

Amazon S3 is a prominent data storage platform with multiple storage and security features. Integrating data stored in Amazon S3 to a data warehouse like Databricks can enable better data-driven decisions. As Databricks offers a collaborative environment, you can quickly and cost-effectively build machine-learning applications with your team.
Integrating data from Amazon S3 to Databricks makes it easier to build these ML applications, as Databricks provides an interactive notebook option. With data present on Databricks, you can deploy your application on multiple platforms, including Azure, AWS, and GCP.
This article will explore six popular methods to connect Amazon S3 to Databricks.
Table of Contents
An Overview of Amazon S3

Amazon S3 is a storage service on the AWS cloud ecosystem that offers availability, security, scalability, and high performance. It enables you to store and protect data that you can use for any use case, including building data lakes, mobile applications, and cloud-native applications.
Using Amazon S3, you can manage large volumes of data, organize it, and set up fine-tuned access control to meet business needs. It allows the building of high-performance computing applications that can cost-effectively maximize performance. You can also stream your data to Amazon S3.
An Overview of Databricks

Databricks is a data lakehouse platform that enables you to perform SQL and performance enhancement tasks, including caching, indexing, and massively parallel processing (MPP). It provides a cost-effective solution for building AI models while maintaining control, quality, and privacy.
Databricks provides a cloud-based data warehouse service for serverless data management, so you won’t need to worry about data infrastructure. You can search the data using natural language and monitor and observe it with an AI-driven solution.
Easily integrate your Amazon S3 data with Databricks using Hevo’s no-code platform. Automate your data pipeline for real-time data flow and seamless analysis.
- Quick Integration: Connect Amazon S3 to Databricks with just a few clicks.
- Real-Time Sync: Ensure up-to-date data with continuous real-time updates.
- No-Code Transformations: Apply data transformations without writing any code.
- Reliable Data Transfer: Enjoy fault-tolerant data transfer with zero data loss.
Simplify your S3 to Databricks data workflows and focus on deriving insights faster with Hevo.
Get Started with Hevo for FreeWhy Migrate Amazon S3 to Databricks?
Migrating data from Amazon S3 to Databricks can have many advantages.
- With this integration, you can have an additional data backup, ensuring data protection and security while sharing data over different platforms using Delta Sharing.
- Moving data from Amazon S3 to Databricks can enable you to use features like filtering, cleaning, and performing advanced analytics on data.
- Databricks provides a data warehousing platform for quickly performing complex queries. Features like Mosaic AI enable machine-learning capabilities for model training, feature management, and model serving.
- Integrating Amazon S3 with Databricks can help you process your data faster. Databricks provide functionality like multiple parallel processing that can improve performance.
- Moving data from Amazon S3 to Databricks enables users to manage big data with Apache Spark’s help, as Databricks has native integration with Apache Spark.
Discover how the Databricks DATEDIFF function can enhance your data integration workflows in our detailed guide.
Methods to Load Data from Amazon S3 to Databricks
Are you wondering how to load Amazon S3 data in Databricks? This section discusses the most prominent methods to connect Amazon S3 to Databricks.
Method 1: Using Hevo to Sync Amazon S3 to Databricks
Step 1: Configure Amazon S3 as a Source
This section will discuss the steps to set up Amazon S3 as a source in Hevo Data. But before proceeding, you must satisfy the prerequisites.
Prerequisites:
- You must have an active AWS account and an S3 bucket to ingest data.
- You must log in as an IAM user with the necessary privileges:
- You must create an IAM policy and an IAM role (to produce IAM role-based credentials)
- You can create an IAM user (to generate access credentials).
- You must have access credentials or IAM role-based credentials to authenticate Hevo on your AWS account.
- You must be a Team Administrator, Pipeline Administrator, or Team Collaborator in Hevo.
After satisfying the prerequisites, you can follow these steps:
- Select PIPELINES in the Navigation Bar and click on + CREATE from the Pipeline List View.
- Select S3 in the Select Source Type page.
