



As data-driven applications continue to grow, businesses are burdened with the complexity and expense of independently managing data. This complexity compounds when you have to aggregate data from various sources to enable better decision-making.
You need data to gain insight into analytical and organizational effectiveness, planning and monitoring business models, etc. A comprehensive approach is required to effectively capture and process large amounts of data, which includes employing well-designed data infrastructure and implementing data-driven solutions.
Companies must look for the most strategic approach to gather, transform, and extract value from data to remain competitive. This can be done with data pipelines. This article will teach you how to build a data pipeline and explain how it works.
Table of Contents
What Is a Data Pipeline?
A data pipeline is a series of automated data processing steps that allows data to move from multiple data sources to a destination (e.g., data lake or data warehouse). In a data pipeline, data may be transformed and updated before it is stored in a data repository.
The transformation step includes pre-processing that assures proper data integration and uniformity, such as cleaning, filtering, masking, and validating. It is a common practice to use both exploratory data analysis and well-defined business requirements to determine the type of data processing required for a data pipeline. The processed data can be the foundation for many data-driven applications, like visualization and machine learning activities.
To summarize, a data pipeline has numerous advantages, such as simplifying the movement, transformation, and processing of data, consistently and reliably. This helps organizations better use their data and get insights to make informed decisions.
Engineering teams must invest a lot of time and money to build and maintain an in-house Data Pipeline. Hevo Data ETL, on the other hand, meets all of your needs without needing or asking you to manage your own Data Pipeline. That’s correct. We’ll take care of your Data Pipelines so you can concentrate on your core business operations and achieve business excellence.
Here’s what Hevo Data offers to you:
- Diverse Connectors: Hevo’s fault-tolerant Data Pipeline offers you a secure option to unify data from 150+ Data Sources (including 60+ free sources) and store it in any other Data Warehouse of your choice. This way, you can focus more on your key business activities and let Hevo take full charge of the Data Transfer process.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the schema of your Data Warehouse or Database.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Components of a Data Pipeline
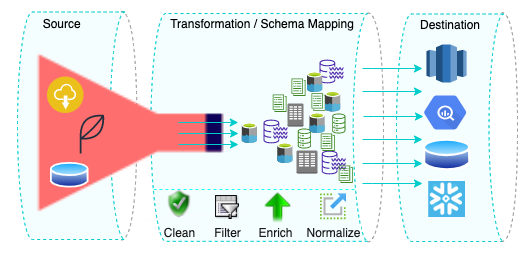
The components of a data pipeline can vary depending on the specific needs of the system, but some standard components include the following:
- Data Sources: These are the places where data originates. Examples of data sources include databases, websites, mobile applications, social media platforms, and IoT devices.
- Data Storage: This is where data is stored during the processing phase. Examples of data storage include distributed storage systems such as Hadoop or Apache Kafka.
- Data Processing: This component performs data transformations, such as filtering, merging, or cleaning, before delivering it to the destination. The duration of any transformation depends on the data replication strategy used in an enterprise’s data pipeline: ETL (extract, transform, load) or ELT (extract, load, transform).
- Data Sinks: These are the final destinations for the processed data. Examples of data sinks include data warehouses, data lakes, databases, and more. These are the centralized locations where organizations store their data for analysis and reporting purposes. Analysts and administrators can use this data for business intelligence and other analytics purposes.
- Dataflow: This is the movement of data from its point of origin to its point of destination and any modifications applied to it. Three of the most widely used approaches to data flow are ETL, ELT, and reverse ETL.
- Scheduling Systems: These are used to set up regular or recurring tasks that run at specific times or intervals. The tasks can include things like data ingestion, data processing, and data output.
- Monitoring Systems: These are used to keep track of the status of tasks, workflows, trigger alerts, and other actions when issues arise. This can include monitoring data quality, pipeline performance, and resource utilization.
