

Most organizations find it challenging to manage data from diverse sources efficiently. Amazon Web Services (AWS) enables you to address this challenge with Amazon RDS, a scalable relational database service for Microsoft SQL Server (MS SQL).
However, simply storing the data isn’t enough. To drive your business growth, you need to analyze this data to gain insight into your business performance. Here’s where Databricks comes in with its advanced analytics capabilities that enable you derive meaningful insights for your business.
Migrating data from AWS RDS MSSQL to Databricks is a valuable data management strategy. Integrating data between these platforms allows you to swiftly make informed decisions about your business.
In this article, you will learn how to convert AWS RDS MS SQL to Databricks using different methods. Let’s get started!
Table of Contents
Why Integrate Data from AWS Rds MS SQL into Databricks?
Integrating data from AWS RDS MS SQL to Databricks provides many technical advantages. Datarbicks encompasses a wide range of tools and programming languages such as SQL, Python, Scala, and R. This allows you to streamline your data processing workflows and conduct complex analysis on a single platform. It continuously monitors your workload on the clusters and adjusts the worker nodes and their configurations according to your needs.
Databricks seamlessly integrates with several cloud storage services and databases, such as AWS S3, AWS RDS, Azure SQL database, Apache Kafka, and more. This allows you to analyze your data from multiple sources. It also provides a natural language interface for different types of users, helping them to increase their productivity. Additionally, Databricks is backed by technological advancement in generated AI, leveraging machine learning algorithms and automation capabilities to drive innovation.
Unlock the full potential of your financial data by using Hevo for integration. Within minutes, you can seamlessly connect MSSQL on RDS to your chosen destination, automating your data workflows and gaining real-time insights.
Why Integrate QuickBooks with Hevo?
- Automated Data Sync: Automatically transfer data from MSSQL to your preferred destinations without manual intervention.
- Real-Time Data Flow: Keep your data up-to-date and consistent across all platforms.
- No-Code Platform: With Hevo’s intuitive interface, you can easily set up and manage your data pipeline with no technical skills required.
Join 2000+ Happy Customers
Industry leaders such as Thoughtspot trust Hevo for its reliable data integration solutions.
Overview of AWS RDS MS SQL
AWS RDS MSSQL Server is a relational database web service provided by Amazon. It allows you to set up, operate, manage, and scale your SQL Server deployments within the AWS cloud. AWS RDS supports various versions of MSSQL, including 2016, 2017, 2019, and 2022. It is a fully managed database service that allows you to focus on administrative tasks such as provisioning, backup, and monitoring. AWS RDS for MSSQL Server supports the “License included” licensing model, eliminating your need to purchase a separate MSSQL Server license. Overall, AWS RDS for MSSQL simplifies data management tasks and enhances scalability.
Overview of Databricks
Databricks is a robust cloud platform that allows you to build, scale, and govern your enterprise data. It is built over a lakehouse foundation based on the open-source Apache Spark framework, which combines the potentiality of a data warehouse and a data lake. Datarbicks is powered by a Data Intelligence Engine that can understand the unique schema of your data. It helps you manage structured and unstructured data for AI workloads and business analytics. Databricks also provides end-to-end MLOps and AI development solutions built over a unified approach for governance and security.
Let’s see how you can sync AWS RDS MS SQL to Databricks using different methods.
Methods to Migrate Data from AWS RDS MS SQL to Databricks
Look at two methods where you can learn how to insert AWS RDS MS SQL data to Databricks table or file.
Method 1: Migrating Data from AWS RDS MS SQL to Databricks Using Hevo
Hevo is a real-time ELT platform that allows you to integrate your data smoothly with its Flexible, automated, cost-effective data pipelines. It provides 150+ data sources from which you can ingest the data into your desired destination. Hevo’s no-code data pipeline can be set up quickly with minimal effort to connect and load data from AWS RDS MS SQL to Databricks, making it analytics-ready.
Benefits of Using Hevo
- Data Transformation: Hevo has built-in data transformation tools, such as drag-and-drop and Python-based transformation. You can clean your source data before ingesting it to your destination.
- Incremental Loading: Incremental loading enables you to load recently updated or modified data from a source to a destination without loading the entire data set.
