




Easily move your data from Google Drive to Redshift to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time—check out our 1-minute demo below to see the seamless integration in action!
With the explosion of data, 2.5 quintillion bytes of data are generated every day. This massive volume of data is dispersed across several systems and applications. Companies desire to consolidate this information into a single place or warehouse for quick access and analysis. This data must be compiled in a robust and scalable Data Warehouse like Redshift to understand the business operations comprehensively.
By replicating your data from Google Drive to Redshift, you can ensure that all of your vital data is in one location. Bringing your critical sales, marketing, and customer data from Google Drive to Redshift is essential to establishing a solid analytical infrastructure. Redshift can handle large data volumes with ease for businesses that are used to accessing transactional databases. Queries with millions (or billions) of entries deliver results in milliseconds rather than minutes or hours.
Continue reading to learn how to link data from Google Drive to Redshift in minutes.
Table of Contents
What is Google Drive?

Google Drive is a Cloud Storage Service that allows you to store files online and access them from any smartphone, tablet, or computer connected to the Internet. Compared to competitors such as DropBox and Apple’s iCloud service, Google Drive’s success has been founded on functional collaboration capabilities and built-in synergies with Google’s product – and service suite.
Google Drive is a free service that allows users to manage and share information personally and professionally. Google Drive is popular among businesses because of its easy interface, reliability, and security, all of which come at a reasonable cost. By combining Google Drive with other Google products, you can also utilize free Web-Based tools to create Documents, Spreadsheets, Presentations, and more.
Key Features of Google Drive
- Work Offline: You can operate offline after activating Offline mode, even if you don’t have an internet connection.
- Easy to Use Interface: When you sign in to your Google Drive account, you’ll find your most recent papers at the top of the screen, as well as a list of all your folders and simple navigation on the left that allows you to access all documents shared outside of your drive.
- Personalization and Sharing: Each file or folder in Google Drive has its Share Link, and you may offer other users access to personalize the content.
- Security: According to Google, Google Drive is also protected by the same SSL encryption used in Gmail and other Google Services.
- Gmail Attachments Should Be Saved: Saving attachments from emails is one of Google Drive’s most popular services. It’s simple to save photos or attachments to Drive when you get an email containing them. After you save it, click the Attachment symbol in Gmail to transfer it to any folder on the drive.
Say goodbye to the hassle of manually connecting Redshift. Embrace Hevo’s user-friendly, no-code platform to streamline your data migration effortlessly.
Choose Hevo to:
- Access 150+(60 free sources) connectors, including Google Drive and Redshift.
- Ensure data accuracy with built-in data validation and error handling.
- Eliminate the need for manual schema mapping with the auto-mapping feature.
Don’t just take our word for it—try Hevo and discover how Hevo has helped industry leaders like Whatfix connect Redshift seamlessly and why they say,” We’re extremely happy to have Hevo on our side.”
Move PostgreSQL Data for FreeWhat is Amazon Redshift?
AWS Redshift is a cloud-based Data Warehousing and Analytics service provided by AWS, Amazon Web Services, the tech giant’s cloud-computing division. Users of AWS Redshift may upload and handle massive volumes of data.
Amazon Redshift provides consumers and businesses with a platform for analyzing data to obtain new insights into their operations by offering a nearly endless data storage option. The cost of AWS Redshift increases in proportion to the amount of space requested. This implies that if users need additional space as they expand, they may get it right now because AWS Redshift is cloud-based, so we can quickly scale it up.
Redshift’s architecture implies that it is designed to examine your data quickly. This is accomplished by employing Massively Parallel Processing (MPP). It also utilizes Machine Learning and results caching to ensure less than a second query response speeds.
Key Features of Amazon Redshift
- Faster Performance: Amazon Redshift provides rapid query speed on datasets ranging from gigabytes to exabytes in size. To decrease the amount of I/O required to conduct queries, Redshift employs columnar storage, data compression, and zone maps. It uses Massively Parallel Processing (MPP) Data Warehouse architecture to parallelize and distribute SQL operations to utilize all available resources. The underlying technology is optimized for high-performance data processing, with locally connected storage maximizing throughput between CPUs and drives and a high-bandwidth mesh network maximizing throughput between nodes.