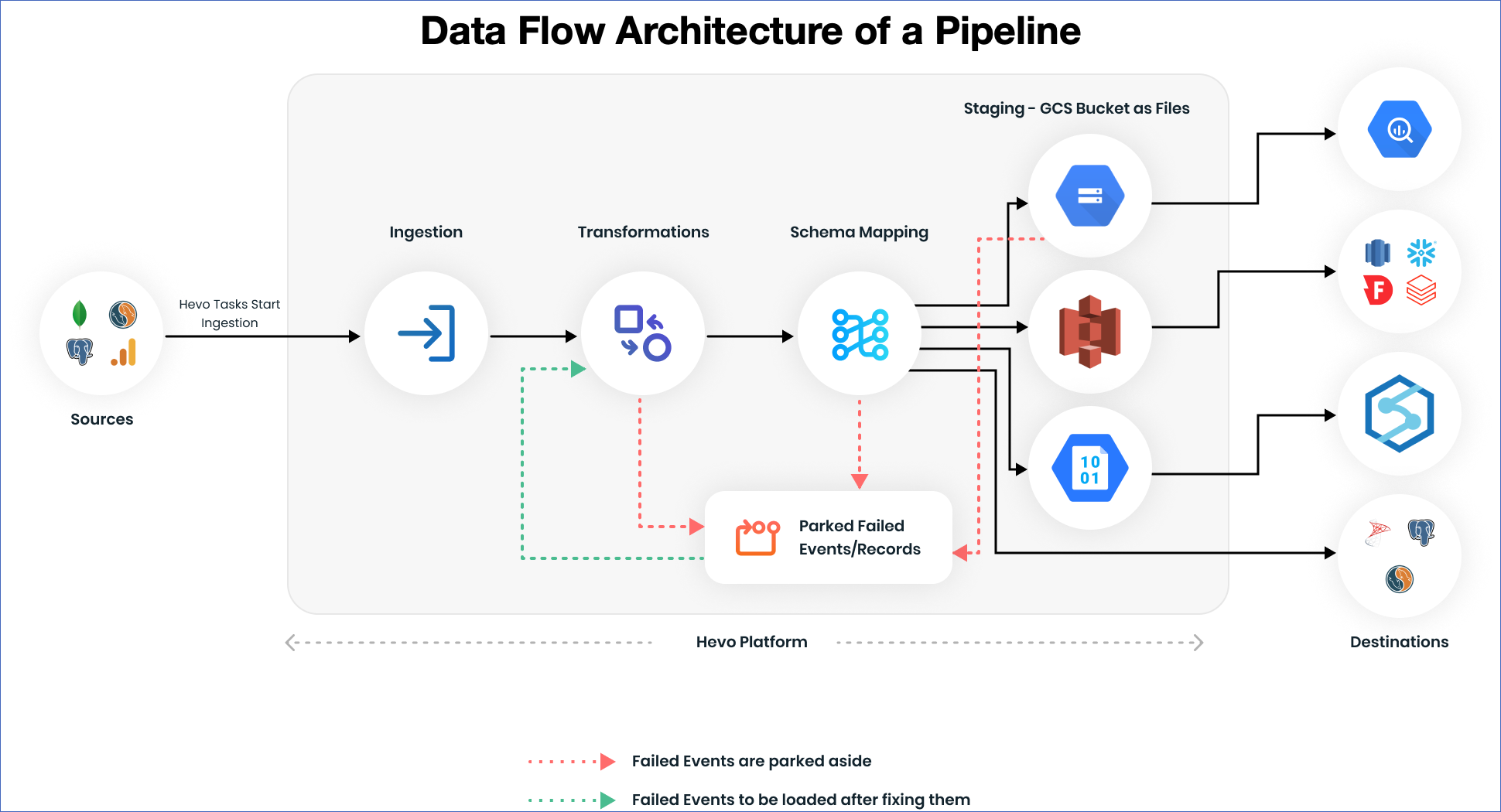
How Does a Data Pipeline Work?
The first step in a data pipeline is data intake or extraction. Here data is retrieved from multiple sources, making it accessible for additional processing. Depending on the data source, this can require executing API calls to get data, reading data from flat files, or running SQL queries to collect data from a database.
After the data has been extracted, it can either be:
- Transformed if needed, as per business requirements. Any necessary data modification or cleansing is done at this point. This can involve operations like deleting duplicates, changing data types, and filling in missing values.
- Transferred to a staging storage area or a final storage area. This involves delivering the data to an API, writing it to a file, or storing it in a data lake or a data warehouse.
It is important to note that a data pipeline can have
- Both the transformation and loading phases, where data transformation comes first.
- Both the transformation and loading stages, where data loading comes first.
- Only the loading phase, where data collected from sources is stored directly in a central repository.
Data pipelines also encompass steps to ensure data is correct, legal, and ethical. These include quality control, monitoring, data governance, and security. One way to ensure this is by incorporating real-time metrics to detect problems and take necessary action.
How to Build a Data Pipeline
Now, you might be wondering how to create a data pipeline. The following steps are often involved in building a data pipeline from scratch:



Have a Clear Understanding of Your Goal
- Identify your objectives behind building a data pipeline, available data resources and accessibility, time and budget constraints, pipeline success measurement metrics, and end-users.