- Automated Schema Mapping: Hevo has automated schema mapping, which automatically reads your source schema and replicates it into your destination.
Step 1: Configure Amazon RDS SQL Server as Your Source
Prerequisites
- The MS SQL Server version should be 2008 or higher.
- If the Pipeline Mode is set to Change Tracking or Table, and the Query mode is set to Change Tracking, then:
- Enable Change Tracking.
- Grant the following privileges to the database user: Change Tracking, Alter Database, Select and View Change Tracking.
- Whitelist Hevo’s IP Addresses.
- To create a data pipeline in Hevo, you must be a Team Administrator, Team Collaborator, or Pipeline Administrator.
Follow the steps to configure your source:
- Click on PIPELINES in the Navigation Bar.
- Click on +CREATE.
- On the page, select Source Type and choose Amazon RDS MS SQL Server as your source.
- In the Configure Amazon RDS MS SQL Server connection settings page, provide the mandatory details:
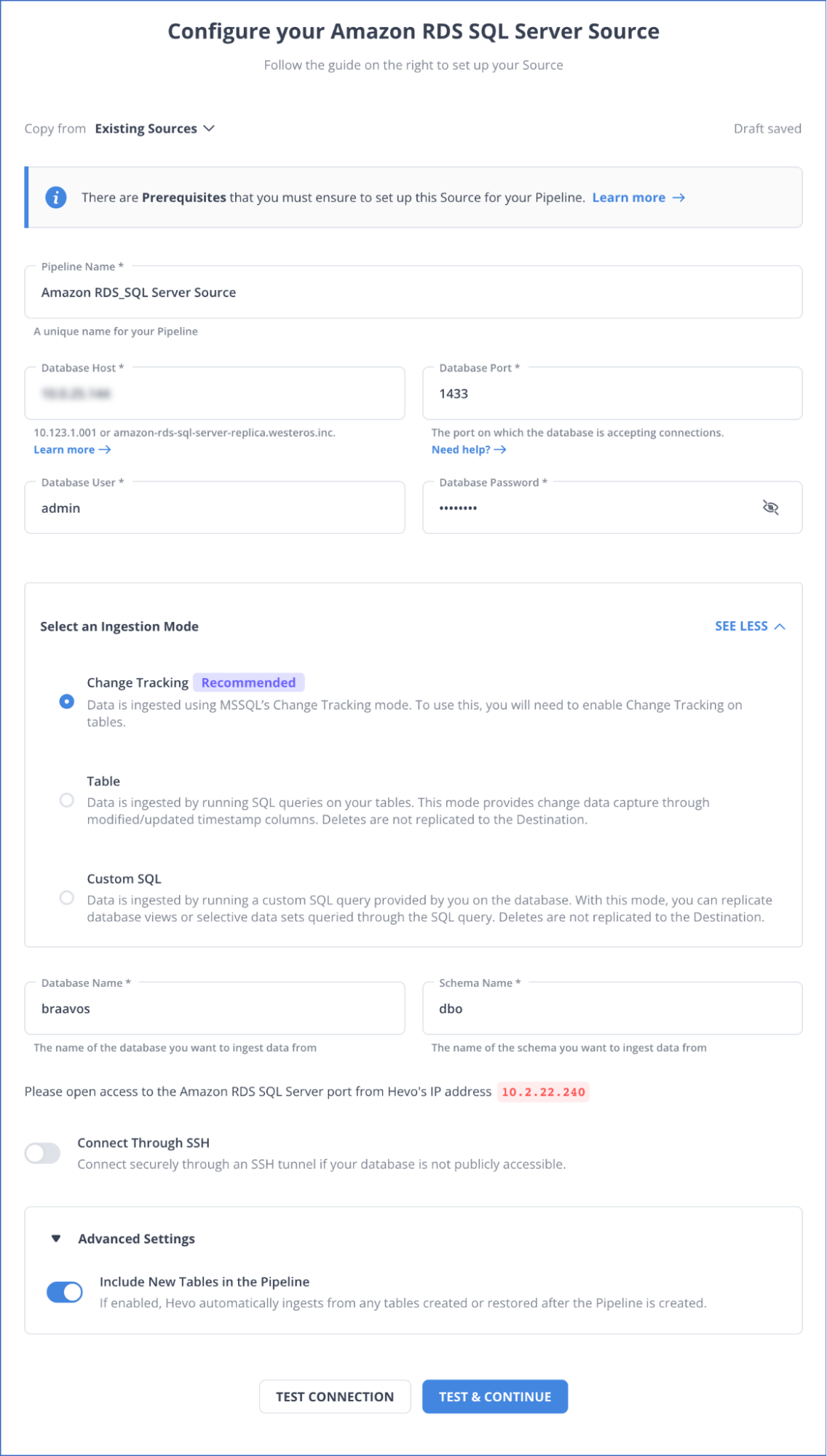
You can refer to the Hevo documentation to know more about configuring AWS RDS MS SQL as your source.
