

PostgreSQL is an open-source object-relational database system with an emphasis on extensibility and standard compliance. ERP, CRM, marketing, and finance applications are among the most popular PostgreSQL integrations.
It can be difficult to strike the right balance between sales data accessibility and maintaining control over your Pipedrive account. PostgreSQL Pipedrive Integration can be useful in any kind of situation,
This article will assist you with PostgreSQL Pipedrive Integration. If you want to get analytics-ready data without the manual effort, you can integrate Pipedrive to PostgreSQL, allowing you to focus on what matters most: extracting value from your business data.
Table of Contents
What is PostgreSQL?

PostgreSQL is an Open-Source advanced Relational Database System Model. PostgreSQL is a dependable Database model that has been developed for more than two decades by the Open-Source Community. For organizations evaluating database options, understanding the differences between PostgreSQL and MySQL can provide valuable insights into each system’s capabilities and suitability for dynamic websites and web applications.
Postgres supports querying as well as Windowing. It supports both relational and non-relational querying. Because of its adaptability, it can be used as both a Transactional Database and an Analytics Data Warehouse.
Key Features of PostgreSQL
Listed below are some features of PostgreSQL:
- Support for Querying and Programming Languages: PostgreSQL allows for SQL and JSON queries. Python, Java, C#, C/C+, Ruby, JavaScript, Perl, Go, and Tcl is the most popular programming languages supported by PostgreSQL.
- Inheritance of a Table: Inheritance is a powerful object-relational feature supported by PostgreSQL. This allows a table to inherit some of its column properties from one or more other tables, forming a parent-child relationship. The child table inherits the same columns, constraints, and defined columns as its parent table (or tables).
- Integrity of Foreign Key Referential: The foreign key concept in PostgreSQL is based on the first table’s column combination with primary key values from the second table. It is also referred to as a constraint or a referential integrity constraint.
- Replication Asynchronous: Asynchronous replication in PostgreSQL provides a dependable and simple method of distributing data and making your setups more failsafe. Administrators can easily create read-only replicas of a primary server in the event of server failure or disaster.
What is Pipedrive?
Pipedrive is a web-based Sales CRM and Pipeline Management solution that helps companies plan and track their sales activities. Pipedrive, which was developed using an activity-based selling methodology, automates every step of the process of converting a potential deal into a successful sale. Because Pipedrive is completely customizable, you can create your own distinct Sales Processes and Patterns without relying on any pre-existing standards. Pipedrive’s incredible flexibility is one of its most significant advantages. Leveraging the best Pipedrive integrations can help drive sales and streamline buyer engagement.
Key Features of Pipedrive
The following are some of Pipedrive’s key features:
- Reporting: Pipedrive helps to improve insight and active reporting. When developing an optimized Sales technique, measuring a company’s performance against a specific set of objectives becomes critical.
- Automation: Pipedrive is popular among businesses because it automates various sales operations.
- Integrations with Third Parties: Pipedrive can be used by businesses in conjunction with a variety of third-party applications to increase sales and generate invoices. This is a standard requirement, particularly when a company’s management attempts to access customer information and make changes via their mobile phones. Pipedrive also allows employees to use their existing applications alongside it.
- Templates that are Unique: Pipedrive allows employees to create their own templates and insert images and context to improve their Sales Funnel. A personalized format or template can also help employees fine-tune metrics that must be observed when comparing.
Method 1: Using Hevo Data’s No-code Data Pipeline to Connect PostgreSQL Pipedrive
Hevo Data, an Automated No-code Data Pipeline, helps you load data from PostgreSQL to Pipedrive in real-time and provides you with a hassle-free experience. You can easily ingest data using Hevo’s Data Pipelines and replicate it to your desired Data Warehouse without writing a single line of code.
Method 2: Manually Integrating PostgreSQL Pipedrive
One major drawback is that you need to do manual integration of each field from the source to the destination which is a time-consuming and error-prone operation.
