




Easily move your data from AWS Aurora Postgres To Databricks to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time—check out our 1-minute demo below to see the seamless integration in action!
Effective data migration is the key to overcoming the challenges associated with today’s data-driven world. The AWS Aurora Postgres to Databricks integration offers data storage and analytics solutions that help unlock the full potential of your organization’s operational data.
Through this integration, you can achieve the simplicity and cost-effectiveness of AWS Aurora Postgres databases with Databricks’ advanced analytics and machine learning capabilities. As a result, your organization can uncover valuable insights to drive smarter business decisions.
This article will guide you through the two easy methods for a smooth integration between the AWS PostgreSQL and BigQuery. Let’s dive in!
Table of Contents
Why Integrate AWS Aurora for Postgres with Databricks?
AWS Aurora for Postgres restricts your organization with vendor lock-in and proprietary data formats. When integrating AWS Aurora Postgres with Databricks, Databricks fosters innovation through its large community of developers and support for popular data formats.
Databrick’s Lakehouse architecture and Delta Lake framework are built on open standards and have no proprietary data formats. The open philosophy of Delta Lake allows you to implement a data warehousing compute layer on top of a conventional data lake.
Method 1: Migrate AWS Aurora Postgres to Databricks Using Hevo Data
Hevo Data is a no-code, real-time ELT platform that provides cost-effective automated data pipelines based on your specific requirements. By integrating with over 150+ data sources, Hevo can extract the data, load it to different destinations, and help you transform it for detailed analysis.
Method 2: Migrate AWS Aurora Postgres to Databricks Using Amazon S3 and Delta Tables
To sync AWS Aurora Postgres to Databricks, you must first move your data into an Amazon S3 bucket. Then, load the data files into Databricks by creating a Delta Table using a PySpark API.
Get Started with Hevo for FreeAWS Aurora Postgres: A Brief Overview
AWS Aurora Postgres is an Amazon Aurora variant compatible with the ACID-Compliant Postgres database engine. It is a cost-effective and easy-to-use alternative to PostgreSQL databases.
Using AWS Aurora Postgres, you can easily set up, operate, and scale new and existing PostgreSQL deployments. It integrates with other AWS services, such as AWS Lambda for serverless computing, Amazon S3 for backups and storage, and Amazon RDS for relational databases.
With AWS’s Business Associate Agreement (BAA), you can utilize AWS Aurora PostgreSQL to develop HIPAA-compliant applications and store Protected Health Information (PHI).
Databricks: A Brief Overview
Databricks is the world’s first data intelligence platform, founded by the Apache Spark creators. It provides a workspace for data scientists, engineers, and analysts to build, deploy, distribute, and maintain data-driven AI applications.
