

Airflow is a Task Automation tool. It helps organizations to schedule their tasks so that they are executed when the right time comes. This relieves the employees from doing tasks repetitively. When using Airflow, you will want to access it and perform some tasks from other tools. Furthermore, Apache Airflow is used to schedule and orchestrate data pipelines or workflows.
Apache Spark is one of the most sought all-purpose, distributed data-processing engines. It is used on daily basis by many large organizations for use in a wide range of circumstances. Spark provides various libraries for SQL, machine learning, graph computation, and stream processing on top of Spark Processing Units which can be used together in an application.
In this article, you will gain information about scheduling Spark Airflow Jobs. You will also gain a holistic understanding of Apache Airflow, Apache Spark, their key features, DAGs, Operators, Dependencies, and the steps for scheduling Spark Airflow Jobs. Read along to find out in-depth information about scheduling Spark Airflow Jobs.
Table of Contents
What is Apache Airflow?

Airflow is a platform that enables its users to automate scripts for performing tasks. It comes with a scheduler that executes tasks on an array of workers while following a set of defined dependencies. Airflow also comes with rich command-line utilities that make it easy for its users to work with directed acyclic graphs (DAGs). The DAGs simplify the process of ordering and managing tasks for companies.
Airflow also has a rich user interface that makes it easy to monitor progress, visualize pipelines running in production, and troubleshoot issues when necessary.
Key Features of Airflow
- Dynamic Integration: Airflow uses Python as the backend programming language to generate dynamic pipelines. Several operators, hooks, and connectors are available that create DAG and tie them to create workflows.
- Extensible: Airflow is an open-source platform, and so it allows users to define their custom operators, executors, and hooks. You can also extend the libraries so that it fits the level of abstraction that suits your environment.
- Elegant User Interface: Airflow uses Jinja templates to create pipelines, and hence the pipelines are lean and explicit. Parameterizing your scripts is a straightforward process in Airflow.
- Scalable: Airflow is designed to scale up to infinity. You can define as many dependent workflows as you want. Airflow creates a message queue to orchestrate an arbitrary number of workers.
Airflow can easily integrate with all the modern systems for orchestration. Some of these modern systems are as follows:
- Google Cloud Platform
- Amazon Web Services
- Microsoft Azure
- Apache Druid
- Snowflake
- Hadoop ecosystem
- Apache Spark
- PostgreSQL, SQL Server
- Google Drive
- JIRA
- Slack
- Databricks
You can find the complete list here.
Tired of dealing with Airflow’s complex DAG management and parallelism issues? Simplify your data pipeline with Hevo’s automated ETL platform. Hevo handles concurrent data processing effortlessly, freeing you from the hassle of managing parallel workflows.
Why Consider Hevo
- No-Code Setup: Easily configure data pipelines without writing any code.
- Real-Time Sync: Enjoy continuous data updates for accurate analysis.
- Reliable & Scalable: Handle growing data volumes with Hevo’s robust infrastructure.
Experience smooth scalability and streamlined data operations—no Airflow headaches required.
Get Started with Hevo for FreeWhat is Apache Spark?

Apache Spark is an open-source, distributed processing system used for large data workloads. Numerous companies have embraced this software due to its numerous benefits such as speed. The platform utilizes RAM for data processing, making it much faster than disk drives.
Now that you have a rough idea of Apache Spark, what does it entail? One of the most widely used components is Apache Spark SQL. Simply put, this is Apache Spark’s SQL wing, meaning it brings native support for SQL to the platform. Moreover, it streamlines the query process of data stored in RDDs and external sources. Other components include Spark Core, Spark Streaming, GraphX, and MLib.
So what are the top features of the platform? Read on below to find out,
Key Features of Apache Spark
Some of the features of Apache Spark are listed below:
- Lighting Fast Speed: As a Big Data Tool, Spark has to satisfy corporations’ needs of processing big data at high speed. Accordingly, the tool depends on Resilient Distributed Dataset (RDD), where data is transparently stored on the memory, and read/write operations are carried out when needed. The benefit? is Disc read and write time is reduced, increasing speed.