Get Started with Hevo for FreeMethod 1: Using Hevo Data’s No-code Data Pipeline to Connect PostgreSQL Pipedrive
To integrate PostgreSQL Pipedrive with Hevo, simply follow these steps:
Step 1: Set up the Source
- Select the Pipedrive variant on the Select Source Type page.
- Fill in the required credentials required to configure Pipedrive as your source.
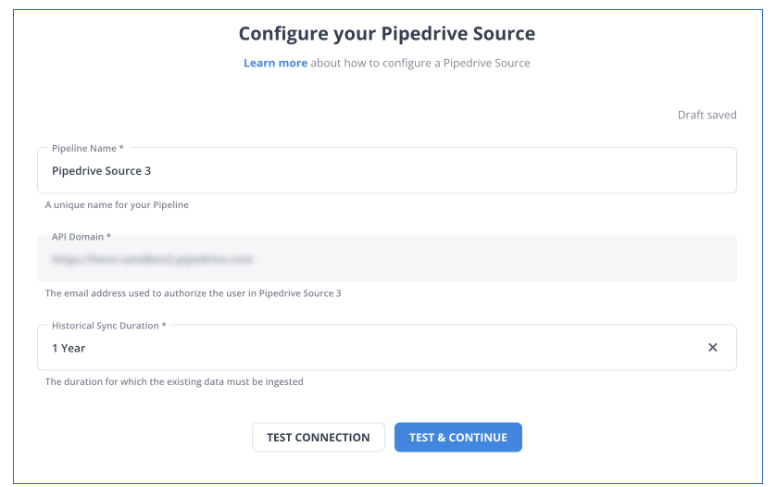
Step 2: Setting up the Destination
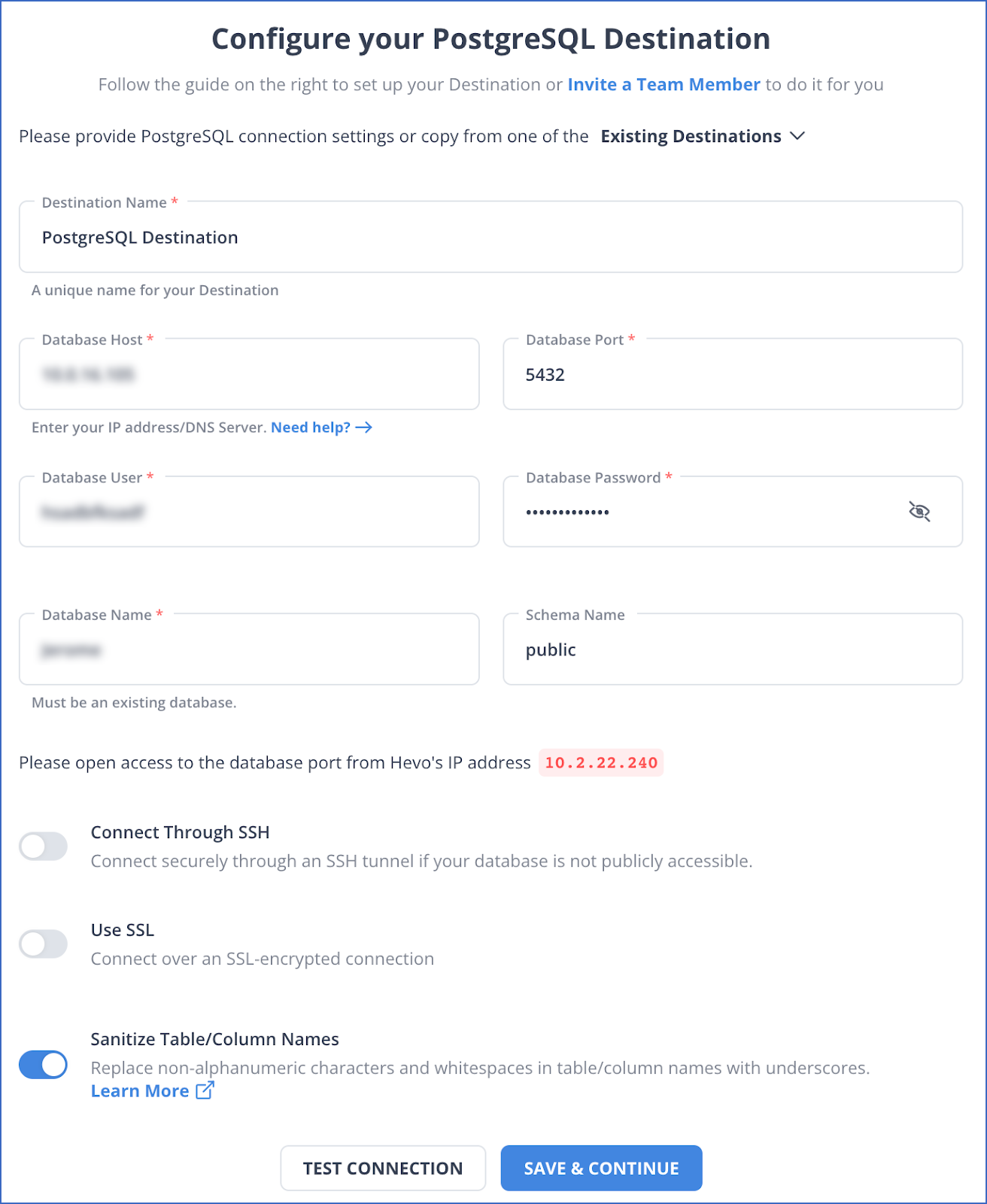
- Select PostgreSQL on the Add Destination page.
- Configure PostgreSQL connection settings as shown in the image below
Here are more reasons to try Hevo:
- Smooth Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to your schema in the desired Data Warehouse.
- Exceptional Data Transformations: Best-in-class & Native Support for Complex Data Transformation at fingertips. Code & No-code Fexibilty designed for everyone.
- Quick Setup: Hevo with its automated features, can be set up in minimal time. Moreover, with its simple and interactive UI, it is extremely easy for new customers to work on and perform operations.
- Built To Scale: As the number of sources and the volume of your data grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Method 2: Manually Integrating PostgreSQL Pipedrive
To get started with the manual PostgreSQL Pipedrive Integration, you have to follow these steps:
- Step 1: Set up API access to Pipedrive.
- Step 2: Set up the PostgreSQL database.
- Step 3: Install Required Libraries
- Step 4: Extract data using Pipedrive.
