




Unlock the full potential of your Google Sheets data by integrating it seamlessly with Redshift. With Hevo’s automated pipeline, get data flowing effortlessly. Watch our 1-minute demo below to see it in action!
A large number of businesses use platforms like Google Sheets as a database. Although it is easy to perform simple analysis on Google Sheets, it is not possible to perform complex analysis on the platform. Businesses might also be looking to create a Single Source of Truth for all their data, which might not be easy to do on Google Sheets. Hence, businesses feel the need to set up Google Sheets for Redshift Migration, and this article will provide you with two easy methods that can help you do that.
Table of Contents
What are the advantages of replicating data from Google Sheets to Redshift?
By migrating your data from Google Sheets to Redshift, you will be able to help your business stakeholders with the following:
- Aggregate the data of individual interactions with the product for any event.
- Finding the customer journey within the product (website/application).
- Integrating transactional data from different functional groups (Sales, Marketing, Product, Human Resources) and finding answers. For example:
- Which Development features were responsible for an App Outage in a given duration?
- Which product categories on your website were most profitable?
- How does the Failure Rate in individual assembly units affect Inventory Turnover?
Also, learn how to move data from Google Sheets to Amazon Aurora to make it easier to directly load your data from Amazon Aurora.
Using Hevo, you can directly extract and load data from various sources like Google Sheets into your Data Warehouse, such as Redshift or any Database.
Why Hevo is the Best:
- Integrate data from 150+ sources (60+ free sources).
- Get round-the-clock support, live monitoring, and instant notifications about your data transfers.
- Use a drag-and-drop transformation feature, a user-friendly way to perform simple data transformations.
Choose Hevo and see what Whatfix says, with secure integration from 5 sources and 2 months saved in engineering time, Hevo helped boost their data accuracy by 1.2x.
Get Started with Hevo for FreeMethod 1: Google Sheets to Redshift Migration Using Hevo Data
Step 1: Configure Google Sheets as Your Data Source
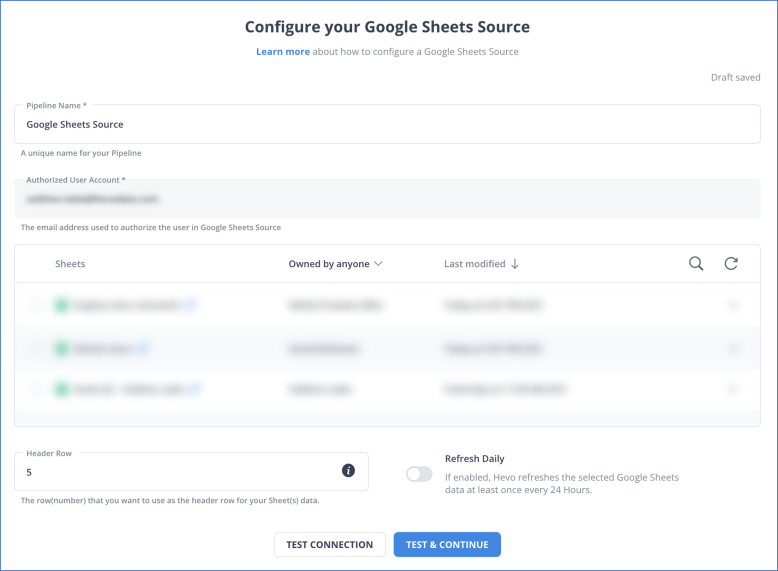
To quickly connect Google Sheets as a data source, check the prerequisites and detailed instructions.
