



Modern business practices require efficient data asset management. AWS DocumentDB is a reliable and scalable solution for storing large amounts of data. However, as the data evolves, you must analyze it more sophisticatedly to gain profound insights.
This is where Databricks steps in, helping you derive value from varied data lakes and data warehouses in a consolidated environment. It has robust tools, including machine learning and generative AI models, which are suitable for data engineers and scientists to conduct experimentation.
Integrating data from AWS DocumentDB to Databricks allows you to perform analytics, understand the unique semantics of your enterprise data, and optimize performance.
In this article, you will explore how to integrate AWS DocumentDB to Databricks using different methods.
Table of Contents
Why Integrate Data from AWS DocumentDB to Databricks?
There are several advantages to DocumentDB integration with Databricks. Here are a few of them:
- Data migration from AWS DocumentDB to Databricks allows you to perform advanced analytics, machine learning tasks, and predictive analytics on your business data to extract actionable insights.
- After you load data from AWS DocumentDB to Databricks, you can use Apache Spark clusters to implement large-scale data processing and efficiently handle large amounts of data.
- You can analyze your business with Databricks real-time data streaming using Apache Spark Streaming and detect inconsistencies and anomalies. This helps you to stay updated with the current information.
- Databricks provides machine learning frameworks such as TensorFlow, PyTorch, and more, which can be used to build learning models to improve operational efficiency.
Overview of AWD DocumentDB
AWS DocumentDB is a database management service Amazon provides with MongoDB compatibility. It is fast and reliable and supports workloads with petabytes of storage capacity. Amazon DocumentDB runs on Amazon Virtual Private Cloud, so you can separate the database in your virtual environment and set up access controls.
It provides computing and storage services, helps you monitor instance failures, and automatically restarts associated processes, reducing restart times. The cluster’s point-in-time recovery in AWS DocumentDB provides you with backups and improves business performance.
Overview of Databricks
Databricks is a data-intelligent platform that enables you to build, share, and maintain your business data through its analytics and AI capabilities. It is built on the Apache Spark framework and helps you manage updates of your source integrations using its runtime releases. It also enables you to scale data according to your work needs.
Databricks’s collaborative workspace allows you to write code in different programming languages on shared notebooks across teams. It supports data ingestion from various sources and provides tools for data cleansing, transformation, and analysis. The built-in data science workflows and machine learning tools make building and deploying models accessible.


Methods to Integrate Data from AWS DocumentDB to Databricks
The following methods will teach you how to connect AWS DocumentDB to Databricks.
Method 1: Data Migration from AWS DocumentDB to Databricks Using CSV Files
Step 1: Export Data from AWS Document DB into CSV File
AWS DocumentDB uses the mongoexport tool to extract data from the AWS DocumentDB cluster and convert it to a CSV file on your local system.
mongoexport --ssl \
--host="sample-cluster.node.us-east-1.docdb.amazonaws.com:27017" \
--collection=sample-collection \
--db=sample-database \
--out=sample-output-file \
--username=sample-user \
--password=abc0123 \
--sslCAFile global-bundle.pemStep 2: Import Data from the CSV File to Databricks Using Add Data UI
You can use Add Data UI in Databricks to ingest data from a CSV file to Databricks. Follow the steps below for this:
- Login to your Databricks account, go to the Navigation Pane and click on New.
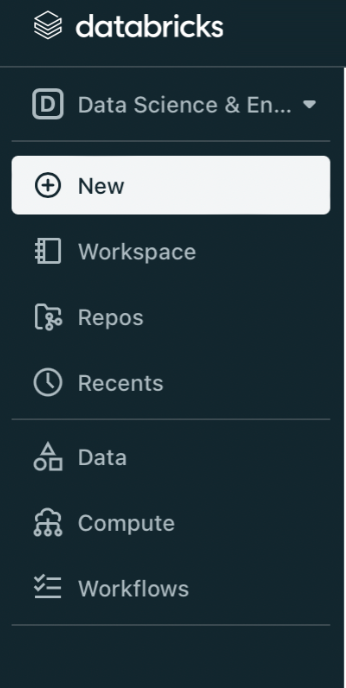
- Click on Data>Add Data.