- Supports Sophisticated Analytics: Apart from the map and reduce operations, Spark supports SQL queries, data streaming, and advanced analytics. Its high-level components such as MLib, Spark Streaming, and Spark SQL make this possible.
- Real-Time Stream Processing: This tool is designed to handle real-time data streaming. Spark can recover lost work and deliver high-level functionality without requiring extra code.
- Usability: The software allows you to write scalable applications in several languages, including Java, Python, R, and Scala. Developers can use the language to query data from these languages’ shells.
What are DAGs in Airflow?
DAG stands for Directed Acyclic Graph. The core concept of Airflow is a DAG, which collects Tasks and organizes them with dependencies and relationships to specify how they should run.
In simple terms, it is a graph with nodes, directed edges, and no cycles.
Because there is a cyclical nature to things. Because Node A is dependent on Node C, which is dependent on Node B, and Node B is dependent on Node A, this invalid DAG will not run at all. And also the first DAG has no cycles.
In Apache Airflow, a DAG is similar to a Data Pipeline. As a result, whenever you see the term “DAG,” it refers to a “Data Pipeline.” Finally, when a DAG is triggered, a DAGRun is created. A DAGRun is an instance of your DAG with an execution date in Airflow.
What is an Airflow Operator?
In an Airflow DAG, Nodes are Operators. In other words, a Task in your DAG is an Operator. An Operator is a class encapsulating the logic of what you want to achieve. For example, you want to execute a python function, you will use the PythonOperator.
When an operator is triggered, it becomes a task, and more specifically, a task instance. An example of operators:
from airflow.operators.dummy import DummyOperator
from airflow.operators.bash import BashOperator
# The DummyOperator is a task and does nothing
accurate = DummyOperator(
task_id='accurate'
)
# The BashOperator is a task to execute a bash command
commands = BashOperator(
task_id='commands'
bash_command='sleep 5'
)Both Operators in the preceding code snippet have some arguments. The task_id is the first one. The task_id is the operator’s unique identifier in the DAG. Each Operator must have a unique task_id. The other arguments to fill in are determined by the operator.
What are Dependencies in Airflow?
A DAG in Airflow has directed edges. Those directed edges are the Dependencies between all of your operators/tasks in an Airflow DAG. Essentially, if you want to say “Task A is executed before Task B,” then the corresponding dependency can be illustrated as shown in the example below.
task_a >> task_b
# Or
task_b << task_aThe >> and << represent “right bitshift” and “left bitshift,” or “set downstream task” and “set upstream task,” respectively. On the first line of the example, we say that task_b is a downstream task to task_a. The second line specifies that task_a is an upstream task of task_b.
Scheduling Spark Airflow Jobs
The following link has been taken as a reference for scheduling Spark Airflow Jobs.
Failure is unavoidable in Apache Spark applications for a variety of reasons. OOM (Out of Memory at the driver or executor level) is one of the most common failures. We can manage (schedule, retry, alert, etc.) Spark applications in Airflow without any code outside the Airflow ecosystem easily.
For illustrating the scheduling of Spark Airflow jobs, you will be focusing on building a DAG of three Spark app tasks(i.e. SparkSubmitOperator) in Airflow.
The steps involved in scheduling Spark Airflow Jobs are as follows:
- Scheduling Spark Airflow Jobs: Business Logic
- Scheduling Spark Airflow Jobs: Diving into Airflow
- Scheduling Spark Airflow Jobs: Building the DAG
1) Business Logic
The 3 tasks that will be taken in illustrating the scheduling of Spark Airflow Jobs are as follows:
Task 1: Data Ingestion
You have a Spark Structured Streaming app that consumes Kafka user flight search data and appends it to a Delta table. This is not a real-time streaming app because you do not need to process the search data as soon as it is generated, so first set the writeStream option Trigger to once (Trigger.once) in the Spark app to run as a batch job while gaining the benefits of the Spark Structured Streaming app. This task should be run once every hour. This Spark app appends data to a Delta table with the following schema, which is partitioned by year_month:
flight_search
root
|-- searched_at: timestamp (nullable = true)
|-- responsed_at: timestamp (nullable = false)
|-- channel: string (nullable = true)
|-- origin: string (nullable = true)
|-- destination: string (nullable = true)
|-- departure_date: date (nullable = true)
|-- year_month: string (nullable = true)Task 2: search-waiting-time
This is a simple Spark batch job that reads the flight_search Delta table (which task 1 is appending to) and then calculates the time between searched_at and responsed_at.
