

Easily move your data from Elasticsearch to Databricks to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time. Check out our 1-minute demo below to see the seamless integration in action!
Elasticsearch is one of the top players when it comes to logging or log-based analytics use cases. Although Elasticsearch is known for its efficiency, knowledge of Elasticsearch Domain Specific Language (DSL) is a must. And, if you are struggling with DSL, you might want to replicate your data to Databricks instead.
Databricks supports standard SQL, and its functionalities are on par with Elasticsearch. Databricks can easily handle complex queries.
You can replicate data with the help of CSV files using Python to replicate your data from Elasticsearch to Databricks, or use an automated data pipeline like Hevo to ease the replication process.
Table of Contents
Why You Should Integrate Elasticsearch with Databricks?
Elasticsearch to Databricks integration has the following benefits:
- Streamline Data Processing & Reporting: Leverage Elasticsearch for fast search and Databricks for scalable transformations and reporting.
- Combine Search with ML Workflows: Use Elasticsearch for querying and Databricks for building machine learning models on the retrieved data.
- Advanced Analytics on Indexed Data: Analyze Elasticsearch data in Databricks using Spark SQL, visualizations, and complex aggregations.
- Unify Real-Time & Historical Data: Use Elasticsearch for live data access and Databricks for storing and analyzing historical trends.
Hevo enables seamless integration between Elasticsearch and Databricks, allowing users to transfer and analyze large volumes of search data effortlessly. With Hevo’s no-code platform, you can connect Elasticsearch to Databricks in minutes, unlocking powerful analytics and real-time insights from your data.
How Hevo Simplifies Elasticsearch to Databricks Integration:
- Scalable Data Management: Hevo handles schema changes and large datasets automatically, ensuring smooth data ingestion and transformation.
- No-Code Integration: Easily configure the pipeline between Elasticsearch and Databricks without any coding knowledge.
- Real-Time Data Flow: Sync data from Elasticsearch to Databricks in real time, ensuring timely and accurate analytics.
Methods to Replicate Data from ElasticSearch to Databricks
You can replicate data from Elasticsearch to Databricks using either of the two methods:
Method 1: Replicating Data from ElasticSearch to Databricks using CSV Files
Export Data from Elasticsearch to CSV: Use Python and Pandas to query Elasticsearch and export the data to a CSV file.
from elasticsearch import Elasticsearch
import pandas as pd
es = Elasticsearch()
response = es.search(index='your_index', body={}, size=100)
docs = pd.json_normalize([hit['_source'] for hit in response['hits']['hits']])
docs.to_csv('output.csv', index=False)Upload CSV to Databricks: In Databricks, go to the “Data” tab, drag and drop the CSV file, or browse your file system to upload it. Once uploaded, create a table from the CSV.
Modify and Query Data in Databricks: After uploading, modify data types as needed and preview the table by selecting the appropriate cluster.


Challenges Faced While Replicating Data
In the following scenario, using CSV files might not be a wise choice:
- You will need to perform the entire process frequently to access updated data at your destination to achieve two-way sync.
- The CSV method might not be a good fit for you if you need to replicate data regularly, since it’s time-consuming to replicate data using CSV files.
Companies can use automated pipelines such as Hevo to avoid such challenges. Hevo helps you replicate data from databases such as PostgreSQL, MongoDB, MariaDB, SQL Server, etc.
Using an automated data pipeline tool, you can transfer data from Elasticsearch to Databricks.
Method 2: Replicating Data from ElasticSearch to Databricks using Hevo
Hevo is an automated data pipeline tool that replicates data from Elasticsearch to Databricks and 150+ sources to your preferred destination. It simplifies real-time data management and ensures you always have analysis-ready, reliable data for deeper insights.
Steps to Connect Elasticsearch to Databricks
The simple steps to carry out Elasticsearch to Databricks using Hevo:
Step 1: Configure Elasticsearch as a Source
Authenticate and Configure your Elasticsearch Source.