- Specify the mandatory fields on the Configure your S3 Source page
- Select TEST & CONTINUE.

Step 2: Configure Databricks as a Destination
Following the steps in this section, you can quickly configure Databricks as your data pipeline destination. Hevo supports Databricks integration on the AWS, Azure, and GCP platforms. You can follow two different methods to integrate Databricks as a destination on Hevo, including the recommended Databricks Partner Connect and using Databrick Credentials.
Before getting started, you must ensure you satisfy the prerequisites.
Prerequisites:
- You must have an active AWS, Azure, or GCP account.
- You must create a Databricks workspace on your preferred cloud platform.
- Enable the IP address list features on the cloud platform you use. You can perform this by having Admin access.
- You must have the URL of your Databricks workspace. It would be in the https://<deployment name>.cloud.databricks.com format.
- You must create a Databricks cluster or SQL warehouse.
- You must have the port number, hostname, and the HTTP path. Refer to obtain credentials to know more.
- You must have the Personal Access Token (PAT).
- You must be assigned as a Team Collaborator or to any administrative post apart from Billing Administrator in Hevo.
After satisfying all the prerequisite conditions, follow the steps below:
- Select DESTINATIONS from the Navigation Bar and click + CREATE in the Destinations List View.
- Select Databricks on the Add Destination page.
- Specify the mandatory details on the Configure your Databricks Destination page.
- Finally, click on TEST CONNECTION and select SAVE & CONTINUE. You can follow the instructions to identify the external location for Delta Tables.

Method 2: Accessing S3 Data in Databricks Using Apache Spark
This method uses Apache Spark to access Amazon S3 data and move it to Databricks. You can convert Amazon S3 to Databricks table by following these steps:
- You must set Apache Spark properties to set the AWS key to access S3.
- You can use secret scopes to store your credentials, granting users the necessary privileges to protect the AWS key.
- You can use cluster access control and notebook access control to protect access to Amazon S3. Refer to collaborate using Databricks notebook and computation permission.
You can use this code snippet in the cluster’s Spark configuration to set Spark properties with the AWS key that is present in secret scopes as environment variables:
AWS_SECRET_ACCESS_KEY={{secrets/scope/aws_secret_access_key}}
AWS_ACCESS_KEY_ID={{secrets/scope/aws_access_key_id}}
Finally, you can use the following command to read data from Amazon S3:
aws_bucket_name = "my-s3-bucket"
df = spark.read.load(f"s3a://{aws_bucket_name}/flowers/delta/")
display(df)
dbutils.fs.ls(f"s3a://{aws_bucket_name}/")
To learn more about the steps mentioned, refer to Connect to Amazon S3.
Limitations of Using Apache Spark to Connect Amazon S3 to Databricks
Although Amazon S3 to Databricks integration using Apache Spark is efficient, certain limitations come with this method. Here are some of the limitations of using Apache Spark for Amazon S3 to Databricks integration:
- Complexity: This method requires prior technical knowledge to integrate data from Amazon S3 to Databricks. During this process, you might have to read about certain concepts, which can consume additional time.
- Lack of Real-Time Integration: Accessing data from Amazon S3 to Databricks using Apache Spark can introduce some latency in the data transfer process. It can alter the data flow, resulting in the integration process lacking real-time features.
Method 3: Access Amazon S3 Bucket Using Instance Profiles
You can follow the steps given in the section to connect Amazon S3 to Databricks:
- You must create an IAM role with access to the necessary S3 bucket and ensure the role has permission to read data from the S3 buckets you are accessing.
- You must configure S3 access with the instance profile using the Databricks workspace interface.
- After adding the instance profile to the Databricks workspace, you must grant users, groups, or service principals access to launch clusters with instance profiles. To learn more, follow the steps to manage instance profiles in Databricks.
- You must implement cluster and notebook access control to secure access to the instance profile. You can refer to compute permissions and collaboration using Databricks notebooks.
For a broader perspective on AWS’s advancements, check out how Amazon S3 tables are shaping the open table format landscape.