- Easy to Set Up: Amazon Redshift is easy to set up and use. With a few clicks on the Amazon Web Services Management cConsole, you can install a new Data Warehouse, and Redshift will supply the infrastructure for you. Most administrative tasks, such as backups and replication, are automated, allowing you to concentrate on your data rather than the administration. When it comes to controlling, Redshift offers solutions to assist you in making modifications according to your workloads. New capabilities are openly delivered, reducing the need to plan and perform updates and fixes.
- Flexible Querying: Amazon Redshift allows users to run queries directly from the console or connect their favorite SQL client tools, libraries, or business intelligence tools. The Amazon Web Services console’s Query Editor provides a robust interface for running SQL queries on Redshift clusters and displaying the query results and query execution plan (for queries run on compute nodes) adjacent to your queries.
- Fault-Tolerant: Amazon Redshift has several capabilities that improve the dependability of your Data Warehouse cluster. Redshift continually monitors the cluster’s health, automatically replicating data from failing disks and replacing nodes as needed for fault tolerance.
- Scalability: Amazon Redshift is easy to use and grows fast as your needs evolve. You may quickly modify the number or type of nodes in your Data Warehouse with a few clicks in the console or a simple API call and scale up or down as your needs change.
Why Does Data Need to be Replicated From Google Drive to Redshift?
Replicating data from Google Drive to Amazon Redshift is essential for several reasons, particularly for organizations that want to leverage their data for advanced analytics and decision-making:
- Centralized Data: Enables advanced analytics by centralizing data in a structured format.
- Improved Query Performance: Redshift is optimized for fast queries on large datasets.
- BI Tool Integration: Seamless integration with tools like Tableau and Looker for reporting.