Step 2: Set up Databricks as Your Destination
Prerequisites
- An active AWS, GCP, or Azure account should be available.
- Create a Databricks workspace on your cloud service account.
- Enable the IP access list feature to connect your Databricks workspace.
- The URL of the Databricks workspace must be available in the format – https://<deployment name>.cloud.databricks.com.
- To connect to your Databricks workspace, you must meet the following requirements:
- Create an SQL warehouse or Databricks cluster.
- The port number, HTTP Path, and database hostname must be available.
- The Personal Access Token must be available.
- You must be assigned the role of any administrator, except for the Billing Administrator, to create the destination in the Hevo data pipeline.
You can also connect Databricks as your destination using a recommended method: Databricks Partner Connector.
Follow the steps to configure your destination:
- Select DESTINATIONS from the Navigation Bar.
- Click on +CREATE in the Destination View Lists.
- Select Databricks as your destination on the Add Destination Page.
- On the Configure Databricks as your Destination page, specify the following details:
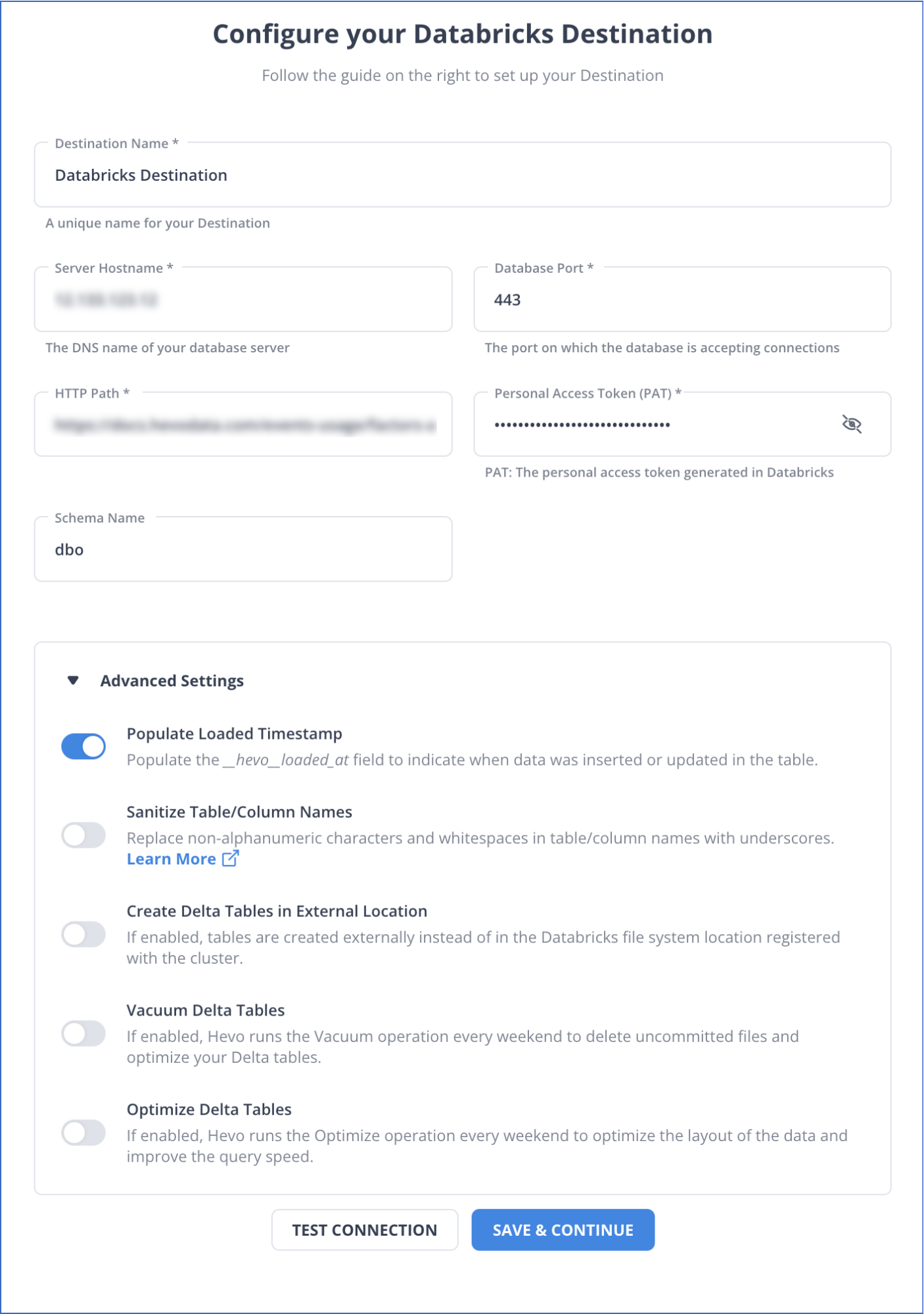
For more information, refer to the Hevo documentation on configuring Databricks as the destination.

Method 2: Export Data from AWS RDS MS SQL to Databricks File Using a S3 Bucket
You can export data from AWS RDS MS SQL to Databricks file by first moving it into an AWS S3 Bucket and then into Databricks.
Step 1: Enabling Integration between AWS RDS for SQL Server and Amazon S3 Bucket
Prerequisites
- Find or create an S3 Bucket that you want to use for the integration.
