

Kafka Event Streaming is becoming essential as data grows across industries. But what exactly is Event Streaming? It enables businesses to:
- Track events like customer orders or bank deposits in real-time.
- Respond instantly to these events, making timely decisions.
Apache Kafka is the most popular software for Event Streaming because it:
- Manages large data flows seamlessly.
- Uses a queuing system to ensure accurate data delivery.
In this article, you’ll learn how Kafka works, its key features, and how top companies leverage it for real-time data.
Table of Contents
What is Apache Kafka?

- Apache Kafka is a distributed Event Processing or Streaming platform that allows applications to process large amounts of data quickly. It is capable of handling billions of events every day. It’s a scalable Streaming platform with excellent fault tolerance.
- The Apache Kafka framework, written in Java and Scala, is a distributed Publish-Subscribe Messaging system that receives Data Streams from various sources. Kafka is used to analyze real-time streams of Big Data.
- Apache Kafka’s capacity to handle peak data input loads is a distinct and powerful advantage over traditional storage engines. Kafka can scale up and down rapidly and easily with no downtime.
- Apache Kafka is frequently used for tracking service calls and IoT sensor data due to its better dependability and throughput. The benefits of low data redundancy and fault tolerance have boosted Kafka’s popularity among other Data Streaming solutions.
Key Features of Apache Kafka
Apache Kafka is extremely popular due to its characteristics that ensure uptime, make scaling simple, and allow it to manage large volumes, among other features. Let’s take a glance at some of the robust features it offers:
- Scalable: Kafka’s partitioned log model distributes data over numerous servers, allowing it to scale beyond what a single server can handle.
- Fast: Kafka decouples data streams, resulting in exceptionally low latency and high speed.
- Durable: The data is written to a disc and partitions are dispersed and duplicated across several servers. This helps to safeguard data from server failure, making it fault-tolerant and durable.
- Fault-Tolerant: The Kafka cluster can cope with master and database failures. It has the ability to restart the server on its own.
- Extensibility: Since Kafka’s prominence in recent years, several other software has developed connectors. This allows for the quick installation of additional features, such as integrating into other applications. Check out how you can integrate Kafka with Redshift and Salesforce.
- Log Aggregation: Since a modern system is often dispersed, data logging from many system components must be centralized to a single location. By centralizing data from all sources, regardless of form or volume, Kafka frequently serves as a single source of truth.
- Stream Processing: Kafka’s fundamental skill is doing real-time calculations on Event Streams. Kafka ingests, stores, and analyses streams of data as they are created, at any scale, from real-time data processing to dataflow programming.
- Metrics and Monitoring: Kafka is frequently used to track operational data. This entails compiling data from scattered apps into centralized feeds with real-time metrics. To read more about how you can analyze your data in Kafka, refer to Real-time Reporting with Kafka Analytics.
Hevo Data, a No-code Data Pipeline, helps load data from any data source such as Databases, SaaS applications, Cloud Storage, SDK, and Streaming Services and simplifies the ETL process. It supports 150+ Data Sources, including Apache Kafka, Kafka Confluent Cloud, and 60+ other Free Sources. You can use Hevo Pipelines to replicate the data from your Apache Kafka Source or Kafka Confluent Cloud to the Destination system.
Check out why Hevo is the Best:
- Completely Automated: Set up in minutes with minimal maintenance.
- 24/5 Live Support: Round-the-clock support via chat, email, and calls.
- Schema Management: Automatic schema detection and mapping.
- Live Monitoring: Track data flow and status in real time.
What can I use Event Streaming for?
Event Streaming can be applied to a vast multitude of use cases across a pantheon of organizations and industries. Here are a few examples that depict the use cases of Event Streaming:
- To monitor and track cars, fleets, shipments, and trucks in real-time such as in the automotive industry and in logistics.
- To process payments and financial transactions in real-time, such as banks, stock exchanges, and insurance.
- To monitor patients in hospital care and forecast changes in condition to make sure that timely treatment is meted out in cases of emergencies.
- To continuously analyze and capture sensor data from IoT devices or other equipment, such as in wind parks and factories.
