

Today, a combination of Debezium and Kafka is embraced by organizations to record changes in databases and provide information to subscribers (other applications).
In this article, you will learn about Kafka Debezium, features of Debezium, and how to perform event sourcing using Debezium and Kafka.
Table of Contents
Prerequisites
- Understanding of streaming data.
Transform your data pipeline with Hevo’s no-code platform, designed to seamlessly transfer data from Apache Kafka to over destinations such as BigQuery, Redshift, Snowflake, and many others. Hevo ensures real-time data flow without any data loss or coding required.
Why Choose Hevo for Kafka Integration?
- Simple Setup: Easily set up data pipelines from Kafka to your desired destination with minimal effort.
- Real-Time Syncing: Stream data continuously to keep your information up-to-date.
- Comprehensive Transformations: Modify and enrich data on the fly before it reaches your destination.
Let Hevo handle the integrations.
Get Started with Hevo for FreeWhat is Kafka?

Initially developed by LinkedIn, Kafka is a distributed event streaming platform that powers most data-driven applications. However, today Kafka is a part of the Apache Software Foundation and is one of Apache’s most popular open-source solutions. Written in Java and Scala, Kafka supports publish-subscribe messaging to support real-time streaming of data across several applications. Such extensive integration makes Kafka popular among developers to streamline data delivery not only for building data-driven applications but also to support real-time analytics.
What is Debezium?

Debezium is an open-source distributed platform that is built on top of Apache Kafka. The platform is popular among database developers as it converts your existing databases into event streams, allowing applications to view and respond to changes in the databases at row level.
It’s always been difficult to keep track of databases and be notified when the data changes. Some databases provide frameworks or APIs for monitoring changes, however as there is no standard, the method of each database is unique and necessitates a great deal of specialized expertise and code. Thanks to Debezium, monitoring databases is no longer a challenge for developers. The distributed open-source change data capture platform supports monitoring a variety of database systems with ease.
To simplify the event sourcing, Debezium is building up a library of connectors that capture changes from a variety of DBMS and produce events with almost similar structures. This, as a result, makes it faster for applications to consume as well as respond to the events regardless of where the changes originated.
Debezium provides Kafka Connect compatible connectors that monitor specific database management systems. The platform records the history of data changes in Kafka logs, from where applications consume them. Debezium captures row-level changes in your databases so that your real-time applications can see and respond to those changes.
At present, Debezium includes support for monitoring various popular databases like PostgreSQL servers, SQL Server databases, MySQL database servers, MongoDB replica sets or sharded clusters, and others.
Key Features of Debezium
- Low Delay: Debezium produces change events with a very low delay while avoiding increased CPU usage of frequent polling.
- Data Changes: Debezium makes sure that all the data changes are captured and requires no changes to your data model.
- Capture Deletes and Old Record State: Debezium can capture deletes as well as Old Record State and further metadata such as Transaction Id and causing query, depending on the capabilities and configuration of the database.
- Change Data Capture Feature: The change data capture feature of Debezium is amended with a range of related capabilities and options, such as filters, masking, monitoring, message transformations, and snapshots.
- Fault-tolerant: Debezium is architected to be tolerant of faults and failures. The platform distributes the monitoring processes across multiple machines so that, if anything goes wrong, the connectors can be restarted.
Uses of Debezium
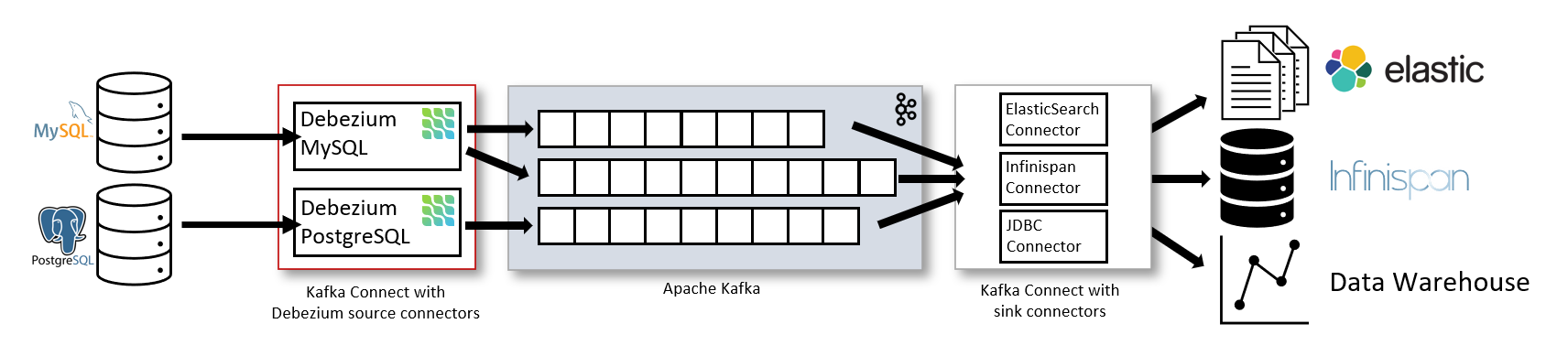
One of the primary uses of this platform is to enable applications to respond almost immediately whenever there is a change of data in databases. Debezium can be used for various other cases. Some of them are as follows:
- Cache Invalidation: Debezium automatically invalidates entries in a cache as soon as the records for entries change or are removed.