Task 3: nb-search
This is a simple Spark batch job that reads the flight_search Delta table (which task 1 is appending to) and counts the number of searches by channel and route.
After the successful execution of task 1, then task 2 and task 3 should be run in parallel.
2) Diving into Airflow
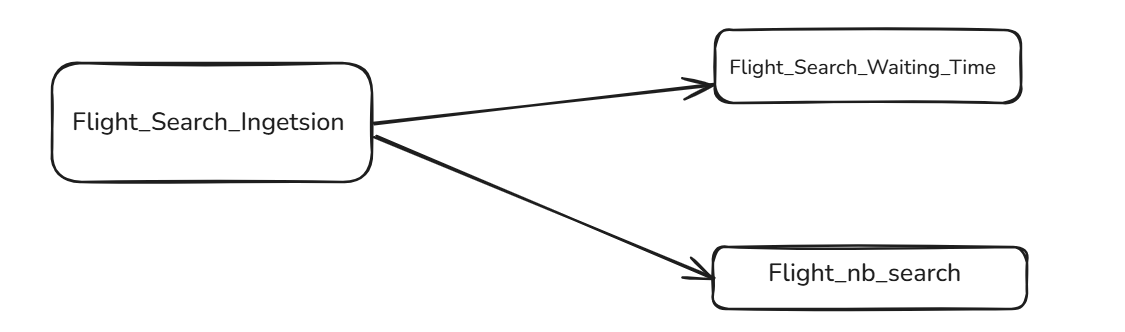
The below diagram illustrates the graph view of a DAG named flight_search_dag which consists of 3 tasks (all are types of SparkSubmitOperator operator).
- Task 1: flight_search_ingestion
- Task 2: flight_search_waiting_time
- Task 3: flight_nb_search
Task 2 and Task 3, both depend on Task 1 if run successfully and are run in parallel.
A) Installation of Airflow
The installation of Airflow is pretty simple and can be referred to from here.
- Step 1: Set the environment variable AIRFLOW_HOME to be used by Airflow to create its own configuration files, log directory, and so on.
export AIRFLOW_HOME=~/airflow- Step 2: To install and run the Airflow, you can do the following:
#install the Airflow using pip
pip install apache-airflow#you need to initialize the Airflow db:
airflow initdb#you can interact with Airflow after starting the webserver
airflow webserver -p 8080#Airflow manages the DAG using a class of Executor. The scheduler starts by:
airflow scheduler- Step 3: You can also access Airflow web UI on http://localhost:8080.
- Step 4: You can now see some files in the $AIRFLOW_HOME directory. There are some important configuration options in $AIRFLOW_HOME/airflow.cfg that you should be aware of and change the default value. For this, you can open airflow.cfg in your preferred editor, such as vim.
- 1) dags_folder accepts a dir (directory) to be watched on a regular basis by Airflow in order to build DAGs.
- 2) executor determines the level of parallelization of running tasks or dags. It is a very important variable. The following values are acceptable for this option:
- SequentialExecutor is an executor class that only runs one task at a time and also runs locally.
- LocalExecutor is an executor class that uses the multiprocessing Python library and the queuing technique to execute tasks locally in parallel. (LocalExecutor is used because running parallel task instances is unavoidable, and you don’t need Airflow to be highly available at this point).
- CeleryExecutor, DaskExecutor, and KubernetesExecutor are classes that allow tasks to be run in a distributed fashion to improve availability.
