




Cloud solutions like AWS RDS for Oracle offer improved accessibility and robust security features. However, as data volumes grow, analyzing data on the AWS RDS Oracle database through multiple SQL queries can lead to inconsistency and performance degradation.
If your organization is considering migrating large datasets to a new platform, it’s essential to look into factors such as migration costs, scalability, and query data performance. This is where Amazon Redshift comes in.
Migrating AWS RDS Oracle to Redshift offers a cost-effective solution to accommodate large data volumes without compromising performance. It allows multiple data analysts to execute queries simultaneously. This parallel query execution in Redshift results in faster query responses.
Let’s look into the details of migrating from AWS RDS Oracle to Redshift.
Table of Contents
AWS RDS for Oracle: A Brief Overview
AWS RDS Oracle is a variant of Amazon RDS that allows you to deploy multiple Oracle database editions on the AWS cloud, often using the lift-and-shift method.
AWS RDS for Oracle enhances the replication process for improved availability and reliability of production workloads. This fully managed database service enables you to efficiently manage hardware and software provisioning, backups, and updates.
With AWS RDS for Oracle, you can choose the License Included or Bring-Your-Own-License (BYOL) options. You can also purchase Reserved DB Instances with a small upfront payment for a one or three-year reservation period to optimize costs.


Amazon Redshift: A Brief Overview
Amazon Redshift is a fully managed, AI-powered, cloud data warehouse service in the AWS ecosystem, known for its impressive performance and scalability. This simple platform uses SQL to efficiently analyze structured and semi-structured data from data lakes, data warehouses, and operational databases cost-effectively.
With the Massively Parallel Processing (MPP) architecture, Redshift can upgrade its data analytics operations by distributing and parallelizing queries across multiple nodes. This helps provide valuable insights for your organization. You can process large datasets within minutes, query them in near real-time, and develop low-latency analytics applications, such as for IoT environments.
Additionally, Amazon Redshift integrates with Business Intelligence tools to generate dynamic, insight-driven dashboards and reports.
Methods to Transfer AWS RDS Oracle Data to Redshift
To transfer data from AWS RDS Oracle to Redshift, you can either utilize Hevo Data or perform the migration manually through Amazon S3.
- Method 1: Using Hevo Data
Leverage Hevo’s no-code platform to easily migrate your RDS Oracle data to Redshift with automated, real-time data pipelines and pre-built transformations.
Get Started with Hevo for Free - Method 2: Import RDS Oracle to Redshift via S3
Manually export your RDS Oracle data to an Amazon S3 bucket and load it into Redshift using Amazon’s native tools.
Method 1: Using Hevo Data to Migrate AWS RDS Oracle to Redshift
Hevo Data is a no-code, real-time ELT platform that automates data pipelines based on your preferences at a low cost. It seamlessly integrates with over 150 data sources, including 40+ free sources. Hevo Data not only helps you export and load the data, but you can also transform and prepare it for in-depth analysis.
Let’s see how to integrate AWS RDS Oracle to Redshift using Hevo Data.
Step 1: Set up AWS RDS Oracle as Your Source Connector
Before starting the configuration, ensure the following prerequisites are met:
- Oracle Database Version 12c or higher.
- Enable Redo Log Replication for Redo Log Pipeline mode.
- Whitelist Hevo’s IP addresses.
- Create a Database User and Grant SELECT privileges to the database user.
- Obtain the source instance’s Database Hostname, Service ID, and Port Number.
- You must have a Pipeline Administrator, Team Administrator, or Team Collaborator role in Hevo.
Let’s convert AWS RDS Oracle to Redshift using the following steps:
- Log in to your Hevo account.
- In the Navigation Bar, select the PIPELINES option.
- Click the + CREATE button from the Pipelines List View page.
- Search and select Amazon RDS Oracle as the source type from the Select Source Type page.
- In the Configure your Amazon RDS Oracle Source page, specify the required information for configuration.