- Scalability: Easily handles growing data volumes for large-scale analytics.
- Real-time Analytics: Ensures up-to-date data for continuous reporting and dashboards.
Methods to Set Up Google Drive to Redshift Integration
Method 1: Using Hevo Data to Set Up Google Drive to Redshift Integration
The steps to import data from Google Drive to Redshift using Hevo Data are as follows:
Step 1: Connect your Google Drive account as a source.
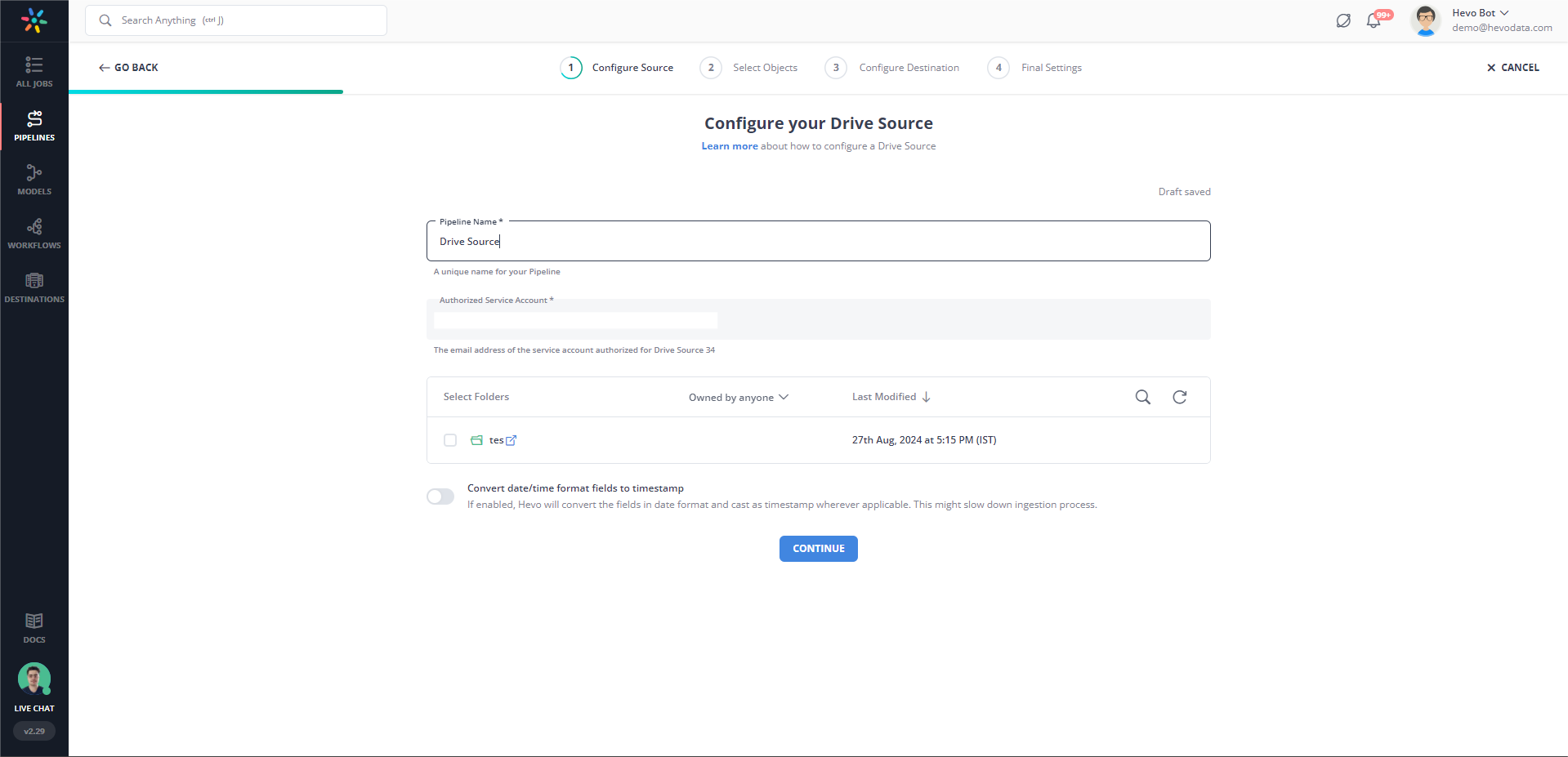
Step 2: Select Amazon Redshift as your destination and begin data transfer.
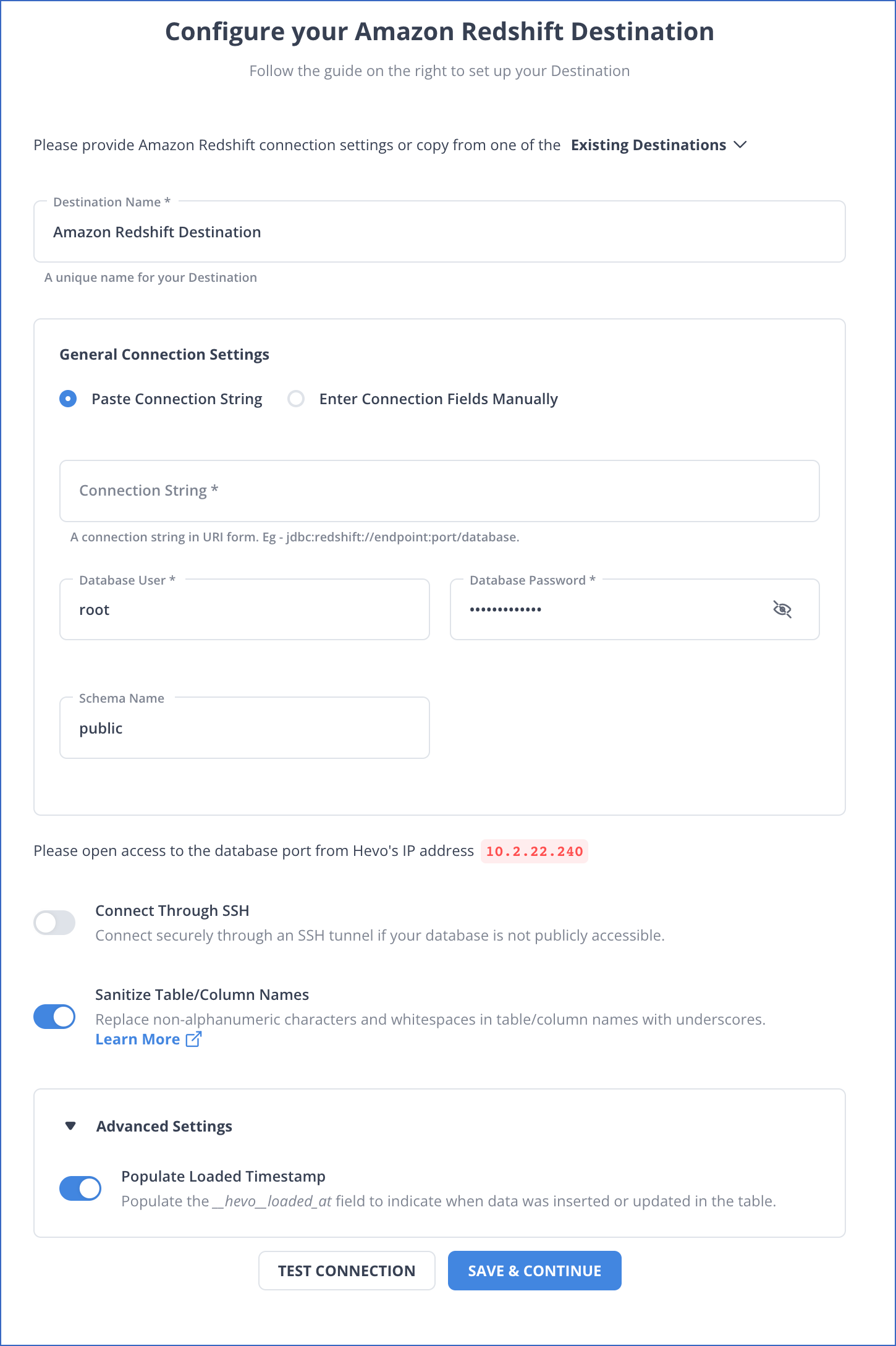
Redshift provides excellent data warehousing capabilities along with various UDF like Scalar Python , FIRST_VALUE Function etc. for you to transform your data for better reporting and analysis.
Method 2: Building an ETL Pipeline to Set Up Google Drive to Redshift Integration
Step 1: Extracting Google Drive Data as CSV
- Open the Google Drive file that you want to load to Amazon Redshift.
- In the top left corner, select File.
- Select Comma-Separated Values (.csv) from the ‘Download As’ menu.
- After that, the data will be exported to CSV and downloaded to your local machine. The same procedure may be used to import data from several Google Drives to Redshift.
Step 2: Loading Data to Amazon RedshiftFollow the below steps to load their data from Google Drive to Redshift:
- Enter the Amazon Web Services Management Console.
- Launch the Amazon S3 Console and select Create Bucket.

- Choose an excellent unique name for your AWS S3 Bucket, choose a region, and click Create.
- Open the AWS S3 Bucket you just established, click on Create Folder, give it a suitably unique name, and save it.
- Upload the previously exported Google Drive CSV data to the newly formed folder by clicking Upload and choosing the relevant files in the Upload Wizard.
- Using the COPY Command, data from Amazon S3 may be imported into Amazon Redshift Cluster.
- Connect to the Cluster with your preferred SQL Workbench tool and perform the following query:
COPY table_name
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>'