- To collect and immediately react to customer orders and interactions, such as in mobile applications, retail, and the hotel and travel industry.
- To serve as the foundation for event-driven architectures, data platforms, and microservices.
- To connect, store, and make available data generated by different divisions of a company.
What is Kafka Event Streaming?
- Kafka is an Event Streaming system that works with a stream of events. The practice of capturing data in the form of streams of events in real-time from event sources such as databases, sensors, and mobile devices and storing these event streams durably for later retrieval, analyzing, processing them in real-time, and routing the event streams to various destination technologies as needed is known as Event Streaming.
- Event Streaming enables a constant flow of data and its interpretation, ensuring that the relevant information is available at the right time and in the right location.
- When we use the term “Event” it is vital to comprehend the true meaning of the term. An event is a record of “something that happened”. When you read or send data to Kafka, you use events to accomplish so. An event has a key, value, timestamp, and optional metadata headers.
- So, an event can be thought of as a single atomic piece of data. For example, when we go to a website and register or sign up, that signup is an event that has some data connected with it, which has all of the information that is truly needed to sign up.
- The event may alternatively be thought of as a message containing data, and Kafka is a platform that deals with events in a stream. Here’s an example of an event:
- Event key: “Harry”
- Event value: “Made a payment of $125 to John”
- Event timestamp: “Jan. 01, 2022 at 9:35 a.m.”
- Kafka combines three main features to allow you to create your Event Streaming use cases from start to end:
- To publish (write) and subscribe to (read) streams of events, as well as to import/export data from other systems on a continual basis.
- To safely and durably store streams of events for as long as you desire.
- To process streams of events in real-time or in hindsight.
What is an Event Streaming Platform?
- An Event Streaming Platform (ESP) is defined as a highly durable and scalable system that is capable of continuously ingesting gigabytes of events per second from multiple sources. The data collected can be found in milliseconds for intelligent applications that can react to events as they take place.
- The ultimate goal of an ESP is to capture business events as they happen and react to them in real-time to send personalized and responsive customer experiences.
Understanding Architecture & Working of Kafka Event Streaming
- Apache Kafka is a distributed system of servers and clients that is used to stream events. The TCP network protocol is used by Kafka to preserve a semantic relationship between the two. The servers in an event streaming framework create Kafka Clusters that span one or more data centers or cloud regions.
- Some of the servers also function as storage tiers, which are referred to as brokers. Users can create applications and microservices that read, write, and process streams of events using the clients.
- To generate an event, the server typically saves data on a timestamp, while the client allows the user to take action on the same. In Kafka, each event is saved as a Topic, similar to how files and folders are maintained in a computer system.
- These Kafka Topics are spread across buckets on different brokers. It lets users read and write applications to and from many brokers, enhancing the Kafka Event processing platform’s scalability.
- Now that you have gained a basic understanding of how Kafka Event Streaming actually works in the backend, let’s dive a little deeper into some of the Kafka components and terms you came across.
Kafka Components
- Servers: Brokers or Kafka Connect can be used as servers. Kafka Connect is a tool for data streaming between Apache Kafka and other systems, such as APIs, databases, or other Kafka clusters, whereas Brokers are the storage layer.
- Clients: They enable the creation of producers (publishers) and consumers (subscribers) in APIs and microservices. Clients are available for a variety of programming languages. Clients for Java and Scala, including the higher-level Kafka Streams library, as well as REST APIs, are available.
- Zookeeper: The zookeeper is used by Kafka to manage and coordinate the brokers/cluster.