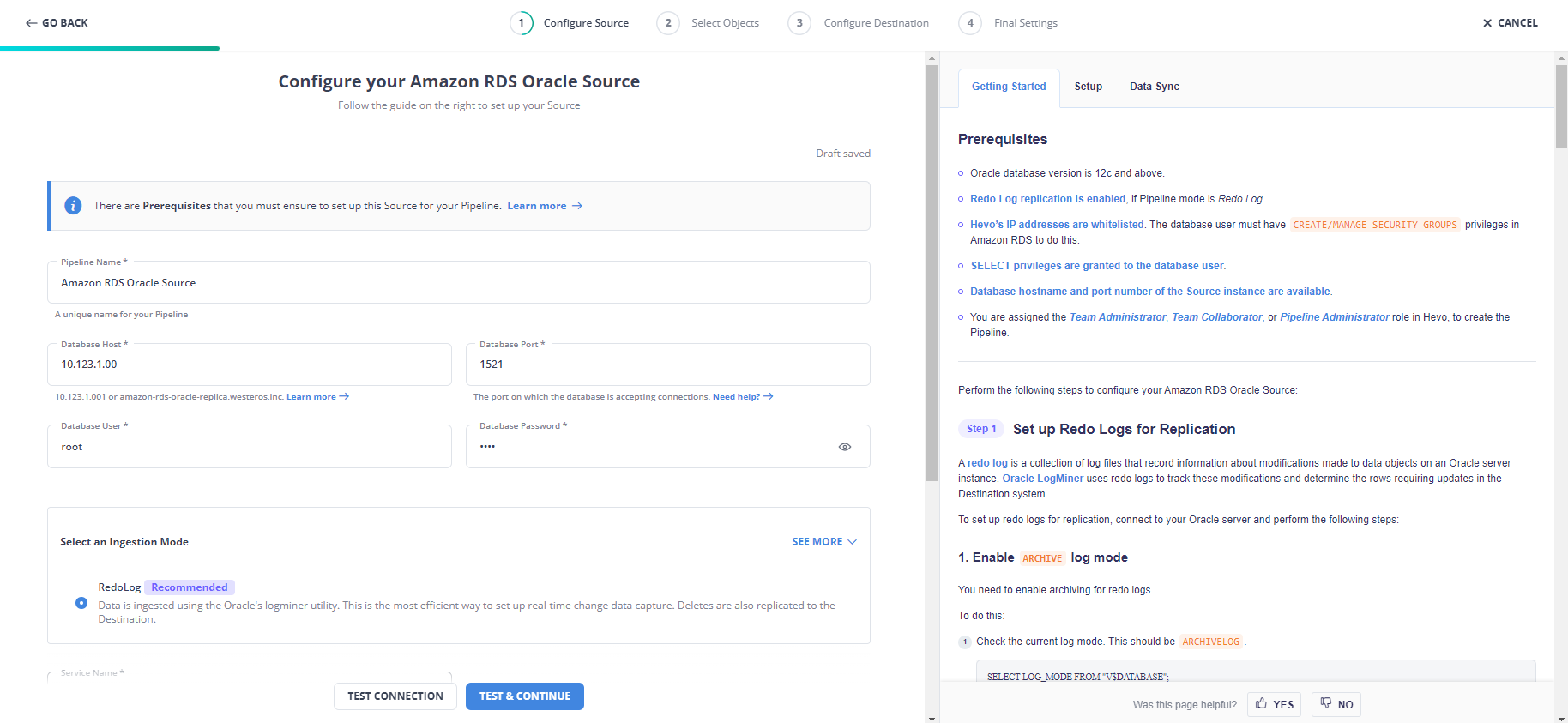
- Click TEST CONNECTION > TEST & CONTINUE.
For more information about the source configuration, read the Hevo documentation for Amazon RDS Oracle.
Step 2: Set up Amazon Redshift as Your Destination Connector
Before you begin the setup, ensure of the following prerequisites:
- A running Amazon Redshift Instance.
- An Amazon Redshift database.
- Retrieve the Database hostname and port number of the Amazon Redshift instance.
- Whitelist Hevo’s IP addresses.
- Provide SELECT permissions to the database user.
- You must be assigned a Team Collaborator or any administrator role in Hevo, excluding the Billing Administrator role.
Here are the steps to configure the Amazon Redshift connector as a destination:
- In the Navigation Bar, choose the DESTINATIONS option.