Limitations of Using Instance Profiles to Connect Amazon S3 to Databricks
- Security Issues: Since one IAM role is associated with the instance profile, all users on a cluster using that profile can share the same access permissions for that role.
Method 4: Integrating Amazon S3 with Databricks Using Hadoop
This method highlights the integration of data from Amazon S3 with Databricks using Hadoop. Follow the steps below to do so:
- You must configure the S3A filesystem using open-source Hadoop options in Databricks runtime.
- To configure the global properties, follow this code snippet:
# Global S3 configuration
spark.hadoop.fs.s3a.aws.credentials.provider <aws-credentials-provider-class>
spark.hadoop.fs.s3a.endpoint <aws-endpoint>
spark.hadoop.fs.s3a.server-side-encryption-algorithm SSE-KMS
- To configure per-bucket properties, you can remove the <placeholders> from the code syntax below using the specific options you want.
# Set up authentication and endpoint for a specific bucket
spark.hadoop.fs.s3a.bucket.<bucket-name>.aws.credentials.provider <aws-credentials-provider-class>
spark.hadoop.fs.s3a.bucket.<bucket-name>.endpoint <aws-endpoint>
# Configure a different KMS encryption key for a specific bucket
spark.hadoop.fs.s3a.bucket.<bucket-name>.server-side-encryption.key <aws-kms-encryption-key>
Limitations of Using Hadoop to Connect Amazon S3 to Databricks
- File Size Limitation: Hadoop requires large files for efficient processing, but Amazon S3 has a maximum file size limit of 5 gigabytes.
- Time Consumption: The S3A option, which makes Amazon S3 bucket appear in a Hadoop-compatible filesystem, can slow down the data transfer process, consuming your time.
Method 5: Onboard Data from Amazon S3 to Databricks Using Unity Catalog
Using the Unity catalog, this method discusses data onboarding from Amazon S3 to Databricks. Before getting started, ensure you satisfy the given prerequisites.
Prerequisites:
- You must access the Databricks workspace with the Unity catalog enabled. To learn more, refer to setting up and managing the Unity catalog.
- You must grant READ FILES permissions on the Unity catalog external volume or the location corresponding to your cloud storage containing the source data. For more information, refer to create an external location to connect cloud storage to Databricks.
- You must have the path to your source data.
- You must have the USE SCHEMA and CREATE TABLE privileges on the schema you are trying to load the data into.
- You must have the cluster creation permission or access to the cluster policy that defines a data lake pipeline cluster.
- You must create a cluster and a data exploration notebook.
After satisfying the prerequisites, you can follow the steps given below to move data from Amazon S3 to Databricks.
- On the sidebar, click New and then select Notebook.
- Enter the name of the notebook.
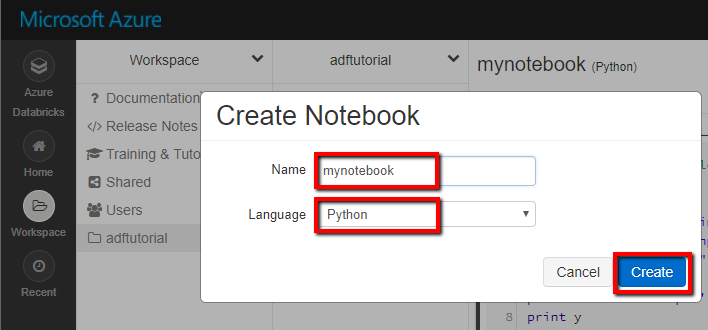
- Click on the language option and select Python. Paste the following code in the notebook cell by replacing the placeholder values:
@dlt.table(table_properties={'quality': 'bronze'})
def <table-name>():
return (
spark.readStream.format('cloudFiles')
.option('cloudFiles.format', '<file-format>')
.load(f'{<path-to-source-data>}')
)
- You can also create and publish a pipeline in the Unity catalog.
- Finally, you can schedule the pipeline.