- 3) sql_alchemy_conn in airflow.cfg determines the type of database that Airflow uses to interact with its metadata. It is yet another important variable in airflow.cfg. Because PostgreSQL was selected, the variable would be as follows:
sql_alchemy_conn = postgresql+psycopg2://aiflow_user:pass@192.168.10.10:5432/airflow_db- 4) parallelism specifies the maximum number of task instances that can run concurrently across DAGs.
- 5) dag_concurrency specifies how many task instances the scheduler is permitted to run per dag.
- 6) max_threads specifies the number of threads that the scheduler will use to schedule dags.
After making changes to the confs, you must restart the Webserver and Scheduler.
3) Building the DAG
In the process of scheduling Spark Airflow jobs, This section describes all the steps required to build the DAG which showcases the example.
To create a SparkSubmitOperator in Airflow, you need to do the following:
A) SPARK_HOME environment variable
You must set the spark binary dir environment variable in your operating system environment as follows (in Ubuntu):
export SPARK_HOME=/path_to_the_spark_home_dir
export PATH=$PATH:$SPARK_HOME/binB) Spark Connection
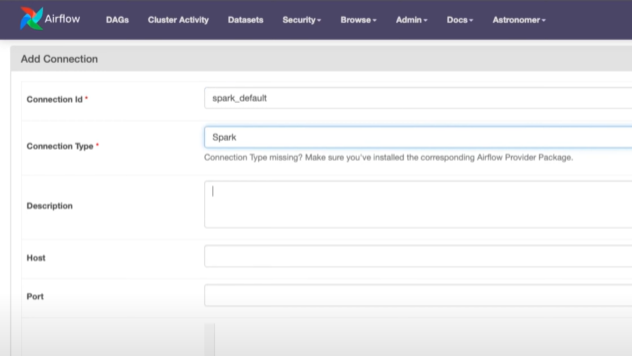
For establishing Spark connection in the process of scheduling Spark Airflow Jobs, the steps to be carried out are as follows:
- Step 1: Create Spark connection in Airflow web UI i.e., http://localhost:8080.
- Step 2: Navigate to the admin menu.
- Step 3: Select the “connections” option. Now, click on the “add+” option.
- Step 4: Select Spark as the connection type, enter a connection id, and enter the Spark master URL (i.e. local[*], or the cluster manager master’s URL) as well as the port of your Spark master or cluster manager if you have a Spark cluster.
C) Set Spark app home variable
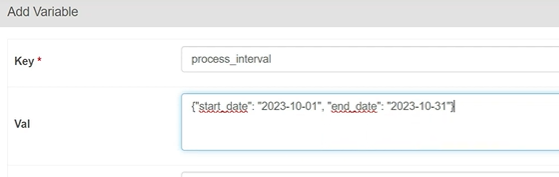
This step is extremely useful for creating a global variable in Airflow that can be used in any DAG.
The steps to be followed here in the process of scheduling Spark Airflow Jobs are as follows:
- Step 1: Define the PySpark app’s home dir an Airflow variable.
- Step 2: Navigate to the admin menu.
- Step 3: Now, select the variable and define it as shown in the diagram below:
D) Building DAG
The steps followed to create a DAG file in Airflow named flight_search_dag.py in the process of scheduling Spark Airflow Jobs are as follows:
I) Imports
You need to import various modules and classes as in the case of any Python application.
from datetime import datetime, timedelta
import pendulum
from airflow import DAG
from airflow.contrib.operators.spark_submit_operator import SparkSubmitOperator
from airflow.models import VariableII) default_args
This will be a dictionary for configuring the default configuration of the DAG, which will be nearly identical for all DAGs.
local_tz = pendulum.timezone("Asia/Tehran")
default_args = {
'owner': 'mahdyne',
'depends_on_past': False,
'start_date': datetime(2020, 10, 10, tzinfo=local_tz),
'email': ['nematpour.ma@gmail.com'],
'email_on_failure': True,
'email_on_retry': True,
'retries': 2,
'retry_delay': timedelta(minutes=5)
}III) dag
This will be an object created with the DAG class.
dag = DAG(dag_id='flight_search_dag',
default_args=default_args,
catchup=False,
schedule_interval="0 * * * *")- catchup=False: It means that you don’t need Airflow to complete the undone past executions since the start_date.