- From the Destinations List View, click the + CREATE button.
- Select Amazon Redshift on the Add Destination page.
- Specify the neccessary information in the Configure your Amazon Redshift Destination page.

- Click TEST CONNECTION > SAVE & CONTINUE to finish the destination configuration.
For more information about destination configuration, read the Hevo documentation for Amazon Redshift.
Here are the key features of Hevo Data:
- Data Transformation: To make analytics tasks smoother, analyst-friendly data transformation features are integrated into Hevo Data. Utilize powerful Python based transformation scripts or Drag-and-drop transformations to cleanse and prepare the data before loading it to your destination.
- Incremental Data Load: Hevo allows you to transfer updated data instantly, optimizing bandwidth usage for improved efficiency.
- Auto Schema Mapping: Hevo simplifies schema management by automatically identifying and copying the incoming data format to the destination schema. You can choose Full or Incremental mappings based on your data replication needs.
Visit our Website to Explore Hevo
Method 2: Import AWS RDS Oracle to Redshift Using Amazon S3 Bucket
To load AWS RDS Oracle to Redshift with this method, you must manually export data from the Oracle database on AWS RDS to a dump file using Oracle’s DBMS_DATAPUMP. Then, the dump files will be loaded into the Amazon S3 bucket in GZIP-compressed format by invoking the Amazon RDS procedure. Finally, the compressed data files are imported into Amazon Redshift using its COPY command.
Check out the Top 10 Oracle ETL tools to simplify this integration.
Ensure the following prerequisites are in place before you start migration:
- An Amazon S3 bucket in the same AWS region as the DB instance.
- Configure IAM permissions for AWS RDS Oracle.
- Configure an option group for Amazon S3 integration.
- Grant permissions to the database user on the AWS RDS for the Oracle database.
Perform the following steps to import from AWS RDS Oracle to Redshift via Amazon S3:
Step 1: Export Data into a Dump File Using DBMS_DATAPUMP
- Connect to the AWS RDS for Oracle DB instance with the Amazon RDS master user using Oracle SQL developer. To perform this, read the steps in connecting to your DB instance.
- Invoke the DBMS_DATAPUMP procedures to export the data or schema into a dump file named demo.dmp in the DATA_PUMP_DIR directory using the following script:
DECLARE
v_file NUMBER;
BEGIN
v_file := DBMS_DATAPUMP.OPEN(
operation => 'EXPORT',
job_mode => 'SCHEMA',
job_name => null
);
DBMS_DATAPUMP.ADD_FILE(
handle => v_file ,
filename => 'demo.dmp' ,
directory => 'DATA_PUMP_DIR',
filetype => dbms_datapump.ku$_file_type_dump_file
);
DBMS_DATAPUMP.ADD_FILE(
handle => v_file,
filename => 'demo_exp.log',
directory => 'DATA_PUMP_DIR' ,
filetype => dbms_datapump.ku$_file_type_log_file
);
DBMS_DATAPUMP.METADATA_FILTER(v_file,'SCHEMA_EXPR','IN (''SCHEMA1'')');
DBMS_DATAPUMP.METADATA_FILTER(
v_file,
'EXCLUDE_NAME_EXPR',
q'[IN (SELECT NAME FROM SYS.OBJ$
WHERE TYPE# IN (66,67,74,79,59,62,46)
AND OWNER# IN
(SELECT USER# FROM SYS.USER$
WHERE NAME IN ('RDSADMIN','SYS','SYSTEM','RDS_DATAGUARD','RDSSEC')
)
)
]',
'PROCOBJ'
);
DBMS_DATAPUMP.START_JOB(v_file);
END;
/Step 2: Import the Dump File to Your Amazon S3 Bucket
Load the dump file named demo.dmp from the DATA_PUMP_DIR directory to the Amazon S3 bucket by invoking the Amazon RDS procedure using the following script:
SELECT rdsadmin.rdsadmin_s3_tasks.upload_to_s3(
p_bucket_name => 'My_S3_bucket',
p_prefix => '',
p_s3_prefix => 'databasefiles',
p_directory_name => 'DATA_PUMP_DIR/demo.dmp',
p_compression_level => 9)
AS TASK_ID FROM DUAL;This script uploads all the files in the DATA_PUMP_DIR directory to the databasefiles folder in the My_S3_bucket by applying the highest GZIP compression level. For more information, refer to this documentation.