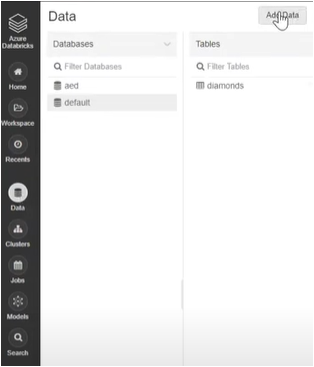
- Then, find or drag and drop your CSV files directly into the drop zone.
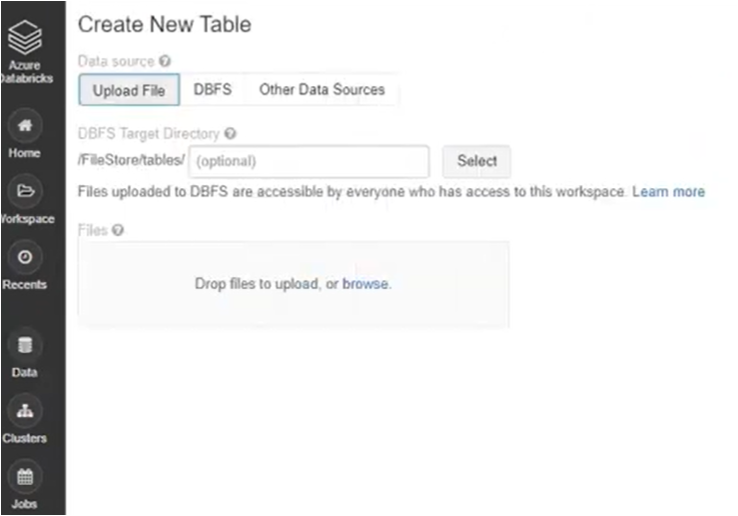
- You can choose either Create Table in UI or Create Table in Notebook.
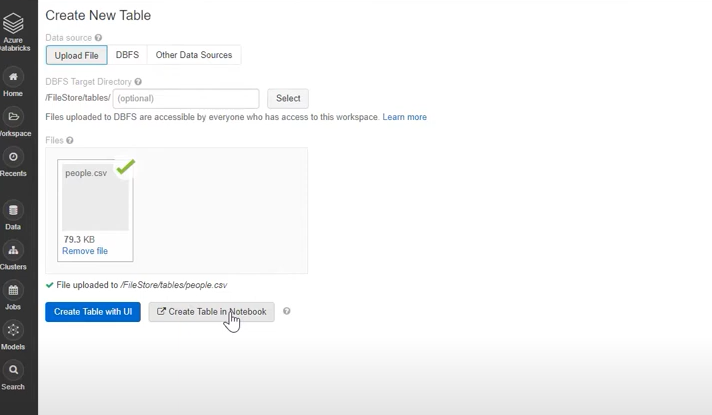
- Execute the Run command in the Notebook to view the exported CSV data in Databricks.
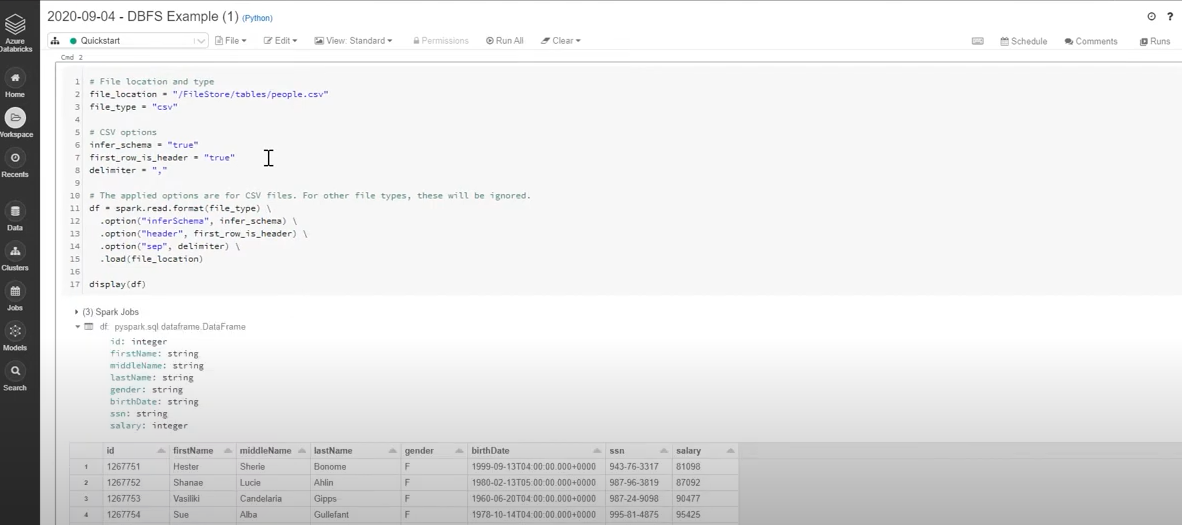
Limitations for Data Migration from AWS DocumentDB to Databricks Using CSV Files
- CSV files don’t support large data files with complex data types, making it difficult to process data on a large scale and perform advanced analytics.