Limitations of Onboarding Data from Amazon S3 to Databricks using Unity Catalog
- Lack of ML Support: Shared access mode on the Unity catalog does not support Spark-submit jobs and machine learning libraries such as DataRuntime ML and Spark Machine Learning Library (MLlib)
- Restrictions on View: The Unity catalog’s single-user access mode can restrict the dynamic views and querying tables created by the Delta Live Tables pipeline.
Method 6: Mount an S3 Bucket to Databricks
This method highlights how to mount an S3 bucket to Databricks. Follow the steps given below:
- You must download the Access keys from AWS and upload the Excel file in the DBFS location.
- You must read the file as a Spark DF using the given syntax.
aws_keys_df = spark.read.load("/FileStore/tables/<Your Folder>/<File Name.csv>", format="csv", inferSchema="true", header="true")- You must extract and store the values of access and secret keys in two different variables.
ACCESS_KEY = aws_keys_df.select('Access key ID').take(1)[0]['Access key ID']
SECRET_KEY = aws_keys_df.select('Secret access key').take(1)[0]['Secret access key']
- You must encode the secret key by importing urllib library.
import urllib
ENCODED_SECRET_KEY = urllib.parse.quote(string=SECRET_KEY, safe="")
- You must create two variables, one for the S3 bucket name and another for the mount name.
AWS_S3_BUCKET = '<your s3 bucket name>'
MOUNT_NAME = '/mnt/mount_s3'
- You can now connect S3 to Databricks and run it.
SOURCE_URL = 's3a://%s:%s@%s' %(ACCESS_KEY,ENCODED_SECRET_KEY,AWS_S3_BUCKET)
dbutils.fs.mount(SOURCE_URL, MOUNT_NAME)
- You can check for the connection by following the given syntax:
%fs ls '/mnt/mount_s3/<your file name>'- Finally, you can convert your file into a Spark Dataframe. Follow the given command:
aws_s3_df = spark.read.load("/mnt/mount_s3/<File Name.csv>", format="csv", inferSchema="true", header="true")
display(aws_s3_df)

Limitations of Mounting an S3 Bucket on Databricks
- Security Issues: All the users can have read and write access to all the objects in the bucket, which can lead to security issues.
- Limitations in Options: Databricks does not support mounting an S3 bucket using an AWS key in GCP. Therefore, this option is only available for limited options, including Azure and AWS.
To reverse the data integration process and connect Databricks to Amazon S3, refer to Databricks to S3.
You can also read more about:
Conclusion
This article highlights six methods for moving data from Amazon S3 to Databricks table. Both methods can efficiently sync Amazon S3 to Databricks, but almost all the methods have limitations.
Discover how to integrate AWS DocumentDB with Databricks for powerful data processing. Get the details at DocumentDB to Databricks Integration.
You can easily overcome these challenges by leveraging Hevo’s features to integrate data from Amazon S3 to Databricks. Hevo allows you to extract your data from 150+ data source connectors. With its highly interactive user interface, you can integrate data without prior coding knowledge.
Frequently Asked Questions (FAQs)
1. How to load data from S3 into Databricks?
You can easily load data from S3 into Databricks using Hevo Data’s no-code platform, which automates the entire process. Alternatively, you can manually set up AWS credentials in Databricks and use commands like `spark.read.format(“csv”).load(“s3://your-bucket-name/file.csv”)` to import your data.
2. How do I connect my S3 bucket to Azure Databricks?
Use Hevo Data to connect your S3 bucket to Azure Databricks without coding. Hevo automates data transfer between S3 and Databricks seamlessly. Alternatively, you can manually set up AWS access keys in Databricks and use the `spark.conf.set` command to connect to your S3 bucket.
3. How to connect AWS to Databricks?
Hevo Data provides a fully managed solution to connect AWS services like S3 directly to Databricks, enabling real-time data transfer without any coding. Alternatively, you can configure AWS access keys in Databricks and use its built-in capabilities to access data from AWS storage.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