Kafka Event Concepts
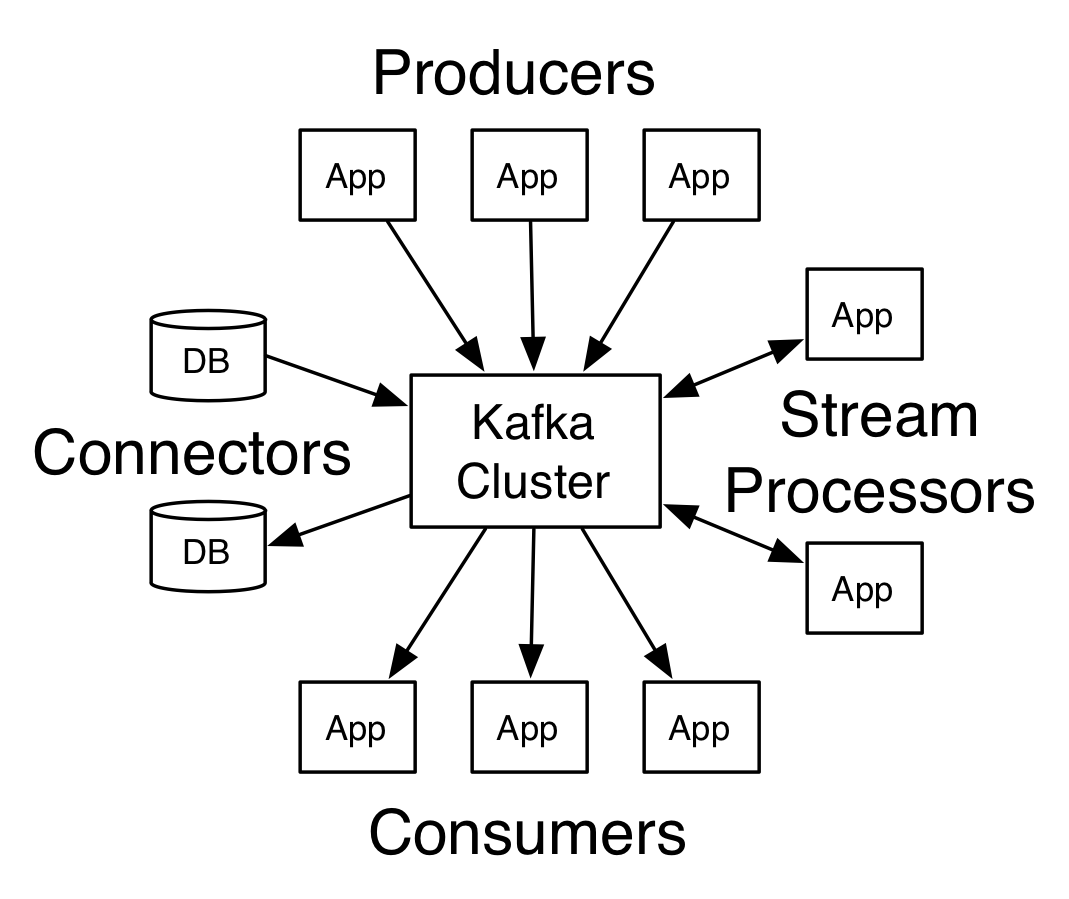
- Producers: They are the client applications that are in charge of publishing events on a Kafka topic.
- Consumers: They’re the client applications responsible for subscribing to a Kafka topic.
- Topic: The topic, which is similar to a table in a relational database, is Kafka’s most fundamental unit of structure. In a file system, a topic is similar to a folder. Topics are in charge of storing events. You establish separate topics for different types of events, as well as filtered and altered versions of the same type of event.
- Partitions: Topics can be distributed across several “buckets” on separate Kafka brokers. This ensures excellent scalability by allowing client applications to simultaneously write and read to/from multiple brokers. The same partition is used for events with the same event key. Any consumer will read the events of a partition in the same order that they were written.
- Brokers: Kafka is made up of a network of devices called brokers. Each broker manages a set of partitions and responds to requests to write new events to or read events from those partitions. Brokers are also in charge of partition replication amongst each other.
Watch the video below, to gain a better understanding of the working of Apache Kafka working.
Steps to Set Up Kafka Event Streaming
Now that you have understood how Kafka Event Streaming works and let’s learn the basic steps to get you started with Kafka Events. So, follow the steps below, to set up your Kafka Events.