- For instance, if you need data for building machine learning models, you would require a data pipeline to prepare datasets. This includes tasks such as feature engineering, data normalization, and splitting data into training and testing sets.
- On the other hand, pick a streaming data pipeline if your goal is real-time data processing and analysis in clickstream analysis, fraud detection, and IoT sensor data analysis.
- However, if you need real-time data but not continuous data streaming, you can use another type of data pipeline called lambda pipelines. A lambda pipeline is a blend of batch and streaming pipelines in one architecture.
- It is used when you want data based on events or triggers. Therefore, having a comprehensive understanding of your goal is essential.
Configuring Workflow
- Workflow identifies the order of processes in the pipeline and how they are interdependent. These dependencies may be business-related or technical. Business dependencies include cross-verifying data from one source against another to preserve integrity before consolidation.
- Technical dependencies include things like retaining data after it has been collected from sources, going through further validation steps, and then being moved to a destination. All these will influence your choice of data pipeline architecture.
- You can use workflow management solutions like Hevo Data to make building a data pipeline less challenging. These solutions allow data engineers to view and manage data workflows, even in the case of a failed task.
- Furthermore, some workflow management solutions automatically resolve dependencies and organize the pipeline processes.
Define the Data Source and Destination
- Identify where the data is coming from and where it needs to go. It could be a file on a server, a database, a web API, or some other data source.
Executing the Dataflow
Here, we are considering the ETL process as an example.
- Extract the data: After you have determined where the data is coming from, you need to extract it. This could require requesting data from databases such as Customer Relationship Management (CRM), Enterprise Resource Planning (ERP), and other apps using data extraction tools like Hevo Data.
- Prep the data as per your tailored needs: Generally, extracted data is in a raw format that is unsuitable for analysis or processing. You need to change it into a more suitable format as per the organizational requirements and standards. This involves cleaning, aggregating, checking for redundancy, and combining it with data from other sources.
- Where should you store it: After drawing data from sources and performing any necessary transformations, load it into its final destination. You can use either physical databases like RDS or data warehouses like Redshift or Snowflake.
Set-up Scheduling
- A data pipeline is often an automated operation that operates on a constant scheduling system.
- Whether it’s daily, hourly, or at another frequency, establish a schedule for the pipeline to run as per your organization’s goals.
Implement Monitoring Framework
- Monitor the data pipeline frequently to ensure data is correct and processed efficiently.
- Configure alerts to notify if possible failure scenarios (e.g., network congestion) arise within the data pipeline.
Make Changes
- After successfully setting up a data pipeline, you can introduce a few updates to accommodate any data ingestion or handling modifications.
- This might include tweaking the transformation stages, revising the schedule, or changing the data’s destination.
Auditing and Governance
- After building a data pipeline, you must carry out periodic pipeline audits. Set up data accuracy, validity, and integrity checks and ensure that the data conforms to relevant regulations or standards.
- Make sure to accomplish auditing via several techniques, such as manual data inspection, automated checks using scripts or tools, and data quality monitoring systems.
- You can even determine who will consume the final prepared data after the loading step of building a data pipeline. After deciding who will consume the data, check if you have the required data for end-user-based consumption, and ensure that the consumption tools can access this data efficiently.
Best Practices in Building a Data Pipeline
When you’re considering building vs buying a data pipeline, it’s crucial to have some key considerations that will help ensure efficiency, accuracy, and scalability. Some of the best practices include the following:
ETL vs ELT
- Choose whether most of the data transformation should be done before loading or if raw data should be loaded first and then transformed within the data warehouse. Both methods are useful in specific use cases, depending on the requirements of the data processing and available resources.
Data Quality
- Ensure that data validation checks are done at every step of the pipeline. This would help in accuracy and consistency in data. Data anomalies are reduced and the quality of insights is maintained through regular checks.
Scalability
- Design a pipeline that would accommodate increased data volume without losing its performance. Use scalable storage solutions and processing frameworks for accommodating future growth.
Security
- Proper access controls and encryption mechanisms will safeguard sensitive data. Data both at rest and in transit must be protected to adhere to security standards and regulations.
