



 KEY TAKEAWAY
KEY TAKEAWAYChoosing between Databricks and Redshift depends on whether your workloads lean toward data science and AI (Databricks) or BI and SQL analytics (Redshift).
- Deployment Model: Both follow SaaS-based cloud architectures, but Databricks supports multi-cloud flexibility (AWS, Azure, GCP), while Redshift is AWS-native.
- Data Ownership: Redshift stores and processes data fully within AWS, limiting external movement. Databricks offers flexible storage options, letting you manage data across clouds or within its Lakehouse.
- Data Structure: Redshift handles structured and semi-structured data formats like CSV, Parquet, and JSON. Databricks supports all data types and can even add schema to unstructured data for advanced analytics.
- Use Case Versatility: Redshift is ideal for SQL-based BI analytics, while Databricks shines in machine learning, big data processing, and AI-driven workloads.
- Scalability: Both are highly scalable, but Redshift’s scaling is cluster-based, whereas Databricks provides dynamic, auto-scaling clusters for elastic workloads.
Databricks is a leading Lakehouse and a hot selling product in the market. Databricks is known for combining the Data Lake and Data Warehouse in a single model known as Lakehouse. On the other hand, AWS Redshift is a popular Data warehouse tool from Amazon Web Service Stack. It has a petabyte scalable architecture and is most frequently used by Data Analysts to analyze the data.
This blog talks about Databricks vs Redshift in great detail. It also briefly introduces AWS Redshift and Databricks before diving into the differences between them.
Table of Contents
What is AWS Redshift Architecture?

The architecture of AWS Redshift contains a leader node and compute nodes. The compute node forms the cluster and performs analytics tasks assigned by the leader node. The below snap depicts the schematics of AWS Redshift architecture:
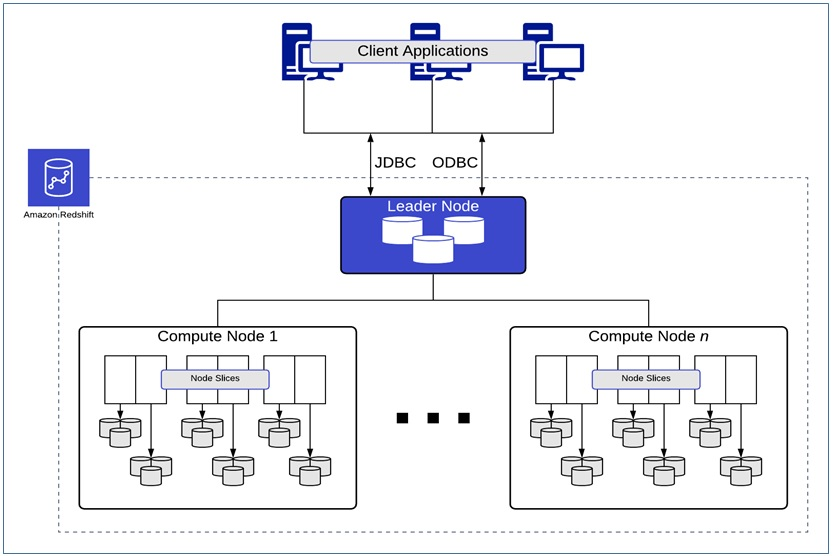
AWS Redshift offers JDBC connectors to interact with client applications using major programming languages like Python, Scala, Java, Ruby, etc. Read about the Redshift architecture and its components in detail.
Key Features of AWS Redshift
- AWS Redshift provides a complete data warehouse solution by maintaining Security, Scalability, Data Integrity, etc.
- AWS Redshift supports and works efficiently with different file formats, viz. CSV, Avro, Parquet, JSON, and ORC directly with the help of ANSI SQL.
- AWS Redshift has exceptional support for Machine Learning and Data Science projects. Users can deploy Amazon Sagemaker models using SQL.
- AWS Redshift uses the Advanced Query Accelerator (AQUA) concept, making the query execution 10x faster than other cloud data warehouses.
- AWS Redshift is a petabyte scalable architecture. Users can easily upscale or downscale the cluster as per the requirement.
- AWS Redshift enables secure sharing of the data across Redshift clusters.
- Amazon Redshift provides consistently fast performance, even with thousands of concurrent queries.
What is Databricks Lakehouse Architecture?