- The mongoexport tool doesn’t support parallel exports when extracting data from the AWS DocumentDB. It means you can not break your exports into smaller parts to speed up the process.
- In Databricks, the file upload page support allows you to upload ten files at a time. This means you must collect data in batches, which makes the process lengthy.
Method 2: Connecting AWS DocumentDB to Databricks Using Hevo
Hevo is a real-time ELT platform that enables you to cost-effectively connect AWS DocumentDB to Databricks using its no-code, flexible, and automated data pipeline. It allows you to transfer and refine your source data, preparing it for analysis. Hevo offers 150+ data sources from where you can migrate your data to your targeted destination.
Benefits of Using Hevo
- Data Transformation: Hevo offers Python-based and drag-drop data transformation, which helps you clean your data before migrating it into a targeted system.
- Automated Schema Mapping: This feature of Hevo enables you to automatically read and replicate source data’s schema into the desired destination.
- Incremental Data Loading: Hevo allows you to upload modified and updated data into your destination instead of loading all the data sets again.
Let’s see how Hevo helps you quickly load data from AWS DocumentDB to Databricks.
Step 1: Configure AWS DocumentDB as Your Source
Hevo uses Document DB Change Stream to migrate data from AWS DocumentDB to the destination of your choice.
Prerequisites:
- You must have an active Amazon Web Service account, and the document version should be 4.0 or higher.
- Create an Amazon DocumentDB cluster and cluster parameter group.
- You must have an active Amazon EC2 instance to make a connection.
- You need to create a security group for the DocumentDB cluster for the AWS EC2 console.
- Whitelist your Hevo’s IP addresses.
- Create a user for your DocumentDB and set up permission to read.
- Install mongo shell for your operating system and connect it to your DocumentDB cluster.
- Enable Streams and modify the change in stream log retention duration.
- To create a pipeline in Hevo, you must have the following roles: Team Administrator, Team Collaborator, or Pipeline Administrator.
Follow the steps to configure AWS DocumentDB connection settings.
- Go to the PIPELINES in the Navigation Bar.
- Click on +CREATE in the Pipeline List View.
- On the Select Source Type page, select Amazon DocumentDB as your source.
- On the Configure your Amazon DocumentDB Source page, specify the mandatory details.