Step 2: Configure Databricks as a Destination
In the next step, we will configure Databricks as the destination.
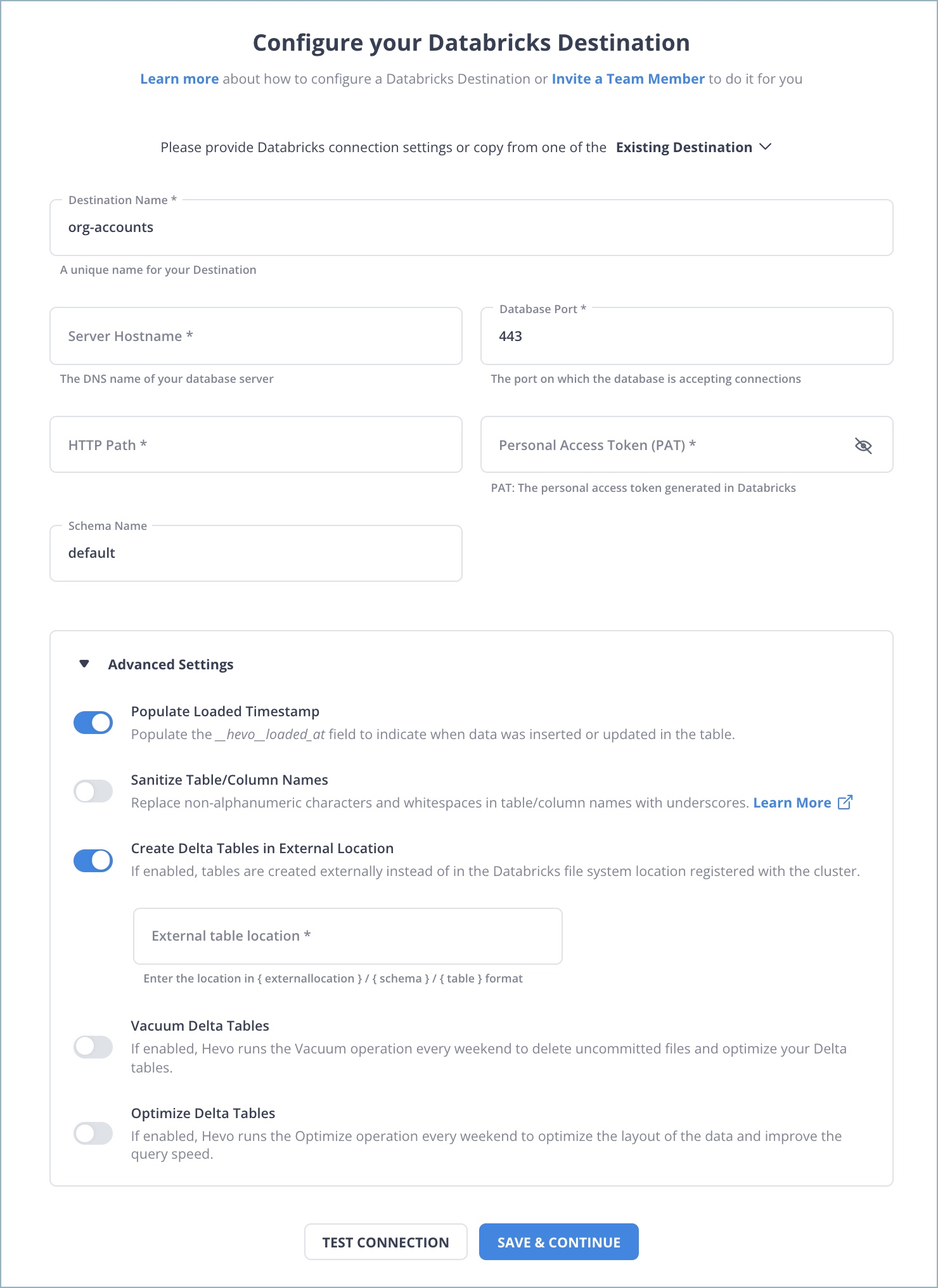
Step 3: All Done to Set Up Your ETL Pipeline
Once your Elasticsearch to Databricks ETL Pipeline is configured, Hevo will collect new and updated data from Elasticsearch every five minutes (the default pipeline frequency) and duplicate it into Databricks. Depending on your needs, you can adjust the pipeline frequency from 5 minutes to an hour.
Data Replication Frequency
| Default Pipeline Frequency | Minimum Pipeline Frequency | Maximum Pipeline Frequency | Custom Frequency Range (Hrs) |
| 1 Hr | 15 Mins | 24 Hrs | 1-24 |
You can set up Data Pipeline and start replicating the data within a few minutes!

You can also read more about:
- Google Analytics 4 to Databricks
- MongoDB to Databricks
- Databricks S3
- Kafka to Databricks
- Power BI to Databricks
Let’s Put It All Together
In this blog, you will learn about the key factors that could be considered for replicating data from Elasticsearch to Databricks. You learned how data could be replicated using Python Pandas. You also learned about an automated data pipeline solution known as Hevo.
You can use Hevo today to enjoy fully automated, hassle-free data replication for 150+ sources. You can sign up for a 14-day free trial, which gives you access to many free sources. Hevo’s free trial supports 50+ connectors and up to 1 million events per month, and spectacular 24/7 email support to help you get started.
FAQ
How do I transfer data to Databricks?
You can transfer data to Databricks using various methods such as:
1. Uploading files directly through the Databricks UI.
2. Using APIs like REST API or Databricks CLI.
3. Connecting to external data sources like AWS S3, Azure Blob Storage, or ADLS Gen2.
How do I connect to Elasticsearch using PySpark?
You can connect to Elasticsearch using PySpark by configuring the Elasticsearch Hadoop connector (elasticsearch-hadoop). Set the Spark configuration with the es.nodes and es.port parameters to specify the Elasticsearch host and port.
How to connect R to Azure Databricks?
To connect R to Azure Databricks, you can use RStudio on Databricks, or connect via JDBC or ODBC drivers using sparklyr, a package for Spark integration with R. This allows you to run R code directly on Databricks clusters.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link