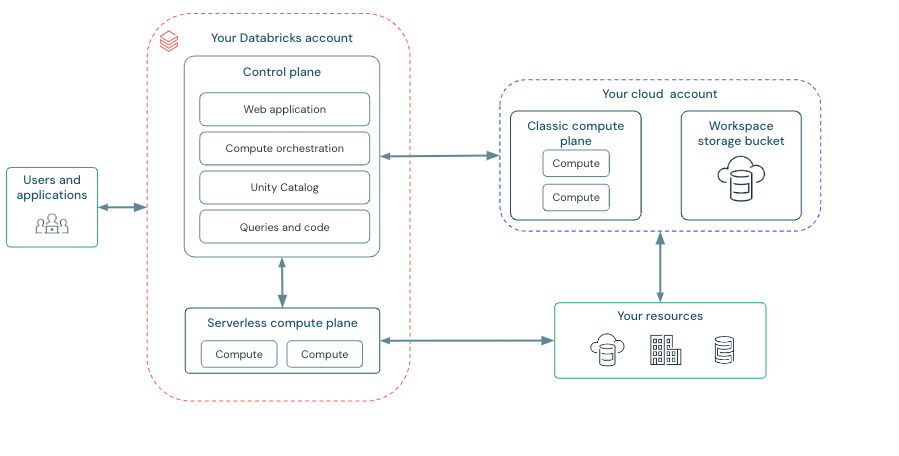
The architecture of Databricks is divided into a Control Plane and a Serverless Compute Plane. The Control Plane deals with the overall control of the environment, from access of users to their data up to orchestrating jobs and data governance. The Serverless Compute Plane automatically manages computations that scale resources aligned to needs of effective analytics workloads processing. Collectively, these components facilitate timely collaboration and data analysis under one unified cloud environment.
The data lakehouse is an open data architecture combining the best data warehouses and data lakes on one platform.
Suggested:
Key Features of Databricks
Databricks is a leading solution for Data Analysis and Data Scientists. The key features of Databricks are as follows –
- Notebooks: The main key feature or USP of the Databricks is their Notebooks. It is equipped with various languages (Python, Scala, SQL, and many more) that help users instantly analyze and access the data. The Databricks Notebook is also shareable across the workspace, enabling collaborative working in an organization.
- Delta Lake: Databricks has an open source Data Storage layer known as Delta lake, and the tables underneath are known as Delta Tables. Delta lake and Delta Tables allow users to perform ACID transactions on the data, which was quite a tedious task.
- Apache Spark: The backend of Databricks is supported by Apache Spark. With Apache Spark’s lightning-fast in-memory computations, you can effortlessly integrate various Open-source libraries with Databricks.
- Multi-Cloud Integration: Databricks supports the leading cloud and can easily be integrated. It supports AWS, Azure, and GCP as its leading cloud platform. With these cloud service providers, you can easily set up the clusters and execute BigData with the help of Apache Spark.
- Machine Learning: Databricks offers various machine learning libraries from Apache Spark, as well as native Python libraries like TensorFlow, PyTorch, Scikit-Learn, and many more. Users can quickly adapt these libraries and quickly build and train Machine Learning models.
Replicate Data in Databricks & Redshift in Minutes Using Hevo
With Hevo’s wide variety of connectors and blazing-fast Data Pipelines, you can extract & load data from 150+ Data Sources straight into your Data Warehouse like Redshift, Databricks, Snowflake and many more. Know why Hevo is the Best:
- Cost-Effective Pricing: Transparent pricing with no hidden fees, helping you budget effectively while scaling your data integration needs.
- Minimal Learning Curve: Hevo’s simple, interactive UI makes it easy for new users to get started and perform operations.
- Schema Management: Hevo eliminates the tedious task of schema management by automatically detecting and mapping incoming data to the destination schema.
What are the Key Differences of Databricks vs Redshift?
Now that you have discussed AWS Redshift and Databricks Lakehouse in detail in the above section. Let us compare them based on different aspects:
1) Databricks vs Redshift: Deployment Model
- Generally, AWS Redshift has a SaaS(Software as a Service) Deployment model. AWS Redshift is a Cloud-based service from Amazon Web Services and hence follows the same Deployment model as other AWS services. Users can create Redshift clusters and attach them to the ready-to-use AWS Redshift.
- In the same way, Databricks also follows the Saas(Software-as-a-Service) Deployment Model. It has a cluster, storage system, file system, etc. Users who want to use Databricks can subscribe to their available plans and use the ready-to-go Databricks solutions.
2) Databricks vs Redshift: Data Ownership
- AWS retains the ownership of both Data Storage and Data Processing layers. In AWS Redshift, data ownership is maintained entirely by AWS services. Be it its storage layer or S3, you cannot store or move the data to any Third-Party application if you have to use AWS Redshift.
- On the other hand, with Databricks, the Data Storage and Data Processing layers are separated. It allows you to store the data in any cloud storage (i.e., AWS, Azure, GCP) or within Databricks.

