core Technology | Apache Spark | SQL | SQL |
| Data Types | Structured, semi-structured, unstructured | Primarily structured | Primarily structured |
| Scalability | Highly scalable, handles massive datasets | Can scale, but may have limitations | Highly scalable, optimized for large datasets |
| Use Cases | Data engineering, data science, machine learning, stream processing | Transactional processing, online analytical processing (OLAP) | OLAP, business intelligence |
| Programming Languages | Python, Scala, SQL, R | SQL | SQL |
| Deployment | Cloud-based (AWS, Azure, GCP) | On-premises or cloud-based | Cloud-based |
| Cost | Pay-per-use, based on compute resources | Varies depending on deployment and usage | Pay-per-use, based on data storage and compute resources |
What are some typical Databricks use cases?
1. Build an enterprise data lakehouse
To expedite, simplify, and integrate enterprise data solutions, the data lakehouse combines the advantages of enterprise data warehouses and data lakes. The data lakehouse can serve as the one source of truth for data scientists, data engineers, analysts, and production systems, facilitating quick access to consistent data and simplifying the creation, upkeep, and synchronization of numerous distributed data systems.
2. Data engineering and ETL
Data engineering serves as the foundation for organizations that are focused on data by ensuring that data is accessible, clean, and stored in data models that facilitate effective discovery and utilization, regardless of the purpose of the data—from creating dashboards to powering AI applications.
With the help of unique tools, Delta Lake, and the power of Apache Spark, Databricks offers an unparalleled extract, transform, and load (ETL) experience. ETL logic may be composed using SQL, Python, and Scala, and then scheduled job deployment can be orchestrated with a few clicks.
Hevo Data offers a user-friendly interface, automated replication, support for several data sources, data transformation tools, and efficient monitoring to simplify the process of moving data to Databricks.
3. Large language models and generative AI
Libraries like Hugging Face Transformers, which are part of the Databricks Runtime for Machine Learning, let you incorporate other open-source libraries or pre-trained models into your workflow. Using the MLflow tracking service with transformer pipelines, models, and processing components is made simple by the Databricks MLflow integration.
You can use Databricks to tailor an LLM for your particular task based on your data. You can quickly take a foundation LLM and begin training with your own data to have greater accuracy for your domain and workload with the use of open source technology like Hugging Face and DeepSpeed.
4. CI/CD, task orchestration, and DevOps
There are particular problems specific to the development lifecycles of analytics dashboards, ML models, and ETL pipelines. Using a single data source across all of your users using Databricks minimizes duplication of work and out-of-sync reporting.
You may reduce the overhead associated with monitoring, orchestration, and operations by also offering a set of standard tools for versioning, automating, scheduling, deploying code, and deploying production resources. Workflows are used to plan SQL searches, Databricks notebooks, and other random code. Repos enable syncing of Databricks projects with several well-known git providers. See Developer tools and guidance for a comprehensive list of available tools.
Learn More About:
- Databricks Clusters
- Azure Data Factory vs Databricks
- Databricks Snowflake Connector
- Power BI to Databricks
Conclusion
As we conclude, it is understood that Databricks is a robust platform designed to streamline data management and build ML models on large data sets. This blog gave you a deeper understanding of Databricks’ features, architecture, and benefits. Mastering Databricks basics helps you unlock the full potential of this platform.
Interested in mastering Databricks SQL? Read our comprehensive guide to get started and enhance your data operations with Databricks SQL.
Start your data journey with Databricks and streamline your data integration effortlessly with Hevo’s real-time, no-code ELT platform. Sign up for a 14-day free trial!
Frequently Asked Questions Related to Databricks
1. Do Databricks require coding?
The design data of Databricks is intended to be accessible to data engineers and scientists who are comfortable coding and to analysts who don’t have heavy-duty coding skills.
1. Data Engineer and Data Scientist: They can use Databricks to write code in languages like Python, SQL, Scala, and R.
2. Analysts and Business users: Databricks provides a graphical user interface, Databricks SQL, for creating dashboards and running SQL queries on data without writing any code for analysis.
2. Is Databricks AWS or Azure?
Databricks is available on multiple cloud platforms:
1. Databricks on AWS
2. Azure Databricks
3. Why use Databricks instead of Azure?
While Azure offers an end-to-end suite for services in data and analytics, here are some specific reasons someone may choose Databricks over native Azure services:
1. Unified Analytics Platform
2. Performance and Scalability
3. Collaboration and productivity

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



