

Oracle database replication is vital for businesses looking to ensure data consistency, availability, and disaster recovery across multiple locations. With Oracle’s robust set of replication tools, companies can efficiently synchronize data in real time, scale their operations, and safeguard against data loss.
Whether you aim to streamline data sharing between global offices or protect critical applications from downtime, understanding the various replication methods available is key. In this blog, you will dive into Oracle database replication, explore its various methods, and see how tools like Hevo Data can simplify the process, making replication more efficient and reliable.
Table of Contents
What is Oracle Database Replication?

Oracle database replication refers to the process of creating and maintaining one or more synchronized copies of a database, ensuring data consistency across different locations for high availability, disaster recovery, load balancing, and reporting
Oracle offers several replication methods, including physical standby (Data Guard), logical standby, snapshot replication, multi-master replication, and Oracle GoldenGate for real-time replication.
Why Do We Replicate an Oracle Database?
- Replicating an Oracle database makes it easier for companies, businesses, and organizations to share, distribute, protect, and use data efficiently.
- This replication also helps create backup and recovery points for data to avoid any data loss.
- Business runs their operation in different regions, and with Oracle, this replication allows companies to synchronize their data across different locations in real time, share data with vendors and partners, and aggregate data from their branches, both international and local.
- It also enhances the availability of applications by providing alternative data access options, ensuring continuity even if one site becomes unavailable.
Providing a high-quality ETL solution can be a difficult task if you have a large volume of data. Hevo’s automated, No-code platform empowers you with everything you need to have for a smooth Oracle database replication experience. Check out what makes Hevo amazing:
- Live Monitoring & Support: Hevo provides live data flow monitoring and 24/7 customer support via chat, email, and calls.
- Secure & Reliable: Hevo’s fault-tolerant architecture ensures secure, consistent data handling with zero loss and automatic schema management.
- Efficient Data Transfer: Hevo supports real-time, incremental data loads, optimizing bandwidth usage for both ends.
Note: See how database replication simplifies the distribution and synchronization of data for test systems.
Types of Database Replication In Oracle
| Replication Type | Description | Use Case |
| Multi-master replication | Allows updates on all nodes. Changes made at any node are propagated to all others. | Ideal for distributed systems where updates happen at multiple locations. |
| Master-slave replication | One node is designated as the master (source), and the other nodes are slaves (replicas) that only receive updates from the master. | Useful when centralized control is needed and only the master node accepts writes. |
| Single-master replication | Similar to master-slave, the master only handles read and write operations, while the replica is read-only. | Common for scaling read-heavy applications with centralized data writes. |
| Logical replication | Involves replication of specific database objects like tables or views, rather than the entire database. It uses the Oracle GoldenGate technology. | Suitable for data warehousing, selective data replication, and migration scenarios. |
| Physical replication | Replicates a database’s exact structure and data, maintaining the same data and database architecture. Oracle Data Guard is often used. | Best for disaster recovery, backup, and failover systems. |
| Snapshot replication | Copies data at a specific point in time. Changes to the source database are not automatically propagated to replicas. | Used when periodically refreshing data in read-only replicas. |
Methods to Setup Oracle Database Replication
Method 1: Using Hevo Data
Hevo provides a no-code, automated data pipeline solution to replicate data from Oracle to other databases or data warehouses. Here’s a simplified flow:
Step 1: Set Up Oracle Source in Hevo
- In the Hevo dashboard, select Oracle as the source database.
- Provide connection details (hostname, database name, username, password).
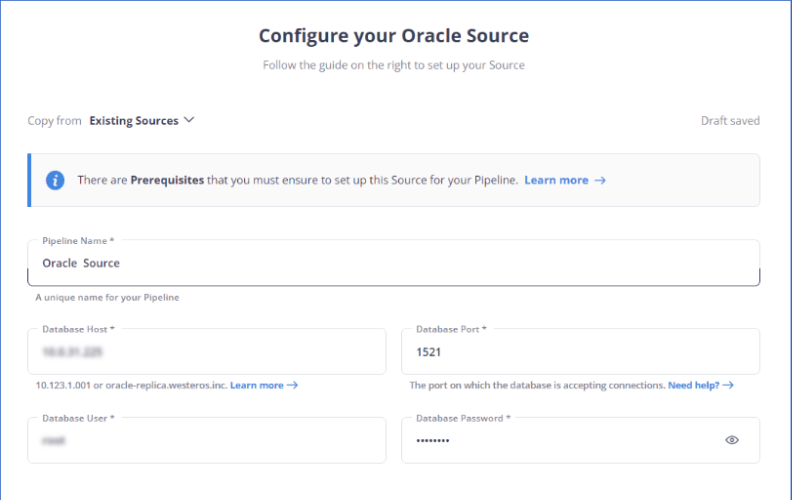
Step 2: Set Up The Destination (e.g., Amazon S3, Snowflake)
- Choose the destination database and provide connection details.
Step 3: Select The Tables To Replicate
- Hevo will automatically detect available tables in the Oracle source database.
Step 4: Schedule Replication
Hevo allows you to set the frequency of replication (e.g., real-time, hourly, daily).
Method 2: Using Incremental Approach
The incremental approach to Oracle database replication focuses on capturing and replicating only the changes made to the data since the last replication cycle rather than copying the entire database or table contents each time. This method is particularly useful for databases with large volumes of data where full replication would be time-consuming and resource-intensive.
To use this method, you must possess a copy of the source table as well as an older version of the same table.
- You can obtain the difference between the two tables, which are named new_version and old_version by running the command provided below.
SELECT * FROM new_version
MINUS
SELECT * FROM old_version;- This above command returns the inserts and updates in the new version of the table.
- After you get the difference between the two tables, you can load the data into the target database.
- You also need to replace the old_version table with the new_version table so you can compare it with a future new_version of the table.
Drawbacks
- It can be computationally expensive, as it requires comparing two tables and performing set operations.
- It can be slow, as it depends on the replication interval and the amount of changed data.
- It can be difficult to restore data, as incremental changes must be applied in the correct order.
Method 3: Using Full Dump And Load
The full dump and load is a replication method that takes a complete snapshot of a table at specified intervals and transfers it to another database or system. You can also check other types of data replication methods to get a full picture.
SPOOL "/data/emp.csv"
SELECT /csv/ * FROM EMP;
SPOOL OFF- This command generates a CSV file containing all the data from the table, which can then be read and loaded into the target database.
Drawbacks
- Slow and inefficient: This method takes a long time to perform the dump and load, especially for large tables. It also wastes a lot of resources by copying the entire table every time, even if there are only a few changes.
- Not real-time: This method relies on periodic intervals to perform the replication, which means the target database is not always up to date with the source database. This can cause data inconsistency and stale results for queries.
- Difficult to restore: This method does not keep track of the previous versions of the data, so it is hard to restore the data to a previous state if needed. The only option is to load a full backup file, which can be time-consuming and error-prone.