3) Databricks vs Redshift: Data Structure
- AWS Redshift supports semi-structured and structured data. AWS redshift uses the COPY command to copy the data from S3 to its warehouse, thereby maintaining data integrity and ownership. Once the data is loaded into its warehouse, it can then be used to perform analytics and generate insights. AWS redshift can work with data types such as CSV, Parquet, JSON, Avro, etc.
- Like AWS Redshift, Databricks also works with all the data types, such as CSV, Parquet, JSON, and many more, in their original format. Can work with all the data types in their original format. You can even use Databricks as an ETL tool to add structure to your Unstructured data so that other tools like Snowflake can work with it.
4) Databricks vs Redshift: Use Case Versatility
- AWS Redshift provides an SQL interface to write and execute queries on the data residing in its warehouse. AWS Redshift is best suited for SQL-based Business Intelligence use cases. They perform Machine Learning and Data Science use cases; users must rely on the different tools from the AWS stack.
- On the other hand, Databricks allows users to perform Big Data analytics, build and execute Machine Learning Algorithms, and develop Data Science capabilities. It also allows the execution of high-performance SQL queries for Business Intelligence use cases.
5) Databricks vs Redshift: Scalability
- AWS Redshift uses its Cluster, which is highly scalable. It allows users to create clusters with different configurations and upscale and downscale at any given time without fear of losing any data.
- On the other hand, Databricks also offers scalable clusters which can be scaled up and down based on the requirements.
6) Databricks vs Redshift: Pricing
- AWS Redshift, allows you to create a small cluster as small at $0.25 per hour and scale up to petabytes of data and thousands of concurrent users. However, AWS Redshift has a pay-as-you-go pricing model that allows users to save money when the cluster is idle.
- Databricks offers you a pay-as-you-go approach with no up-front costs. However, Databricks pricing is also dependent upon the cloud services chosen. You can find more about pricing here.
Learn More
Conclusion
In this blog post, you have discussed AWS Redshift and Databricks Lakehouse. This blog also highlights their key features and compares them against different parameters.
However, getting data into Databricks or Redshift can be a time-consuming and resource-intensive task, especially if you have multiple data sources. To manage & manage the ever-changing data connectors, you need to assign a portion of your engineering bandwidth to integrate data from all sources, clean & transform it, and finally, load it to a Cloud Data Warehouse like Databricks, Redshift, or a destination of your choice for further Business Analytics. All of these challenges can be comfortably solved by a Cloud-based ETL tool such as Hevo Data.
Hevo Data, a No-code Data Pipeline, can replicate data in real time from a vast sea of 150+ sources to a Data Warehouse like Databricks, Redshift, or a Destination of your choice. It is a reliable, completely automated, and secure service that doesn’t require you to write any code!
Want to take Hevo for a ride? Sign up for a 14-day free trial and simplify your Data Integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Share your experience of learning the differences between Databricks vs Redshift! Let us know in the comments section below!
FAQs
1. What’s the main difference between Databricks and Redshift?
Databricks is a Lakehouse platform that merges data lakes and warehouses to support AI, ML, and advanced analytics. Redshift is a cloud data warehouse optimized for structured SQL-based analytics. In short, Databricks suits data engineering and science workflows, while Redshift caters to business intelligence and reporting.
2. Which platform is better for large-scale data science projects?
Databricks is better suited for large-scale data science, ML, and real-time processing due to its integration with Apache Spark and Delta Lake. It provides notebooks for collaborative work and supports popular frameworks like TensorFlow and PyTorch. Redshift, while powerful, focuses more on SQL analytics and lacks the native ML depth Databricks offers.
3. Is Redshift easier to manage than Databricks?
Yes. Redshift offers a more turnkey experience, ideal for teams focused on analytics without heavy infrastructure management. It automatically handles scaling, backups, and encryption. Databricks, though slightly steeper to learn, gives greater flexibility and control for custom data pipelines and machine learning workloads.
4. Can Databricks integrate with Redshift?
Absolutely. Many organizations use both platforms together—Databricks for ETL and ML workloads, and Redshift for fast SQL-based analytics. You can seamlessly move processed data between them using ETL tools like Hevo Data, ensuring unified, real-time data availability across both systems.
5. Which one is more cost-effective for analytics teams?
Redshift is often more cost-effective for pure analytics workloads, especially with its pay-per-hour clusters and pause/resume options. Databricks becomes cost-efficient for multi-use workloads involving ETL, ML, and streaming, thanks to its scalable compute pricing and unified platform. The right choice depends on your data volume, use case, and team expertise.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link