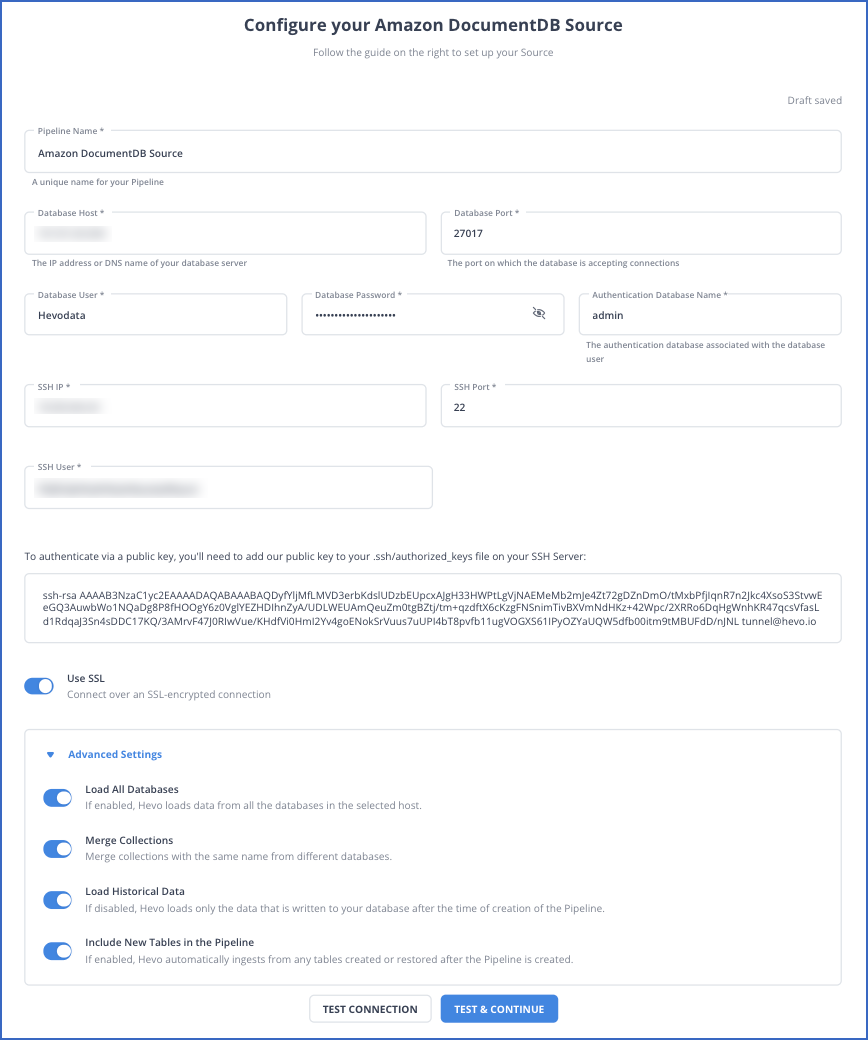
Refer to Hevo documentation to configure AWS DocumentDB as your source.
Step 2: Configure Databricks as Your Destination
Prerequisites:
- An active AWS, GCP, or Azure account should be available.
- Create a Databricks workspace on the cloud service account.
- Enable the IP access list feature and connect it to your Databricks workspace.
- The URL of the Databricks workspace must be available in the format – https://<deployment name>.cloud.databricks.com.
- To connect to the Databricks workspace for data ingestion, you must meet the following requirements:
- Create an SQL warehouse or Databricks cluster.
- The port number, HTTP Path, and database hostname for the database cluster must be available.
- The Personal Access Token must be available.
- Get your Databrick cluster’s credentials.
- You must be assigned the role of any administrator, except for the Billing Administrator, to create the destination in the Hevo data pipeline.
You can link Databricks as your destination using a recommended method: Databricks Partner Connector.
Follow the steps to configure your destination:
- Select DESTINATIONS from the Navigation Bar.
- Click on +CREATE in the Destination View Lists.
- Select Databricks as the destination on the Add Destination Page.
- On the Configure Databricks as your Destination page, specify the following details.
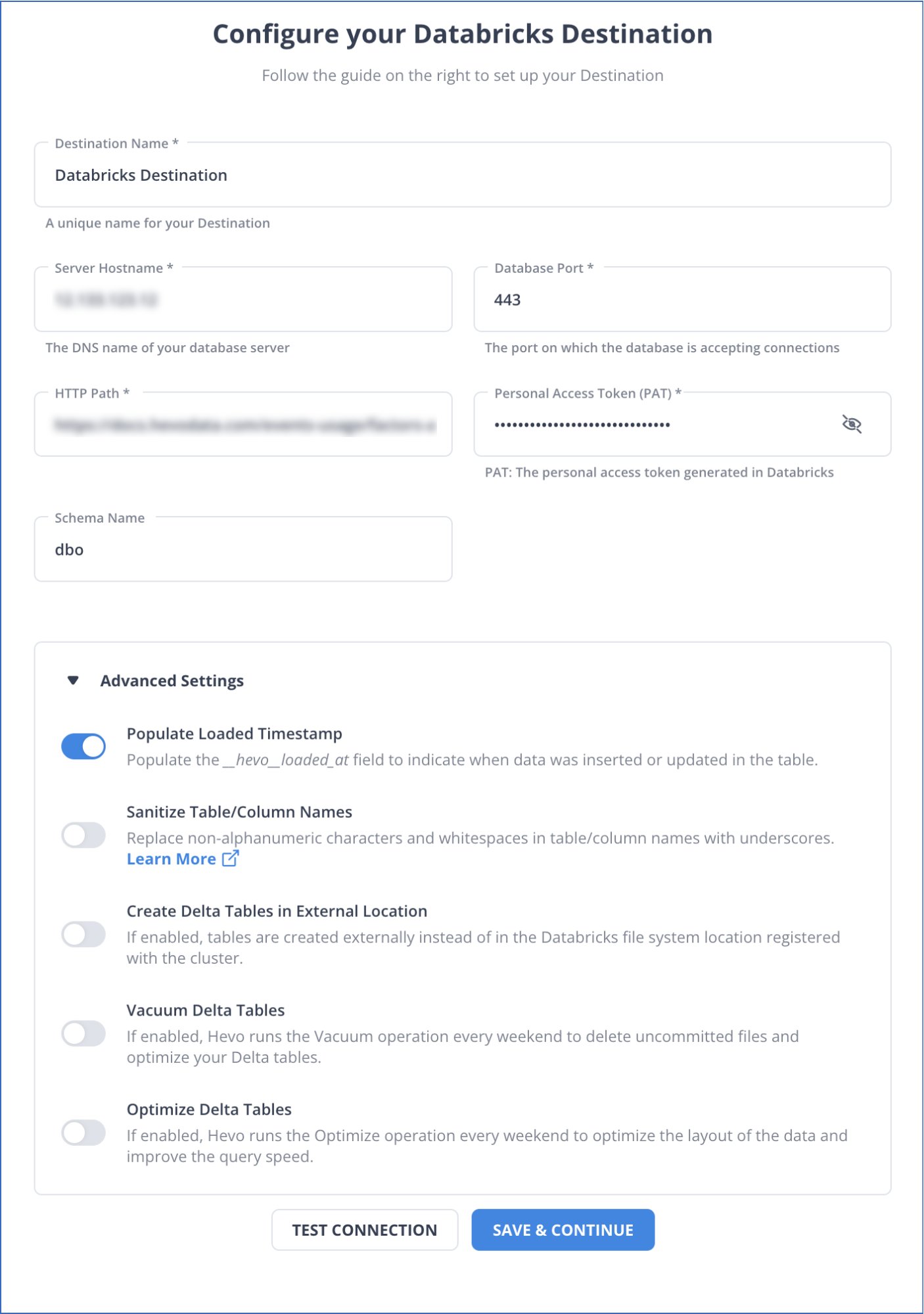
Refer to the Hevo documentation to configure Databricks as your destination.
Use Cases of AWS DocumentDB to Databricks
There are many applications for DocumentDB integration with Databricks. Some of them are:
- Implementing Collaborative Workspace: Databricks offers a collaborative workspace with a multi-user environment. These workspaces can be used to share information and build interactive dashboards to improve performance efficiency.