- Monolithic Applications: Mostly, applications update a database and carry out other associated work after the changes are committed. These include updating a cache, updating search indexes, and more. With the help of Debezium, these activities can be performed in separate threads or separate processes when the data is committed in the original database.
- Data Integration: Keeping numerous systems synced might be difficult, but with Debezium and simple event processing logic, you can build ETL solutions effectively.
- Sharing Databases: When more than one application shares a single database, it is frequently difficult for one application to become aware of changes made by another. However, with Debezium, each application can easily monitor the database and react to the changes.
What is Event Sourcing?
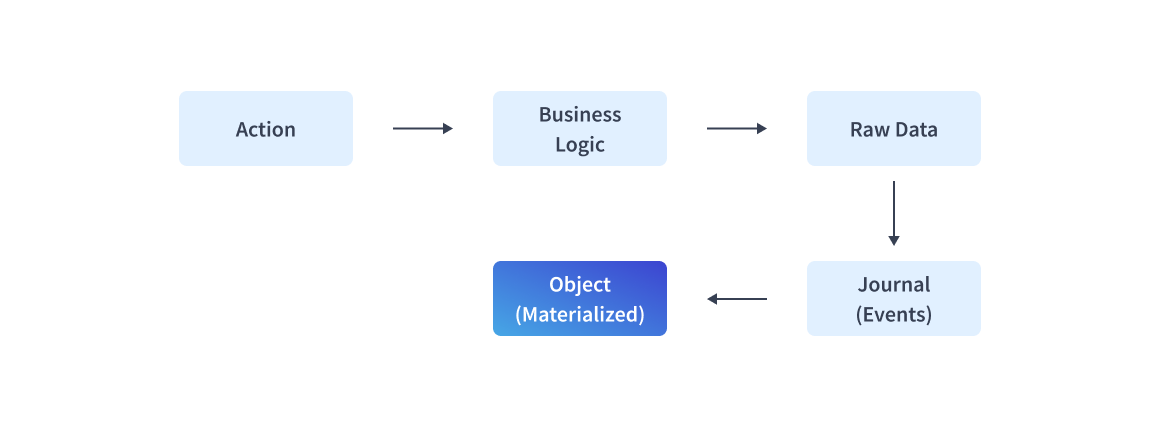
Event Sourcing is a method for software to keep track of its state as a log of domain events. The basic principle behind event sourcing is to ensure that every change in an application’s state is captured in an event object. Unlike CDC (Change Data Capture), which relies on the transaction log, event sourcing focus on journal events.
The implementations of Event Sourcing usually have the following characteristics:
- Domain events, which are generated by the application’s business logic, will introduce additional states for applications.
- The state of applications is recorded with journals, which are append-only event logs.
- Journal is what differentiates event sourcing from CDC. It is considered the source of truth for applications and is replayable to rebuild the state of the application.
- In general, Journal groups ‘domain events’ by an ID to capture the state of an object.
Why use Event Sourcing?
As organizations are building microservices and distributing data across multiple data stores, data can be lost, out of sync, or even corrupted in a matter of seconds, posing a serious threat to mission-critical systems.
Event Sourcing mitigates such issues by providing a representation of past and current application states as a series of events. Some of the other features that Event Sourcing provides include performance, simplification, integration with other subsystems, production troubleshooting, fixing errors, testing, flexibility, and more.
Kafka Debezium Event Sourcing Setup
Steps for Kafka Debezium Event Sourcing will be discussed in this section. To leverage Debezium for event sourcing, you need three separate services: ZooKeeper, Kafka, and the Debezium connector.
Note: Each service will be used with a different container.
1. Kafka Debezium Event Sourcing: Start Zookeeper
- Step 1: The below command runs a new container using version 1.8 of the debezium/zookeeper image:
- Step 2: On executing the above command, the zookeeper will start listening on port 2181.
$ docker run -it --rm --name zookeeper -p 2181:2181 -p 2888:2888 -p 3888:3888 debezium/zookeeper:1.82. Start Kafka
- Step 1: Now, open a new terminal and run the following command to start Kafka in a new container.