CSV;- You may additionally request that the file header rows in the CSV files be ignored by performing the following query:
COPY table_name
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>'
CSV
IGNOREHEADER 1;- In your Amazon Redshift database, your data should now be available and queryable.

Conclusion
This article provides an overview of Google Drive and Amazon Redshift and a description of their most essential features. It also detailed the two methods for moving data from Google Drive to Redshift. The manual data replication method from Google Drive to Redshift would take a lot of time and resources, making it a time-consuming and tiresome process. But, with the help of a data integration solution like Hevo, it can be done quickly and with little effort.
Hevo Data is a No-code Data Pipeline that can transport data in real-time from 150+ data sources (including 60+ free sources) to a Data Warehouse, BI Tool, or any other destination of your choosing. It is a strong, fully automated, and safe solution that requires no coding!
Sign up for Hevo’s 14-day free trial and check out the price information to determine which plan meets your business’s requirements.
You may share your learning experience about Integrating Google Drive to Redshift in the comments section below.
FAQ on Google Drive to Redshift
How do I transfer data to Redshift?
To transfer data to Amazon Redshift, you typically follow these steps:
– Prepare your Data
– Upload Data to S3
– Create a Redshift Cluster
– Use the COPY Command
– Monitor Load Status
Can Google Sheets connect to Redshift?
Google Sheets does not have a native connector for Amazon Redshift. However, you can use third-party tools or methods to connect Google Sheets indirectly to Redshift:
– Use Google Sheets Add-ons
– Data Export and Import
– Data Integration Platforms
How do I push data to AWS redshift?
To push data to AWS Redshift, follow the steps outlined in transferring data to Redshift above. Here’s a summarized approach:
– Prepare your Data
– Upload to S3
– Use Copy Command
– Run the Loading

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