- Enhance Customer Experience: Integrating data from AWS DocumentDB to Databricks lets you use Databricks machine learning capabilities to develop predictive models. These models help you study customer lifecycle and make personalized recommendations for improving their experience.
Learn how building a strong data migration team can streamline the process of migrating data from AWS DocumentDB to Databricks efficiently.
You can also learn more about:
- Databricks to SQL Server
- Azure MySQL to Databricks
- Amazon S3 to Databricks
- GCP Postgres to Databricks
Conclusion
Integrating data between AWS DocumentDB and Databricks allows you to perform advanced analysis on finance data to predict risks, enhance your supply chain by analyzing the cost of inventory and demand for products, and much more. You can use CSV Files for data ingestion, which can be challenging as it does not support large-scale data processing, or you can use Hevo. Hevo’s no-code automated data pipeline integrates large amounts of data smoothly between two platforms.
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also checkout our unbeatable pricing to choose the best plan for your organization.
Share your experience of AWS DocumentDB to Databricks integration in the comments section below!
FAQs (Frequently Asked Questions)
Q. Can you connect TLS-enabled DocumentDB from the database instance in Databricks?
You can not connect TLS-enabled DocumentDB from the database instance in Databricks. To do that, all the nodes in the Databricks clusters should be the loading file connected to Spark, but it gets timed out.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