$ docker run -it --rm --name kafka -p 9092:9092 --link zookeeper: zookeeper debezium/kafka:1.83. Start a MySQL Database
- Step 1: After starting zookeeper and Kafka, we need a database server that can be used by Debezium to capture changes. Start a new terminal and run the following command for starting MySQL database server.
$ docker run -it --rm --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=debezium -e MYSQL_USER=mysqluser -e MYSQL_PASSWORD=mysqlpw debezium/example-mysql:1.84. Start a MySQL Command-Line Client
- Step 1: To access sample data, run the below command after starting the MySQL server. This runs a new container.
$ docker run -it --rm --name mysqlterm --link mysql
--rm mysql:8.0 sh -c 'exec mysql -h"$MYSQL_PORT_3306_TCP_ADDR"
-P"$MYSQL_PORT_3306_TCP_PORT" -uroot -p"$MYSQL_ENV_MYSQL_ROOT_PASSWORD" '- Step 2: Then, type the command – use inventory – to switch to the inventory database. From here, you can list the tables and access the data.
5. Start Kafka Connect
- Step 1: Start a new terminal and run the below command to start Kafka connect.
$ docker run -it --rm --name connect -p 8083:8083 -e GROUP_ID=1 -e CONFIG_STORAGE_TOPIC=my_connect_configs
-e OFFSET_STORAGE_TOPIC=my_connect_offsets
-e STATUS_STORAGE_TOPIC=my_connect_statuses
--link zookeeper: zookeeper --link kafka:kafka --link mysql:mysql debezium/connect:1.86. Kafka Debezium Event Sourcing: Deploying the MySQL Connector
- Step 1: After starting all the above services, you can now deploy the Debezium MySQL connector and start monitoring the inventory database.
- Step 2: For deploying the MySQL connector, you should register the MySQL connector to monitor the inventory database. You can do this using the curl command.
- Step 3: The below command uses the localhost to connect to the Docker host.
$ curl -i -X POST -H "Accept:application/json"
-H "Content-Type: application/json" localhost:8083/connectors/
-d '{ "name": "inventory-connector",
"config": {"connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "mysql", "database.port": "3306", "database.user": "debezium", "database.password": "dbz","database.server.id": "184054", "database.server.name": "dbserver1",
"database.whitelist": "inventory",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "dbhistory.inventory" } }'Note: You might need to escape the double-quotes.
- Step 4: Now, verify the connector using the below command.
$ curl -H "Accept: application/json" localhost:8083/connectors/ ["inventory-connector"]- Step 5: Review the connector tasks with the below command.
$ curl -i -X GET -H "Accept:application/json" localhost:8083/connectors/inventory-connector7. Kafka Debezium Event Sourcing: View Change Events
- Step 1: On deploying the Debezium MySQL connector, you can start monitoring the inventory database for data change events. All the events are written to the topics with the dbserver-1 prefix.

Conclusion
In this article, you have learned about Debezium, Event Sourcing, and the steps to perform event sourcing with Debezium and Kafka. Debezium is a distributed platform that turns your existing databases into event streams.
This helps your applications see as well as respond immediately to each row-level change in the databases. In the above tutorial, we have used the MySQL connector. You can further try running the tutorial with Debezium connectors for MongoDB, Postgres, and Oracle.
Extracting complex data from a diverse set of data sources to carry out an insightful analysis can be challenging, and this is where Hevo saves the day! Hevo offers a faster way to move data from 150+ Data Sources including Databases or SaaS applications like Kafka into your Data Warehouse to be visualized in a BI tool. Hevo is fully automated and hence does not require you to code.
Want to take Hevo for a spin? Sign Up or a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also checkout our unbeatable pricing to choose the best plan for your organization.
FAQs
1. What is Debezium in Kafka?
Debezium is an open-source platform for change data capture (CDC) that tracks and streams changes from databases into Kafka topics. It allows Kafka to capture and propagate database changes in real time, making it easier to replicate and synchronize data.
2. What is the difference between Debezium and Confluent Kafka Connect?
Debezium is a specialized CDC tool built on top of Kafka Connect, focused on capturing database changes. Confluent Kafka Connect is a broader integration framework that connects Kafka to various external systems, including databases, message queues, and file systems, allowing both source and sink connectors. Debezium uses Kafka Connect as a platform but is purpose-built for CDC.
3. What is the difference between Debezium and Zookeeper?
Debezium is a tool for CDC that streams database changes into Kafka, while Zookeeper is a distributed coordination service used to manage and configure Kafka brokers. Zookeeper handles tasks like leader election and cluster coordination, whereas Debezium deals with tracking and streaming database changes. They serve entirely different roles within the Kafka ecosystem.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