Method 4: Using A Trigger-Based Approach
The trigger-based approach is a synchronous process because the transactions in the source database will not get complete unless the triggers are successfully executed. It means that there is a performance hit in this case also. But using a multi-master replicated instance of Oracle as the source database can avoid this problem.
- Oracle provides a built-in stored procedure to configure the trigger and watch the source table for updates.
- The crux of this approach is the following command that configures a sync_source from where a ‘change table’ can read changes.
BEGIN
DBMS_CDC_PUBLISH.CREATE_CHANGE_TABLE(
owner => 'cdcpub',
change_table_name => 'employee_change_set',
change_set_name => 'EMP_DAILY',
source_schema => 'SH',
source_table => 'EMPLOYEE',
column_type_list => 'EMP_ID NUMBER(6),
EMP_NAME VARCHAR2(50),
EMP_AGE NUMBER(8,2)',
capture_values => 'both',
rs_id => 'y',
row_id => 'n',
user_id => 'n',
timestamp => 'n',
object_id => 'n',
source_colmap => 'y',
target_colmap => 'y',
options_string => 'TABLESPACE TS_EMP_DAILY');
END;The above command creates a changeset called ‘employee_change_set’ based on the table EMPLOYEE.
Drawbacks
Even though it solves the lack of real-time support problems in the first approach, this method still has some drawbacks.
- There is a performance hit in the source database since triggers can delay the completion of a transaction.
- For inserting into a target database, there is still significant work involved in building a custom script to subscribe to the changeset table and write accordingly.
Method 5: Using Oracle Golden Gate CDC
Oracle GoldenGate is a software tool that enables real-time data replication using Oracle Change Data Capture (CDC) technology. CDC is a technique that captures and replicates only the changes made to the data rather than the entire data set, thus reducing the overhead and latency of data movement.
Oracle GoldenGate consists of several components and processes that work together to extract, transform, and apply data across different databases and platforms. To set up Oracle GoldenGate replication, the following steps are required:
Enable logging and supplemental logging on the source database to capture the data changes.
- First, you should log in to your database as a system user.
sys as sysdba- Log into your database as a system user and enable force logging, supplemental logging, and archive log mode. Use these commands:
shutdown
startup mount
alter database archivelog;
alter database open;
select log_mode from v$database;
alter database add supplemental log data(all) columns;
select SUPPLEMENTAL_LOG_DATA_ALL from v$database;
alter database force logging;
alter system switch logfile;
alter database add supplemental log data;- Create a new user called ggtest, assign it a secure password such as ggtest (or any other password of your choice), and ensure it has all the required permissions.
create user username identified by ggtest;
grant resource, dba, connect to ggtest;- After installation, create an admin user (e.g., ggowner) and set up a GoldenGate tablespace.
create tablespace goldengate
datafile 'goldengate.dbf'
size 100m
autoextend on;
alter user ggowner default tablespace goldengate;- Set up extract and pump processes using the GoldenGate command-line tool ggsci.exe.
edit params extract
edit params pumpora- On the target system, create the replicat process to apply data changes.
add replicat repora, EXTTRAIL ./dirdat/rt,
checkpointtable ggowner.checkpointtable- Use the below command to add data to the test table.
insert into test values(2,'Madhuka');
commit;You have successfully set up Oracle GoldenGate to enable real-time replication when the replication is confirmed.
Drawbacks
The drawbacks of this approach are listed below:
- Golden Gate configuration is a complex process and needs an expert Oracle admin to get it right.
- The initial load of the target database is still a problem because Golden Gate is notorious for its slow first-time load. Most database administrators still prefer using the traditional dump and export method for the first load.
- Oracle GoldenGate has a command-line interface that can be challenging for non-technical users.
- Oracle GoldenGate consumes a lot of memory during the extract process, which can affect the source database performance.
- Oracle GoldenGate may encounter character set problems when migrating data across different databases and platforms.
- The process might cause data corruption when dumping data in XML, HDFS, or other formats, which requires custom scripts to detect and correct.
Top 5 Oracle Replication Tools
1. Hevo Data
Rating: 4.3(G2)
Hevo Data, a no-code data pipeline platform, reliably replicates data from any data source with zero maintenance. You can get started with Hevo’s 14-day free trial and instantly move data from 150+ pre-built integrations comprising a wide range of SaaS apps and databases.
With Hevo, fuel your analytics by loading data into the warehouse and enriching it with built-in no-code transformations. Its fault-tolerant architecture ensures that the data is handled in a secure, consistent manner with zero data loss.
Key Features
- Near Real-Time Replication: Get access to near real-time replication on All Plans.
- In-built Transformations: Format your data on the fly with Hevo’s preload transformations using either the drag-and-drop interface or our nifty Python interface.
- Monitoring and Observability: Monitor pipeline health with intuitive dashboards that reveal every state of the pipeline and data flow.