- Step 4: Connect to PostgreSQL and Insert data
Step 1: Set Up API Access to Pipedrive
- Obtain Pipedrive API Key: Log in to your Pipedrive account, go to Settings > Personal Preferences > API, and copy your API key.
- Note the API URL: The base URL for the Pipedrive API is https://{companydomain}.pipedrive.com/v1, where {companydomain} is your company’s domain in Pipedrive.
Step 2: Set Up PostgreSQL Database
- Create a Database (if not already created):
CREATE DATABASE pipedrive_data;- Create a Table: Create a table in PostgreSQL to store the data from Pipedrive.
CREATE TABLE pipedrive_deals (
id SERIAL PRIMARY KEY,
deal_id INT,
title VARCHAR(255),
value NUMERIC,
currency VARCHAR(10),
stage_id INT,
org_name VARCHAR(255),
status VARCHAR(50),
close_date DATE
);Step 3: Install Required Libraries
- Install Python libraries to interact with Pipedrive’s API and PostgreSQL.
pip install requests psycopg2Step 4: Extract Data from Pipedrive
Write a Python script to pull data from the Pipedrive API.
- Set Up Pipedrive API Connection
import requests
# Pipedrive credentials
api_token = 'YOUR_PIPEDRIVE_API_KEY'
base_url = 'https://{companydomain}.pipedrive.com/v1'
# Fetch deals data
def get_deals():
url = f'{base_url}/deals?api_token={api_token}'
response = requests.get(url)
deals = response.json()['data'] # Get data from JSON response
return deals
deals = get_deals()Step 5: Connect to PostgreSQL and Insert Data
Using the psycopg2 library, connect to PostgreSQL and insert the extracted data into the table created in Step 2.