Databricks is built on a lakehouse architecture to provide a unified foundation for data management and governance. It combines data lakehouse with generative AI to automatically optimize performance and maintain the infrastructure according to the business needs.
With Databricks, everyone in your organization can utilize AI using natural language to derive deeper insights for data analysis and decision-making.
Methods for Integrating AWS Aurora Postgres to Databricks
Method 1: Migrate AWS Aurora Postgres to Databricks Using Hevo Data
Here are the steps to save AWS Aurora Postgres to Databricks using Hevo Data:
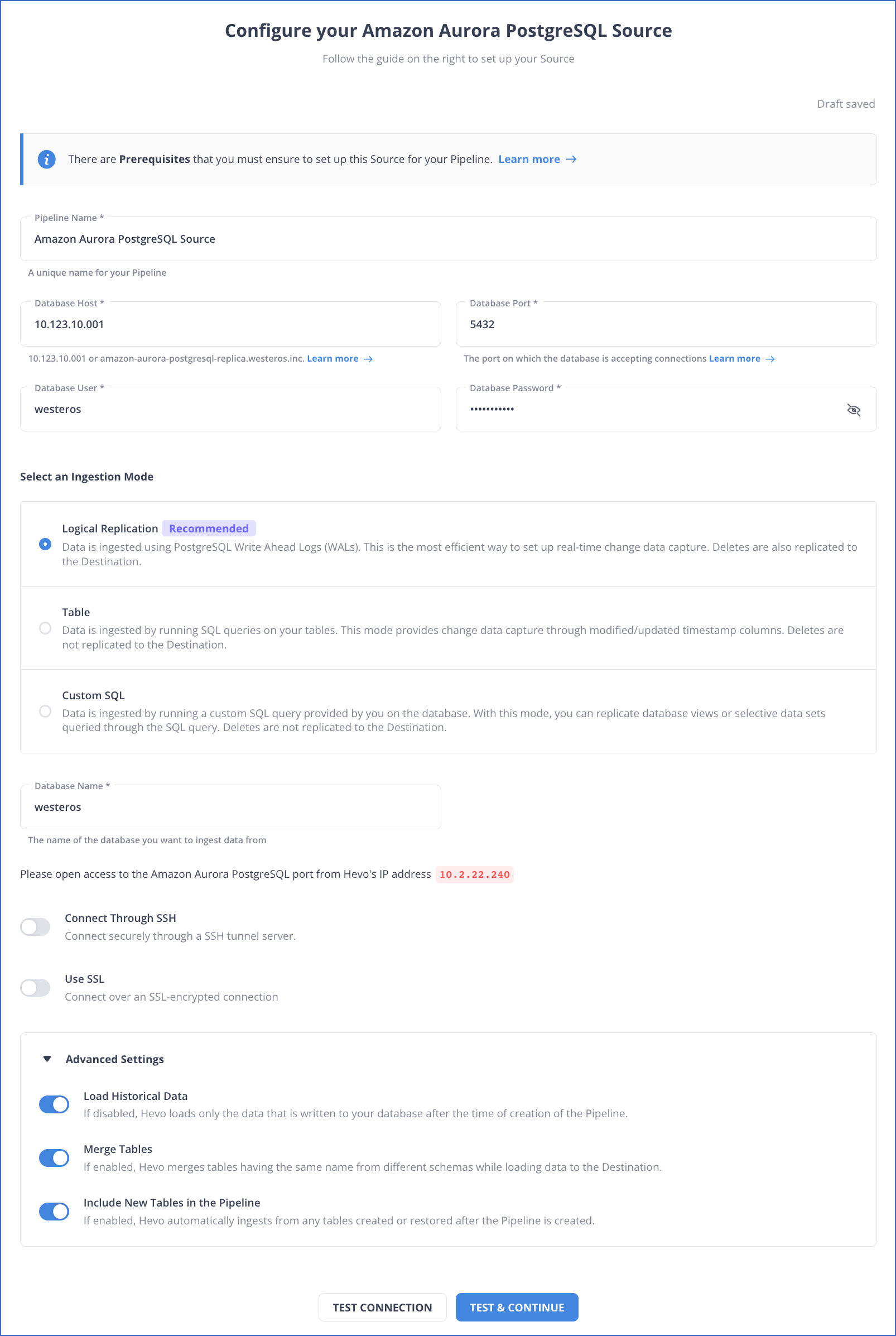
Step 1: Configuring AWS Aurora Postgres as Your Source Connector
Before configuring AWS Aurora Postgres, ensure the following prerequisites are in place:
- Postgres version 9.6 or higher
- IP address or DNS of PostgreSQL Server
- Whitelist Hevo’s IP address
- Set up Log-based incremental replication
- A database user account
- SELECT, USAGE, and CONNECT privileges for the database user.
- Pipeline Administrator, Team Collaborator, or Team Administrator role.
Step 2: Configuring Databricks as Your Destination Connector
Ensure the following prerequisites are in place before you get started:
- An active cloud service account on Azure, AWS, or Google Cloud Platform.
- Provide access to Databricks workspace in your cloud service account or create a new one.
- Enable IP access lists in your cloud service account.
- Databricks workspace’s URL should be in the form of https://<deployment name>.cloud.databricks.com.
- Except for the Billing Administrator role in Hevo, you must have a Team Collaborator or an administrator role.

Hence, the data will be replicated to your destination.
Method 2: Migrate AWS Aurora Postgres to Databricks Using Amazon S3 and Delta Tables
Step 1: Migrate Data from AWS Aurora Postgres Table to Amazon S3 Bucket
Before you get started, ensure that you meet the following prerequisites:
- Amazon Aurora Postgres Version 10.14 or above.
- Configure Amazon S3.
- S3 Bucket.
- Install the aws_s3 extension.
Follow the below steps to load data from Aurora PostgreSQL to the S3 bucket:
- Open your AWS Management Console. Navigate to the Amazon S3 Console.
- Find a file path in Amazon S3 for importing the data.
- Perform the following steps to provide privilege for Aurora Postgres to access the Amazon S3 bucket:
- Create an IAM policy and IAM role.
- Attach the IAM policy to the IAM role.
- Assign this IAM role to your Aurora Postgres DB cluster.
- Create an Amazon S3 URI using the following command:
psql=> SELECT aws_commons.create_s3_uri('your-bucket-name', 'S3-filepath', 'us-west-2') AS s3_uri_1 \gset- Export the data from the Aurora Postgres table to the Amazon S3 bucket specified by the S3 URi “s3_uri_1” using the following command:
psql=> SELECT * FROM aws_s3.query_export_to_s3('SELECT * FROM sample_table', :'s3_uri_1', options :='format text');Let’s understand the syntax of the above query:
- aws_s3.query_export_to_S3: An AWS function to export the query data to the S3 bucket.