- Add permissions to access the S3 Bucket for integration.
- To configure access, create an IAM policy and IAM role.
Follow the steps below to enable AWS RDS SQL and S3 Bucket integration.
- Associate your DB instance to the IAM role
- Sign in to the AWS Management Console and open the AWS RDS console.
- Choose RDS for SQL DB instance.
- Go to the Connectivity & security tab, Manage IAM>Add IAM role for this SQL instance.
- For Feature, you must select S3_INTERGRATION and click on Add role.
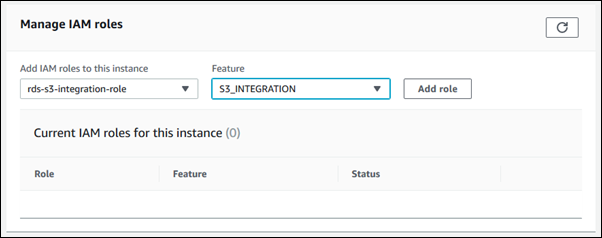
- Upload files from SQL DB instance to S3 Bucket.
The Amazon RDS stored procedure is used to upload files from RDS for SQL to the S3 Bucket.
The files that you download or upload to an S3 Bucket are stored inside a folder D:\S3, the only folder you can use to access files. Also, some stored procedures require you to provide an Amazon Resource Name (ARN), arn :aws:s3:::bucket_name/file_name.
The following example will tell how you can upload a file named ‘data.csv’ from a location in D:\S3\seed_data\ to a new_data.csv file in the S3 Bucket, which is specified by ARN.
exec msdb.dbo.rds_upload_to_s3
@rds_file_path='D:\S3\seed_data\data.csv',
@s3_arn_of_file='arn:aws:s3:::bucket_name/new_data.csv',
@overwrite_file=1;Step 2: Loading Data into from S3 Bucket to a Table in Databricks SQL Warehouse
You can use the COPY_INTO command to migrate the data from AWS S3 Bucket into your AWS account in a table in Databricks SQL.
Prerequisites
- To access data in S3, configure data access for ingestion and read your source files.
- Enable Can manage permission for your Databricks warehouse.