- Connect to PostgreSQL and Insert Data:
import psycopg2
# PostgreSQL credentials
pg_connection = psycopg2.connect(
dbname="pipedrive_data",
user="your_pg_user",
password="your_pg_password",
host="localhost",
port="5432"
)
# Insert data into PostgreSQL
def insert_deals(deals):
cursor = pg_connection.cursor()
for deal in deals:
deal_id = deal.get('id')
title = deal.get('title')
value = deal.get('value')
currency = deal.get('currency')
stage_id = deal.get('stage_id')
org_name = deal.get('org_name')
status = deal.get('status')
close_date = deal.get('close_date')
cursor.execute('''
INSERT INTO pipedrive_deals (deal_id, title, value, currency, stage_id, org_name, status, close_date)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
ON CONFLICT (deal_id) DO NOTHING;
''', (deal_id, title, value, currency, stage_id, org_name, status, close_date))
pg_connection.commit()
cursor.close()
insert_deals(deals)
pg_connection.close()Limitation of Manual PostgreSQL Pipedrive Integration
The following are some of the limitations of Manual PostgreSQL Pipedrive Integration:
- Creating a Data Pipeline: Building an in-house data pipeline requires extensive experience, time, and manpower, as well as a high risk of error.
- Error-Prone: You must extract data and then connect it to the Data Warehouse correctly.
- Hard coding: Analysts must write code and manage infrastructure, but they cannot access data within hours.

Benefits of PostgreSQL Pipedrive Integration
- Transferring Data: Data replication can be used to simply copy Pipedrive data to PostgreSQL without the need for mapping configuration. It enables you to create a copy of Pipedrive data in PostgreSQL and keep it up to date with minimal configuration.
- PostgreSQL data to Pipedrive and vice-versa: PostgreSQL Pipedrive Integration provides several advantages when importing Pipedrive data to PostgreSQL or vice versa. The Import allows you to perform any DML operations on imported PostgreSQL data in Pipedrive, import data from multiple PostgreSQL objects at once, and so on. These capabilities are available in both directions.
- 2 Way Synchronization: PostgreSQL Pipedrive makes it simple to perform bidirectional data synchronization between Pipedrive and PostgreSQL. It does not load all of the data each time it performs the synchronization. It monitors changes in the synchronized data sources and only makes necessary data changes.
Conclusion
In this article, you gained a basic understanding of Pipedrive and PostgreSQL. You also explored the two methods to set up Pipedrive PostgreSQL Integration. At the end of this article, you discovered the various advantages of setting up the Pipedrive PostgreSQL Integration.
However, migrating complex data from a wide range of data sources such as DynamoDB, other databases, CRMs, project management tools, streaming services, and marketing platforms to your PostgreSQL database can appear to be a daunting task.
This is where Hevo can help save your day!Hevo Data is a No-Code Data Pipeline that offers a faster way to move data from 150+ Data Sources, such as Pipedrive, to a destination of your choice, such as PostgreSQL. Hevo is fully automated and, hence, does not require you to code.
Want to take Hevo for a spin? SIGN UP and experience the feature-rich Hevo suite firsthand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
Frequently Asked Questions
1. Does Pipedrive integrate with constant contact?
Yes, Pipedrive can integrate with Constant Contact using third-party tools like Zapier to sync contacts or automate email campaigns.
2. Does Pipedrive integrate with Salesforce?
Yes, Pipedrive can integrate with Salesforce using tools like Zapier or PieSync to sync contacts, leads, and other CRM data between the platforms.
3. Does Pipedrive work with Zapier?
Yes, Pipedrive works seamlessly with Zapier, allowing you to automate workflows and connect it with hundreds of other apps for various tasks.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