How to Build a Data Pipeline using Hevo Data
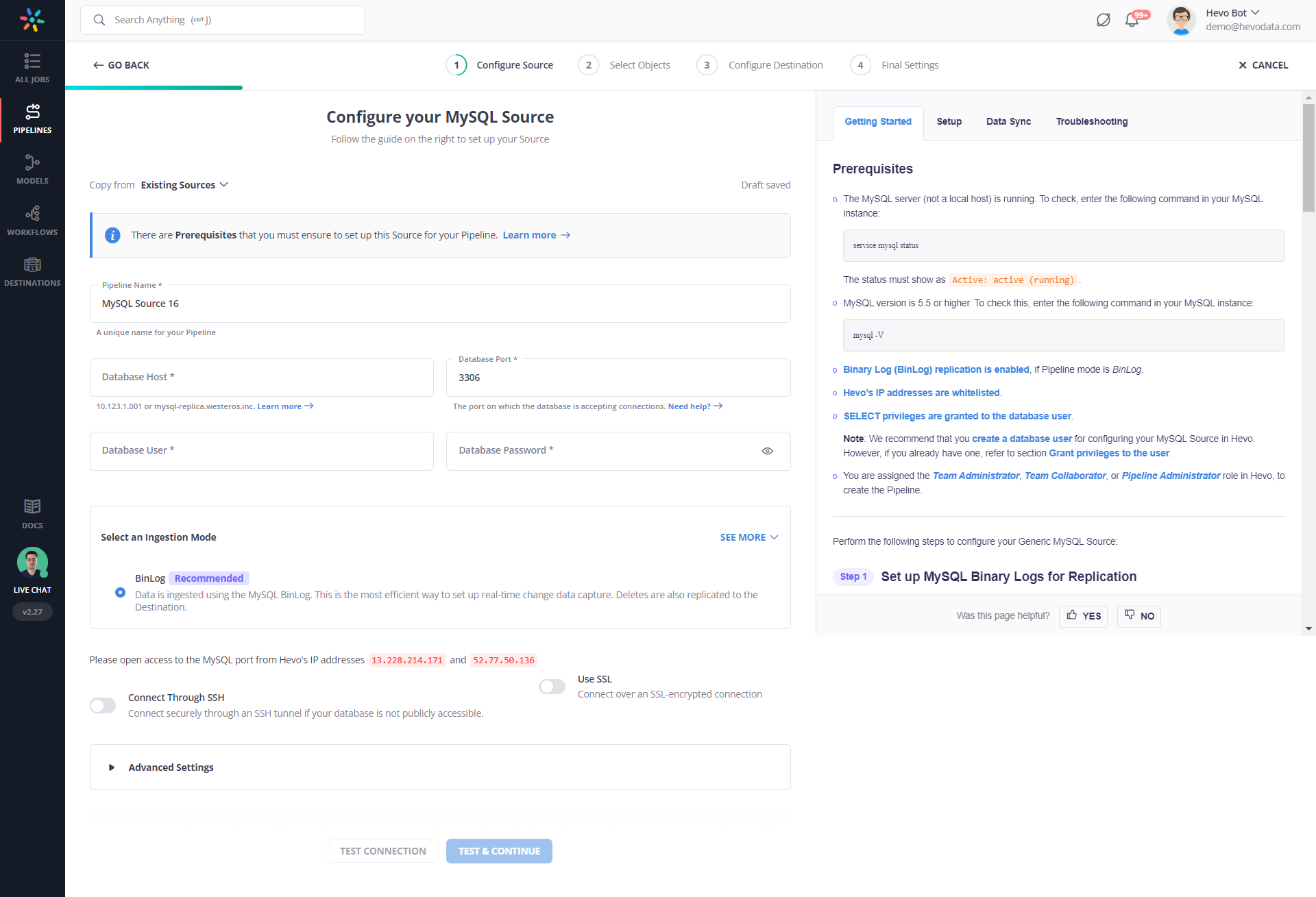
You can build an efficient data pipeline using tools such as Hevo Data in just two easy steps. For this example. For this example, I am taking an example of building a simple data pipeline from MySQL to Snowflake.