- schedule_interval=”0 * * * *”: This attribute accepts contab-style scheduling patterns.
IV) pyspark_app_home
This variable is set to keep the PySpark app dir, as defined earlier in the UI by Airflow Variable:
pyspark_app_home=Variable.get("PYSPARK_APP_HOME")V) SparkSubmitOperator
Using this operator, you can run a Spark app in a DAG.
flight_search_ingestion= SparkSubmitOperator(task_id='flight_search_ingestion',
conn_id='spark_local',
application=f'{pyspark_app_home}/spark/search_event_ingestor.py',
total_executor_cores=4,
packages="io.delta:delta-core_2.12:0.7.0,org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.0",
executor_cores=2,
executor_memory='5g',
driver_memory='5g',
name='flight_search_ingestion',
execution_timeout=timedelta(minutes=10),
dag=dag
)- The SparkSubmitOperator class includes useful attributes that eliminate the need for a separate bash script and the use of a BashOperator to call it.
- The conn_id attribute takes the name of the Spark connection that was created in the Spark Connection step.
- You can pass the PySpark app Python file path to the application attribute, as well as the dependencies using packages in a comma-separated format.
- You would pass the fat jar file to the application attribute and the main class to the jar_class attribute.
VI) Dependencies
After instantiating other tasks, you can define the dependencies.
flight_search_ingestion>>[flight_search_waiting_time,flight_nb_search]Airflow is overloading the binary right shift >> operator to define the dependencies, indicating that flight_search_ingestion task should be executed successfully first, followed by two tasks flight_search_waiting_time, flight_nb_search, which both depend on the first task flight search ingestion but do not depend on each other.
Now, you have a DAG that includes three Spark Airflow jobs that run once an hour. You will receive an email if anything goes wrong.
Conclusion
In this article, you have learned about Spark Airflow Jobs. This article also provided information on Apache Airflow, Apache Spark, their key features, DAGs, Operators, Dependencies, and the steps for scheduling Spark Airflow Jobs in detail. For further information on Airflow ETL, Airflow Databricks Integration, Airflow REST API, you can visit the following links.
Hevo Data, a No-code Data Pipeline provides you with a consistent and reliable solution to manage data transfer between a variety of sources and a wide variety of Desired Destinations with a few clicks.
Hevo Data with its strong integration with 150+ data sources (including 60+ Free Sources) allows you to not only export data from your desired data sources & load it to the destination of your choice but also transform & enrich your data to make it analysis-ready. Hevo also allows integrating data from non-native sources using Hevo’s in-built Webhooks Connector. You can then focus on your key business needs and perform insightful analysis using BI tools.
Want to give Hevo a try?
Try Hevo’s 14-day free trial and experience the feature-rich Hevo suite first hand. You may also have a look at the amazing price, which will assist you in selecting the best plan for your requirements.
Share your experience of understanding the scheduling of Spark Airflow Jobs in the comment section below! We would love to hear your thoughts about Spark Airflow Jobs.
FAQs
1. How to integrate Airflow with Spark?
Use Airflow’s SparkSubmitOperator to submit Spark jobs to a Spark cluster directly from Airflow. Configure Spark connections and parameters in Airflow’s configuration file or within the operator settings for efficient management of Spark tasks.
2. What is the difference between Spark and Airflow?
Spark is a data processing engine designed for batch and real-time processing. Airflow, on the other hand, is a workflow orchestration tool, primarily for scheduling and managing complex workflows, including those involving Spark jobs.
3. How many DAGs can Airflow handle?
Airflow can handle hundreds of DAGs efficiently, though performance depends on resources like memory and CPU, along with DAG complexity and task concurrency. Scaling with additional workers and database tuning helps manage larger numbers of DAGs effectively.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