2. Carbonite Availability
Rating: 4.1(G2)
Carbonite Availability is one of Oracle’s data replication tools that ensures that crucial business systems are accessible to all necessary users and applications that depend on them at all times. This software keeps all critical business systems available at all times and prevents data loss on Linux and Windows Servers. It houses a continuous replication technology that is capable of maintaining an up-to-date copy of the operating business environment without putting too much load on the primary system or network bandwidth.
Cons
- Cost: Lacks a transparent pricing model, making it difficult to estimate costs upfront.
- Complex Setup: This may require significant configuration for optimal performance.
- Limited Cross-Platform Support: Primarily focused on Linux and Windows servers, may not support all OS environments.
3. Quest Shareplex
Rating: 4.3(G2)
Quest SharePlex is a popular Oracle database replication software that ensures high availability, scalability, and improved reporting. With Quest SharePlex, users can replicate Oracle data to other databases, including SQL Server or Kafka.
Cons
- Performance Impact: While it ensures data accuracy, heavy data loads may affect replication speed and system performance.
- Complex Licensing: Pricing is not transparent, and the cost depends on specific data requirements.
- Requires Manual Setup: Although it builds the target database automatically, some configurations may require expertise.
4. Oracle GoldenGate
Rating: 3.9(G2)
GoldenGate is a product by Oracle that gives businesses the ability to replicate, filter, and transform data from one Oracle database to another supported heterogeneous database. This tool is capable of replicating data 6 times faster than other traditional data movement solutions and ensures high availability, disaster recovery, and zero downtime migrations.
Cons
- Expensive: Licensing costs can be high, especially for smaller businesses or startups.
- Complex Setup: Requires specialized knowledge for installation and configuration.
- Resource-Intensive: Can consume significant system resources, affecting overall performance.
5. IBM InfoSphere Change Data Capture

Rating: 4.8(G2)
InfoSphere CDC is IBM’s data replication solution designed to capture database changes in real time and replicate them to target databases. It offers low-impact change capture and rapid delivery of data changes, supporting key information management initiatives such as dynamic data warehousing, application consolidations or migrations, master data management, and operational business intelligence.
Cons
- Performance Overhead: This may introduce latency, especially with large datasets or complex configurations.
- Complex Configuration: The tool can be challenging to set up and configure without proper expertise.
- High Cost: Pricing is not transparent and tends to be expensive, particularly for large-scale deployments.
Conclusion
The article introduced you to Oracle databases and listed various methods for replicating your Oracle data. You will need to implement it manually, which will consume your time & resources and is error-prone. Moreover, you need a full working knowledge of the backend tools to successfully implement the in-house data replication mechanism. If you are tired of making compromises and want a simple, easy-to-use, and completely managed Oracle database replication experience, you should have a look at what Hevo offers.
Use Hevo’s no-code data pipeline to replicate data from Oracle to a destination of your choice in a seamless and automated way. Try our 14-day full feature access free trial.
Frequently Asked Questions
1. How to recreate an Oracle database?
Use DBCA (Database Configuration Assistant) or RMAN (Recovery Manager) to recreate a database. You can also restore from a backup using the CREATE DATABASE command.
2. What is the database replication process?
Replication involves copying data between databases. Oracle uses techniques like physical or logical replication, with changes made in the source database being synchronized with replicas.
3. How to set up replication in Oracle?
Set up Oracle replication using Oracle GoldenGate or Data Guard. Configure the master and replica databases, set up capture, apply, and propagate processes for data synchronization.