Step 1: Configure MySQL as your Source
Step 2: Connect your Snowflake account to Hevo’s Platform
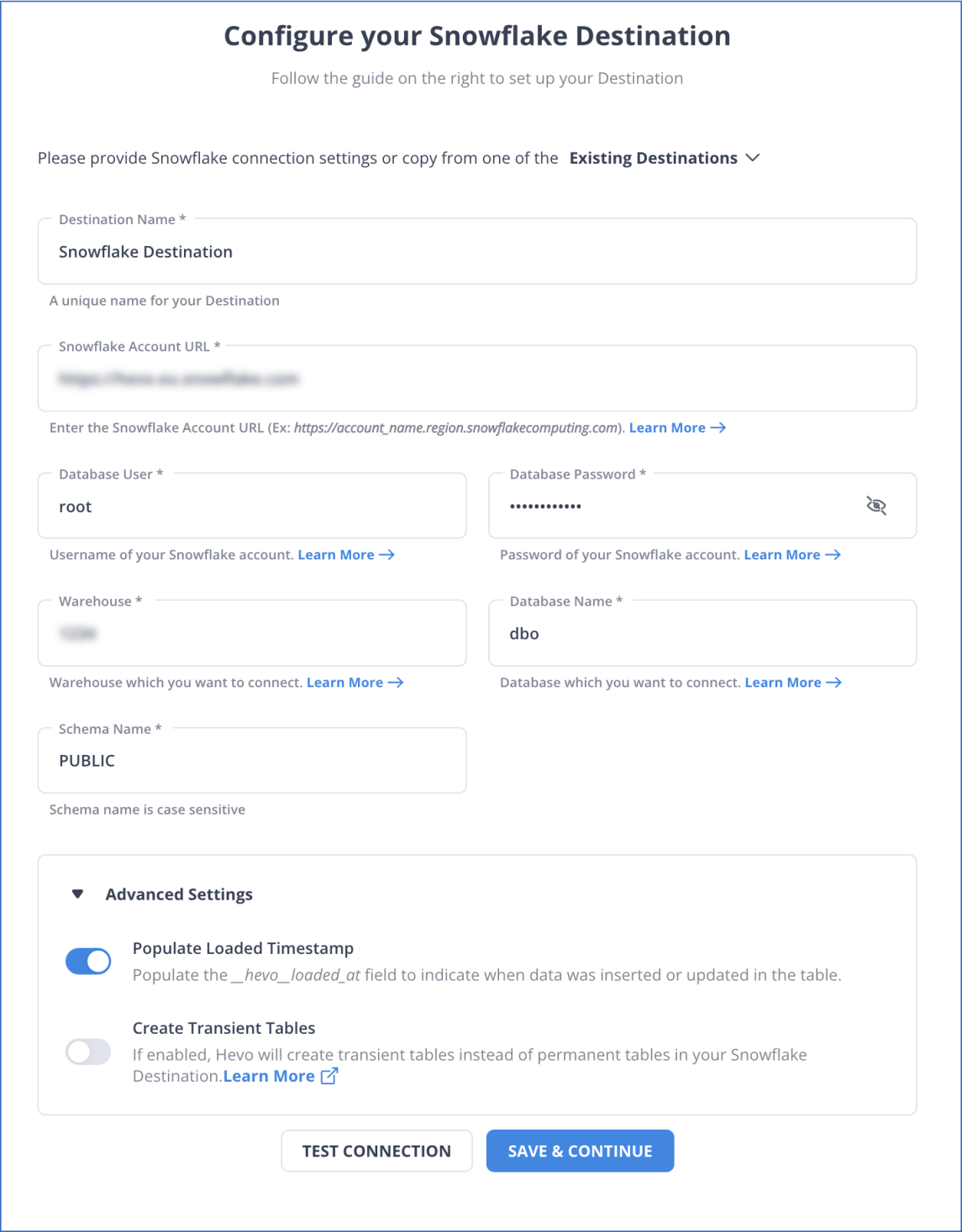
You have successfully connected your source and destination with these two simple steps. From here, Hevo will take over and move your valuable data from MySQL to Snowflake.
Learn More:
Final Thoughts
With businesses and organizations relying on data insights to make informed decisions, it is crucial to access disparate data sources through different types of data pipelines and know how to build a data pipeline.. Getting data from many sources into destinations can be a time-consuming and resource-intensive task.
Instead of spending months developing and maintaining such data integrations, you can enjoy a smooth ride with Hevo Data’s 150+ plug-and-play integrations (including 60+ free sources). Take Hevo’s 14-day free trial to experience a better way to manage your data pipelines.
You can also check out the unbeatable pricing, which will help you choose the right plan for your business needs.
Frequently Asked Questions
1. How to build a data pipeline step by step?
To build your data pipeline you need to achieve the following:
Define your objective, identify your data sources, choose right tools, decide pipeline architecture, ensure data ingestion to the pipeline, transform and cleanse the data, ensure the processed data is loaded in storage, get access to that data, finally monitor and maintain the pipeline while it is functional and scalable.
2. Is ETL a data pipeline?
Yes, ETL (Extract, Transform, Load) is a type of data pipeline that moves data from a
source to a destination while performing transformations along the way.
3. What is an example of a data pipeline?
An example of a data pipeline is using Hevo to automatically extract sales data from
Shopify, transform it to match your analytics requirements and load it into Snowflake for reporting.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