Step 3: Load Compressed Data Files from Amazon S3 Bucket into Amazon Redshift
Using the following COPY command, you can load the files that are compressed using GZIP:
COPY redshift_table_name
FROM 's3://My_S3_bucket/databasefiles/demo.gzip'
IAM_ROLE 'arn:aws:iam::<your_aws_account_id>:role/<your_redshift_rolename>'
FORMAT AS CSV
DELIMITER '|'
GZIP;Using the above steps, you can manually import data from the AWS RDS Oracle database to Amazon Redshift, using Amazon S3 for intermediate storage and data transfer.
Limitations of AWS RDS Oracle to Redshift Migration Using Amazon S3
- Storage Limits: Amazon S3 buckets are limited to a maximum storage capacity of 5 TB. Transferring data from AWS RDS Oracle to Redshift via Amazon S3 would not be ideal when the data size exceeds this limit.
- RDS Transfer Package Constraints: The rdsadmin_s3_tasks package can only transfer data files within a single directory. It does not allow subdirectories to be included during the transfer process.
Use Cases of AWS RDS Oracle to Redshift Migration
- Real-time Analytics: Your organizations may have to rely on current and historical data to make smart decisions and swiftly implement business plans. With MPP technology, Amazon Redshift can facilitate real-time data analysis and accelerate the discovery of valuable insights from large AWS RDS Oracle datasets.
- Business Intelligence (BI): Different individuals must handle your organization’s operational data. For non-data experts, detailed reports or user-friendly dashboards help them to access the information easily. By utilizing Redshift, you can create highly functional dashboards and automate report generation.

Why Integrate AWS RDS Oracle to Redshift?
Here are a few benefits of migrating from AWS RDS Oracle to Redshift:
- Dynamic Data Masking: Redshift protects your organization’s confidential data by controlling its visibility. This includes defining different access levels for external or internal users linked to your organization and eliminating the necessity of duplicate data for each user.
- Advanced Query Editor: Redshift’s user-friendly Query Editor in the AWS Console is handy to create, run, and share SQL queries. It also supports basic annotations and visualizations for streamlining data analysis within your organization.
Learn More About:
- Amazon Redshift vs Oracle ADW
- Load data from Oracle to Iceberg
- Migrate MySQL to Oracle
- Migrate PostgreSQL to Oracle
- Migrate SQL Server to Oracle
Conclusion
This article highlights the importance of migrating data from AWS RDS Oracle to Redshift and explores two migration methods.
One way to directly migrate from AWS RDS Oracle to Redshift is by using readily available connectors offered by Hevo Data. Alternatively, you can use Amazon S3 as intermediary storage to hold data extracted from AWS RDS Oracle before loading it into Redshift.
When aiming to save time, effort, and cost, Hevo Data would be the optimal choice. It helps you effortlessly integrate with Redshift in minutes and at minimal expense, eliminating the need for manual intervention.
If you want to learn about Amazon Redshift Data Architecture, read this Hevo Documentation.
Frequently Asked Questions (FAQ):
I utilize Amazon SCT to migrate the Oracle Schema on AWS RDS to Amazon Redshift. However, due to size constraints, the migration is not successful. So, I upgraded my PC to a Business PC with 16 GB of memory, but it is still not working. How can I perform a smooth migration?
A. You can perform the following ways:
- Edit the SCT configuration files to increase the JVM size. After editing the files, restart the AWS SCT and try the migration again. Read this blog for more information.
- You can uninstall the current version of AWS SCT and reinstall the old version. Open the Project settings window and uncheck “Use AWS Glue”.
- You can utilize Hevo’s pre-built Amazon RDS for Oracle source and Amazon Redshift destination connectors.
Want to take Hevo for a spin? Sign up for a 14-day free trial and experience the feature-rich Hevo suite first hand. You can also have a look at the unbeatable Hevo pricing that will help you choose the right plan for your business needs.
Visit our Website to Explore Hevo
Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