- Step 1: Set Up Kafka Environment
- Step 2: Create a Kafka Topic to Store Kafka Events
- Step 3: Write Kafka Events into the Topic
- Step 4: Read Kafka Events
- Step 5: Import/ Export Streams of Events Using Kafka Connect
- Step 6: Process Kafka Events Using Kafka Streams
- Step 7: Terminate Kafka Environment


Step 1: Set Up Kafka Environment
Before setting up your Kafka environment, make sure you have installed the latest version of Kafka. First, Download Kafka. You can extract it using the following commands:
$ tar -xzf kafka_2.13-3.0.0.tgz
$ cd kafka_2.13-3.0.0Also, make sure that your Java version 8.00 or more is installed on your local environment. Now, run the following command to start the ZooKeeper service:
$ bin/zookeeper-server-start.sh config/zookeeper.propertiesNext, open another terminal and run the following command to start the broker service:
$ bin/kafka-server-start.sh config/server.propertiesStep 2: Create a Kafka Topic to Store Kafka Events
Kafka is a distributed Event Streaming platform that lets you manage, read, write and process Events also commonly called Messages or Records. But before you can write any Kafka Event, you need to create a Kafka Topic to store that Event.
So, open another terminal session and run the following command to create a Topic:
$ bin/kafka-topics.sh --create --partitions 1 --replication-factor 1 --topic quickstart-events --bootstrap-server localhost:9092Step 3: Write Kafka Events into the Topic
A Kafka client uses the network to connect with the Kafka brokers in order to write (or read) events. After receiving the events, the brokers will store them in a reliable and fault-tolerant way for as long as you require.
To add a few Kafka Events to your Topic, use the console producer client. By default, each line you type will cause a new Kafka Event to be added to the Topic. Run the following commands:
$ bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
Event 1
Event 2
Event 3You can use Ctrl-C to stop the producer client.
Step 4: Read Kafka Events
Now let’s learn how to read the Kafka Events. Open a new terminal session and run the following commands in the console consumer client to read the Kafka Events you created in the previous steps.
$ bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
Event 1
Event 2
Event 3You can use Ctrl-C to stop the consumer client.
Since Kafka Events are reliably kept in Kafka, they can be read as many times as you want by as many consumers. You can simply confirm this by creating a new terminal session and performing the preceding commands once more.
Step 5: Import/ Export Streams of Events Using Kafka Connect
There’s a good chance you have a lot of data in previous systems like relational databases or conventional messaging systems, as well as a number of apps that use them. Kafka Connect allows you to feed data from other systems into Kafka in real-time, and vice versa. As a result, integrating Kafka with existing systems is a breeze. Hundreds of similar connections are easily accessible to make this operation even easier.
You can learn more about how to continually import and export data into and out of Kafka by visiting the Kafka Connect section.
Step 6: Process Kafka Events Using Kafka Streams
Once your data has been stored in Kafka as Events, you can use the Kafka Streams client library for Java/Scala to process it. It enables you to build mission-critical real-time applications and microservices. Kafka Streams combines the ease of creating and deploying traditional Java and Scala client applications with the benefits of Kafka’s server-side cluster technology to create highly scalable, fault-tolerant, and distributed systems.
To learn how to write and execute a streaming application from start to end using Kafka Streams, refer to the Kafka Streams tutorial and quickstart demo.
Step 7: Terminate Kafka Environment
If you have tried hands-on with Kafka Events and wish to close your Kafka environment properly, use the following keys to terminate your sessions:
- If you haven’t already stopped the producer and consumer clients, use Ctrl-C.
- Use Ctrl-C to stop the Kafka broker.
- Press Ctrl-C to terminate the ZooKeeper server.
- Run the following command if you also wish to erase any data from your local Kafka environment, including any Kafka Events you’ve produced along the way:
$ rm -rf /tmp/kafka-logs /tmp/zookeeperHurray!! You have learned the basic steps to set up your Kafka Event Streaming. To explore more about Kafka Events and Kafka Streaming, refer to the following links:
- Introduction to Kafka Event Streaming
- Apache Kafka Streams Documentation
- Working with Kafka Streams: A Comprehensive Guide
- Setting up Kafka ETL: 2 Easy Methods
Kafka Event Streaming Example
- Kafka is a publish-subscribe event streaming platform. A simple instance of Kafka event streaming can be found in predictive maintenance.