Step 2: Configure Redshift as Your Data Destination
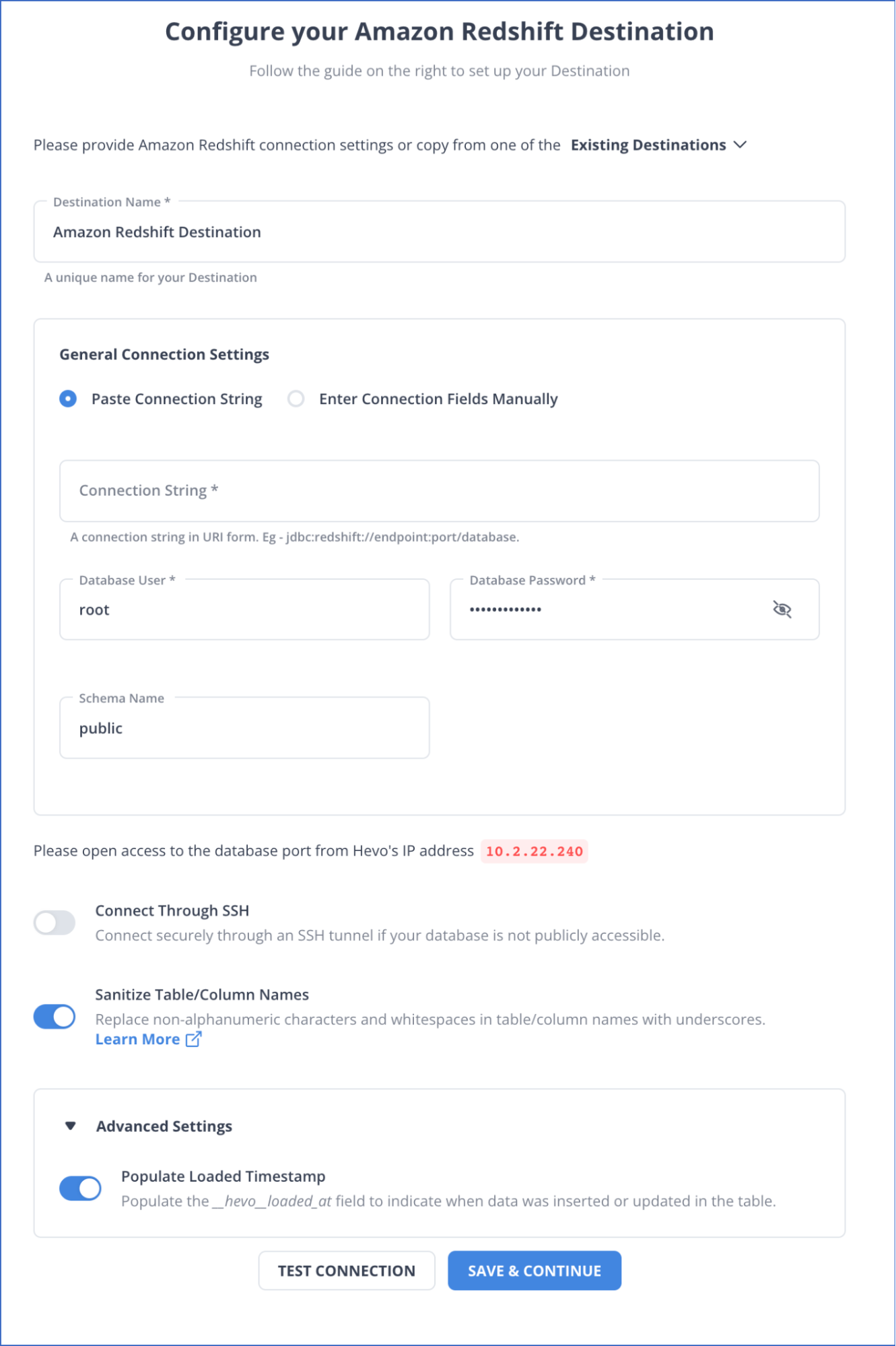
To know more details about configuring Redshift as a destination, refer to the documentation for a detailed understanding.

Method 2: Manual Method: Google Sheets to Redshift Migration
Users can set up a manual Google Sheets to Redshift Migration by implementing the following steps:
Step 1: Extracting Google Sheets Data as CSV
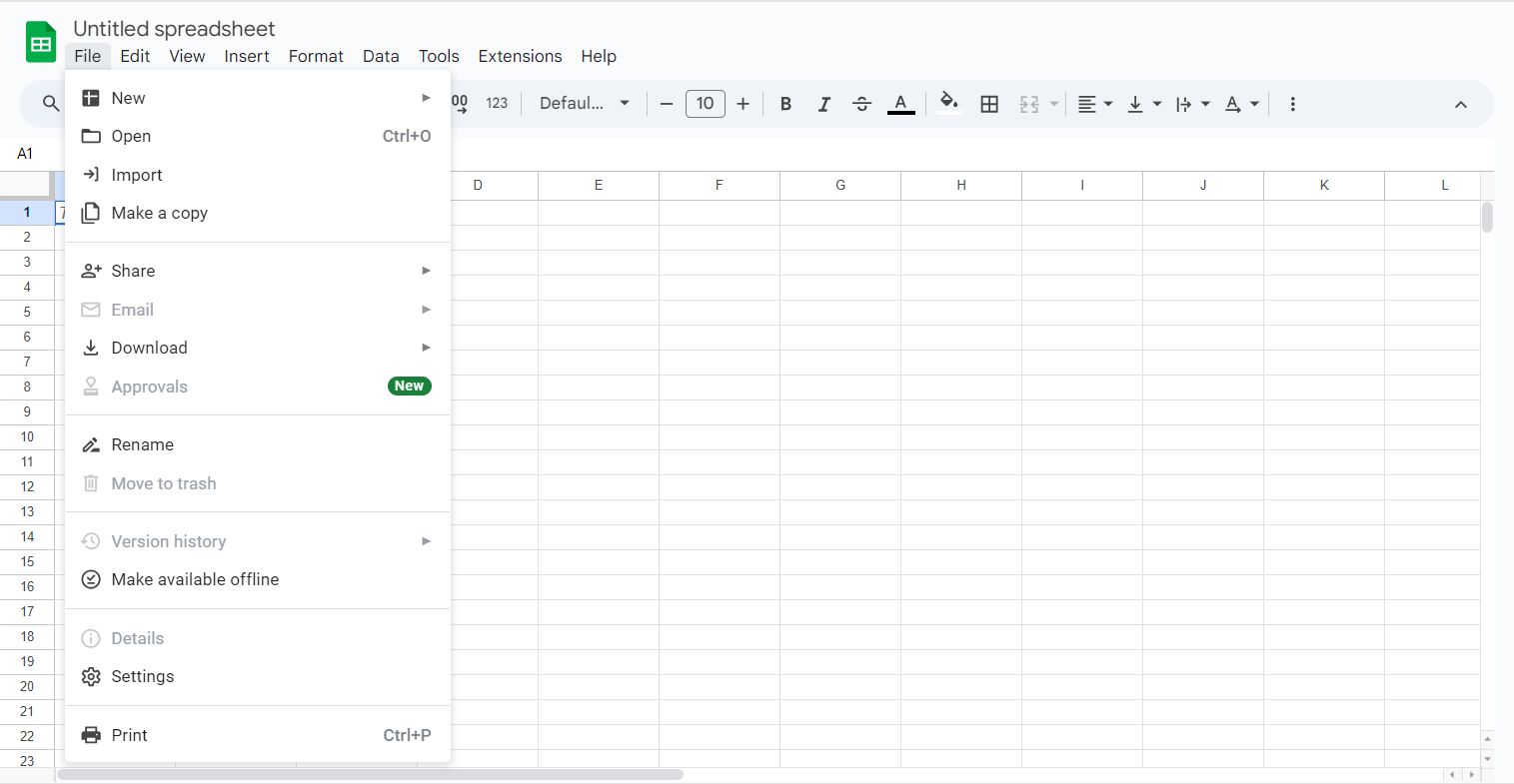
- Open the Google Sheets file you wish to load into Amazon Redshift.
- Click on File in the upper left corner.
- Click on Download As and select Comma-Separated Values (.csv).
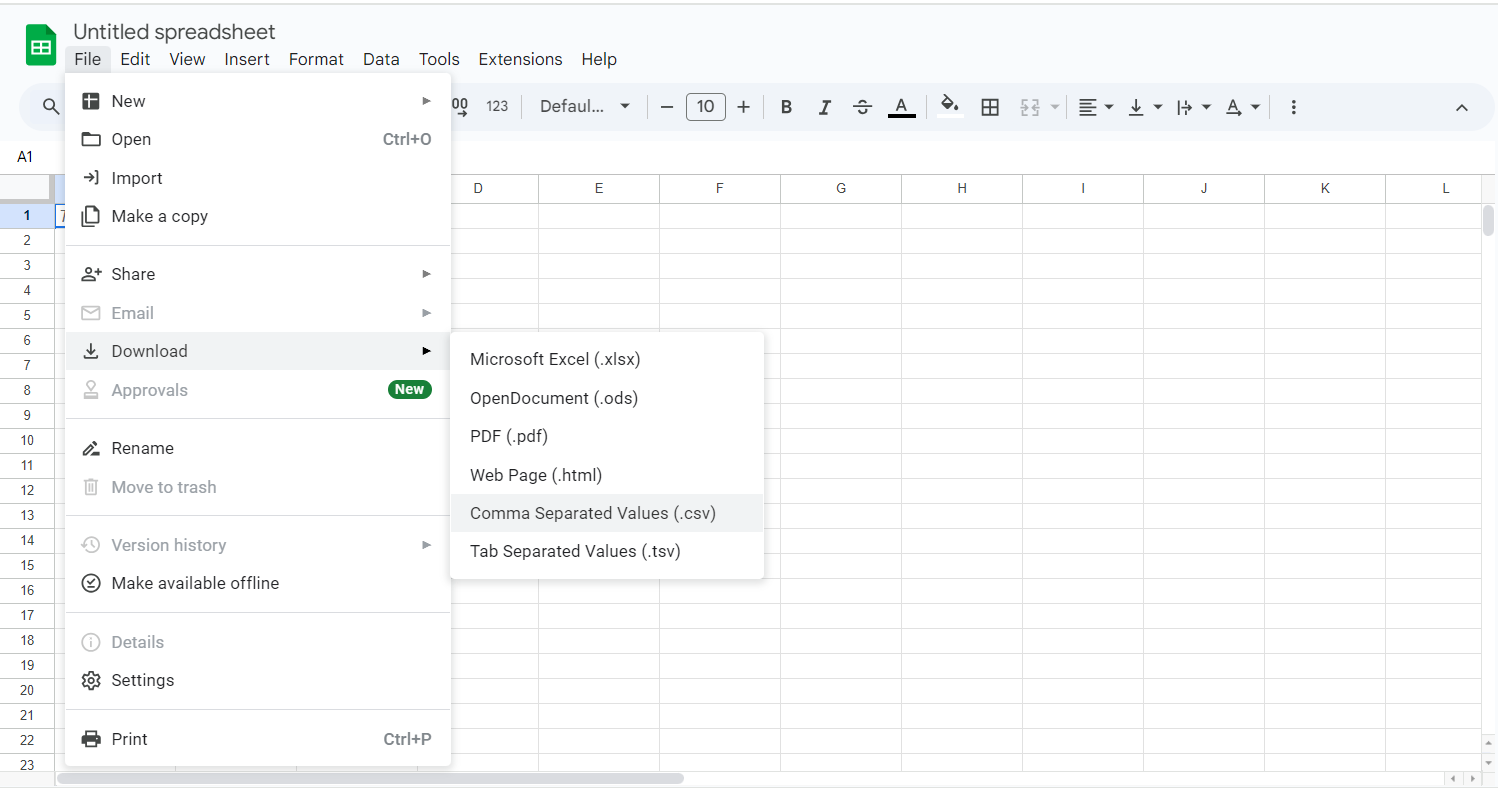
- The data will then be exported to CSV and will be downloaded to your local system. The same process can be followed if you wish to import data from multiple Google Sheets to Redshift.
Step 2: Loading Data to Amazon Redshift
Users can load their Google Sheets data to Redshift by implementing the following steps:
- Sign in to the AWS Management Console, open the Amazon S3 Console, and click on Create Bucket.

- Pick a suitable, unique name for your AWS S3 Bucket, select a region as per requirement, and click on Create.
- Open the AWS S3 Bucket that you just created, click on Create Folder, provide a suitable, unique name for it, and click on Save.
- Upload the Google Sheets CSV data exported previously to the newly created folder by clicking on Upload, selecting the necessary files in the Upload Wizard.