- sample_table: It is the name of the Aurora Postgres table.
- S3_uri_1: A URI structure that finds the Amazon S3 file.
- options: =’format text’: It is an optional argument that contains a PostgreSQL COPY command to export the data to CSV, JSON, PARQUET, or any other file format.
- Modify the export command as follows:
SELECT * from aws_s3.query_export_to_s3('select * from sample_table', :'s3_uri_1', options :='format parquet, delimiter $$:$$');After performing these steps, the data in AWS Aurora Postgres tables is replicated to the Amazon S3 bucket in Parquet format.
Step 2: Replicate the Parquet Files from S3 Bucket to Databricks using Delta Tables
Before you begin, ensure the following prerequisites are in place:
- A Databricks account
- Launch the Databricks workspace or set up one using the AWS CloudFormation template.
- Configure a Workspace cluster or Compute.
Perform the following to replicate the data from the Amazon S3 bucket to Databricks:
- Go to your Databricks Workspace cluster and click the (+) icon in the left navigation pane to create a new workspace notebook.
- Specify the notebook name and select Python as the default language.
- Mount the Parquet files in the S3 Bucket to your Databricks Workspace using the following command:
dbutils.fs.mount(“s3a://%s”<s3-bucket-name>,”/mnt/%s”<mount-name>- Create a Delta Table using the following Pyspark API:
ReadFormat = 'parquet'
WriteFormat = 'delta'
LoadPath = '/mnt/dms-s3-bucket2022/dms-migrated-data/public/customer/LOAD00000001.parquet'
TableName = 'public.customer'
dataframe1=spark.read.format(ReadFormat).load(LoadPath)
dataframe1.write.format(WriteFormat).mode("overwrite").saveAsTable(TableName)Following these steps, your data will successfully load into Databricks Delta Tables from AWS Postgres.
Limitations of AWS Aurora Postgres To Databricks Integration with Amazon S3 and Delta Tables
- Slow Data Synchronization: If Postgres tables are modified, you must manually sync these changes to Amazon S3 and then update the Delta Table in Databricks. So, using Amazon S3 and Delta tables for the Aurora Postgres to BigQuery integration creates additional complexity in data synchronization.
- Technical Expertise: The lack of knowledge of Amazon S3 Buckets and Pyspark API for creating Delta Tables prevents you from successfully completing the AWS Aurora Postgres to Databricks integration.

Use Cases of AWS Aurora Postgres to Databricks Integration
- Efficient Data Analytics: With the AWS Aurora Postgres to Databricks integration, your organization can uncover valuable insights by analyzing data in the Delta Table using simple SQL queries.
- Data Visualization: With the AWS Aurora Postgres to Databricks replication, data analysts can quickly develop interactive dashboards and reporting tools that help in data-driven decision-making.
You can also read more about:
- GCP Postgres to Databricks
- Azure Postgres to Databricks
- Amazon S3 to Databricks
- PostgreSQL to Databricks
Conclusion
With the AWS Aurora Postgres to Databricks integration, you can quickly process and analyze large amounts of your organization’s operational data. It allows you to develop generative AI applications that provide a competitive edge.
The Aurora Postgres to Databricks integration using Amazon S3 and Delta Tables requires more time and cost. With Hevo’s pre-built connectors, you can cost-effectively integrate AWS Aurora Postgres with Databricks. Additionally, using Hevo can reduce the percentage of data loss. Try a 14-day free trial to explore all features, and check out our unbeatable pricing for the best plan for your needs.
Frequently Asked Questions (FAQ)
1. I have tried setting up AWS DMS to export data of size 10.5TiB from AWS Aurora Postgres to Databricks, but that was expensive and slow in real-time analytics. What product/platform is relatively low-cost and low-ops for this integration?
You can utilize any of the following methods for this integration:
You can utilize CDC to get real-time data by changing its minimum and maximum file sizes and automatically partitioning the data daily in S3.
You can opt for Hevo Data, which has 150+ readily available connectors to integrate efficiently.
2. Can we connect to SQL Server from Databricks?
You can connect to SQL Server directly from Databricks using JDBC. Just by configuring a JDBC connection string with proper SQL Server details, you would be able to read from and write to the SQL Server databases directly from within your notebooks in Databricks for the purpose of real-time data integration and analysis.
3. Is Databricks owned by AWS?
No, Databricks is not owned by AWS but is an entirely independent company founded by the creators of Apache Spark. However, Databricks can run its operations on any of the major cloud platform offerings, namely AWS, Microsoft Azure, and Google Cloud, where customers can employ its services in those environments.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