- Imagine a case where the sensor detects a deviation from the normal value. A stream or series of events takes place- the sensor sends the information to the protective relay, and a triggered alarm is sent off.
- Kafka publishes the sensor information and subscribes it to the relay. The data will then be processed and an action (alarm trigger) will take place. Subsequently, Kafka event streaming will store the data as per the requirement.
Industry Use Cases of Kafka Event Streaming

Kafka is leveraged by 60% of Fortune 500 organizations for a variety of purposes. The most widely used open-source stream-processing software, Kafka is recognized for its high throughput, low latency, and fault tolerance. It is capable of handling thousands of messages per second.
Building Data Pipelines, using real-time Data Streams, providing Operational Monitoring, and Data Integration across innumerable sources are just a few of the many Kafka advantages. Let’s look at some of the Kafka Event Streaming use cases in the industry.
- The New York Times makes use of Apache Kafka and the Kafka Streams API to store and disseminate published work in real-time to the different apps and systems that make it accessible to readers.
- Adidas‘ Fast Data Streaming Platform is built on Kafka. This integrates source systems and allows teams to construct real-time event processing for monitoring, analytics, and reporting.
- ByteDance uses Kafka as a data center to collect events and logs for a number of applications, including online model training, real-time data analytics, and stream data processing.
- CloudPhysics‘ high-flow event pipeline, which combines over 1.2 billion metric series from 1000+ data centers for near-real-time data center operational analytics and modeling, is powered by Kafka.
- Salesforce chose Apache Kafka to construct a pub/sub architectural system and to add an enterprise-ready, event-driven layer to their multi-tenant system. Kafka Stream services execute a range of actions to provide their clients with relevant real-time insights.
To understand how LinkedIn, Twitter, Spotify, Netflix, and other companies leverage Kafka, check out this page – Powered By Kafka.
How Apache Kafka’s Event Streaming can benefit Businesses?
Today, businesses are more focused on continuous or streaming data. This means that businesses deal with streaming events that require real-time and immediate actions. In this context, Apache Kafka Event Streaming helps businesses in more ways than one.
- As Apache Kafka leverages checkpoints during streaming, and at regular intervals, it can recover quickly in case of any network or node failure.
- When you use Kafka Event Streaming for business, the speed with which the data is recorded, acted and processed significantly goes up. This will eventually speed up the data-driven decision-making process.
- Apache Kafka improves the performance as it introduces event-driven architecture to the systems that can add scalability and agility to your application.
- As opposed to the traditional shift and store paradigm, Apache Kafka uses Event Streaming that allows dynamic data allocation. It makes the data streaming process faster and improves the performance of the application or website.
Final Thoughts
- In this article, you explored more about Apache Kafka. You discussed the various features that make it so popular in the industry. However, this article highlighted Kafka Event Streaming and why it is required.
- You understood the working of Kafka Events in the backend. In addition, you understood the easy steps to get started with Kafka Event Streaming. At the end of this article, you discovered how Kafka is being used by the top 500 Fortune companies.
- However, extracting complex data from Apache Kafka can be quite challenging and cumbersome. If you are facing these challenges and are looking for some solutions, then check out a simpler alternative like Hevo.
Hevo Data is a No-Code Data Pipeline that offers a faster way to move data from 150+ Data Sources, including Apache Kafka, Kafka Confluent Cloud, and other 60+ Free Sources, into your Data Warehouse to be visualized in a BI tool. You can use Hevo Pipelines to replicate the data from your Apache Kafka Source or Kafka Confluent Cloud to the Destination system. Hevo is fully automated and, hence, does not require you to code.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. What is an event in Kafka?
An event in Kafka is a piece of data or message that gets stored and processed. It
typically consists of a key, value, and timestamp.
2. What is Kafka, and why is it used?
Kafka is a distributed data streaming platform used to handle real-time data feeds. It’s used for building data pipelines, streaming analytics, and event-driven systems.
3. How do I send a Kafka event?
You send a Kafka event by creating a producer, connecting it to a Kafka topic, and then using it to send messages (events) to that topic.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