- The data in Amazon S3 can be imported into an Amazon Redshift Cluster using the COPY Command.
- Connect to the Cluster using a SQL Workbench tool of your choice and run the following query:
COPY table_name
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>'
CSV;- If you wish to ignore the file header rows in the CSV files, then you may also specify that by running the following query:
COPY table_name
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>'
CSV
IGNOREHEADER 1;Your data should now be accessible and queryable in your Amazon Redshift database.
Also, learn how to migrate data from Google Sheets to BigQuery.
Limitations of Manual Google Sheets to Redshift Migration
The limitations of setting up manual Google Sheets for Redshift Migration are as follows:
- Manual Google Sheets to Redshift Migration is a complex process that might be tough to perform for someone who does not have enough technical knowledge of Amazon Redshift.
- The process of exporting the data from Google Sheets and importing it into Amazon Redshift has to be done manually every time the data has to be updated in the Cluster.
- Every time the data is exported from Google Sheets, it will also include the data that was imported into Amazon Redshift previously. Hence, the existing records either have to be removed manually from the exported data before they are imported into Amazon Redshift, or duplicates have to be removed from Amazon Redshift once the data has been imported.
Conclusion
This article provided you with a step-by-step guide on how you can set up Google Sheets for Redshift Migration manually or using Hevo. However, there are certain limitations associated with the manual method. If those limitations are not a concern to your operations, then using it is the best option, but if it is, then you should consider using automated Data Integration platforms like Hevo.
Hevo helps you directly transfer data from a source of your choice to a Data Warehouse, Business Intelligence, or desired destination in a fully automated and secure manner without having to write code. It will make your life easier and make data migration hassle-free.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. Can Google Sheets connect to Redshift?
Yes, using Hevo Data, you can easily connect Google Sheets to Redshift, automating the process of transferring data between them.
2. How do I connect AWS to Google Sheets?
You can connect AWS to Google Sheets through APIs, third-party tools, or services like AWS Lambda for data integration.
3. How do I pull data from Google Sheets?
You can pull data from Google Sheets using Google Sheets API, Google Apps Script, or third-party integration tools to extract the data.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