- The S3 URI must be fully qualified.
- Familiarize yourself with the Databricks SQL user interface.
Follow the steps below to convert AWS RDS MS SQL to Databricks table:
- Confirm your access to data in the cloud storage
- In a Databricks sidebar, click on Create > Query.
- In the SQL editor menu, select an SQL warehouse and paste the following code:
select * from csv.<path> , where you need to replace ‘path’ with the S3 URI.
For example - select*from csv.<s3://<bucket>/<folder>/>- Click on Run.
- Create a table in the Databricks workspace
In the SQL editor pane, paste and run the following code:
CREATE TABLE <catalog_name>.<schema_name>.<table_name> (
tpep_pickup_datetime TIMESTAMP,
tpep_dropoff_datetime TIMESTAMP,
trip_distance DOUBLE,
fare_amount DOUBLE,
pickup_zip INT,
dropoff_zip INT
);- Load data from S3 to the Databricks table you created
- Go to the sidebar and select Click>Query.
- In the SQL editor menu, select the SQL warehouse that is running.
- Paste the following code in the SQL editor and replace:
- <s3-bucket> with the name of your Amazon S3 Bucket.
- <folder> with the name of your folder.
COPY INTO <catalog-name>.<schema-name>.<table-name>
FROM 's3://<s3-bucket>/<folder>/'
FILEFORMAT = CSV
FORMAT_OPTIONS (
'header' = 'true',
'inferSchema' = 'true'
)
COPY_OPTIONS (
'mergeSchema' = 'true'
);
SELECT * FROM <catalog_name>.<schema_name>.<table_name>;- Run the query to load the data from the S3 Bucket folder to your Databricks table.
Limitation for Exporting Data from AWS RDS MS SQL to Databricks File Using a S3 Bucket
- You can’t run more than one task for S3 integration. If you do, they are executed sequentially instead of parallelly.
- You need to perform extra tasks, such as cleaning up and deleting data from the temporary storage, which is quite time-consuming.
Use Cases for AWS RDS MS SQL to Databricks
- Databricks can be used to perform advanced analytics on data stored in AWS RDS MS SQL, analyze historical sales data or operational metrics, and derive insights.
- You can perform real-time data processing by exporting data from AWS RDS MS SQL to a Databricks file. Additionally, create dashboards and alerts that visually display your data trends, such as sales for each product.
Read More About:
- Connect Microsoft SQL Server to S3
- SQL Server to SQL Server
- Integrate Slack SQL Server
- Setting up Airflow SQL server
Conclusion
Integrating AWS RDS MS SQL to Databricks enables organizations to transform the raw data into actionable insights to drive business growth. While data integration between these two platforms using an S3 Bucket can be lengthy, Hevo makes it easy through its automated data pipeline. Overall, exporting data from RDS for SQL Server instance to Databricks is a strategic investment that can enable your business growth.
Learn how to migrate data from AWS RDS MSSQL to Snowflake to enhance your data integration. Our guide offers clear steps for a seamless transition.
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, check out our unbeatable pricing to choose the best plan for your organization.
Share your experience of AWS RDS MSSQL to Databricks integration in the comments section below!
FAQs (Frequently Asked Questions)
Can we export data from the AWS RDS instance to Databricks without using the JDBC/ODBC driver?
You can export data from an AWS RDS instance to Databricks without the use of a JDBC/ODBC driver. One method is using an Amazon S3 Bucket, which allows you to keep your upload files from an AWS RDS instance in an S3 Bucket. Then, those files can be transferred to the Database workspace either using a COPY_INTO command or Unity catalog or using the add data UI method. You can also use a third-party data integration platform such as Hevo. It lets you load your source data directly from the AWS RDS MS SQL to the Databricks destination.
How do I connect RDS to Databricks?
To connect Amazon RDS to Databricks, use a JDBC driver. Configure the RDS database’s endpoint, username, password, and port in Databricks, then use Spark’s read.jdbc method to access data.
Can we connect SQL Server to Databricks?
Yes, Databricks can connect to SQL Server using JDBC. Install the SQL Server JDBC driver, specify the database details, and use spark.read.format("jdbc") to read or write data.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





