



Snowflake is a leading cloud data warehousing solution many Fortune 500 companies use. While it offers powerful data management capabilities, understanding its pricing can be complex. This article breaks down the key aspects of Snowflake pricing, focusing on the costs related to data storage and computational resources.
It also explores Snowflake’s pricing plans, guiding you in selecting the most cost-effective option based on business needs. By understanding these pricing factors, organizations can optimize their Snowflake usage for performance and cost efficiency.
Table of Contents
What is Snowflake?
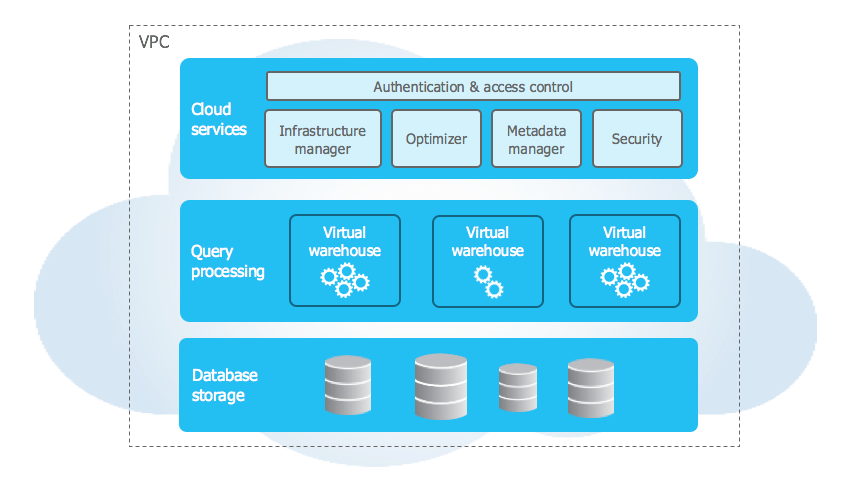
Snowflake provides a scalable Cloud-based platform for enterprises and developers and supports advanced data analytics. Multiple data stores are available, but Snowflake’s architectural and data-sharing capabilities are unique.
Key Features of Snowflake
- Snowflake’s architecture enables storage and computing to scale independently, so customers can use it separately and pay for it.
- The best property of Snowflake is that it provides separate storage and calculation options for data.
- Snowflake ensures that users do not require minimal effort or interaction to perform performance or maintenance-related activities.
- The minimum and maximum group size and scaling occur automatically at a very high speed in this area.
Hevo Data’s No-Code Data Pipeline makes transferring data to Snowflake seamless and efficient, allowing you to integrate data from diverse sources, including databases, SaaS applications, cloud storage, and streaming services.
Why Hevo is Perfect for Snowflake Integration
- Secure Data Transfer: Hevo’s robust architecture guarantees secure data handling with no data loss while streaming data into Snowflake.
- Automatic Schema Management: It simplifies schema mapping by automatically detecting the data’s structure and aligning it with Snowflake’s schema.
- Scalability: Hevo easily scales to handle increasing data volumes, allowing Snowflake to process millions of records per minute with minimal latency.
- Incremental Data Loading: The platform ensures efficient data transfer by only loading modified data into Snowflake, optimizing both speed and resource usage.
Experience Hevo’s Seamless Integration with Snowflake!
Get Started with Hevo for FreeHevo Data’s no-code data pipeline makes transferring data to Snowflake seamless and efficient, allowing you to integrate data from diverse sources, including databases, SaaS applications, cloud storage, and streaming services.
Snowflake Costs With Cost Intelligence Factor
Snowflake pricing depends on how the user is utilizing the following services:
- Compute Resources
- Virtual Warehouse Compute
- Serverless Compute
- Cloud Services Compute
- Storage Resources
- Data Transfer Resources
Compute Resources
Using compute resources within Snowflake consumes Snowflake credits. The billed cost of using compute resources is calculated by multiplying the number of consumed credits by the price of a credit. For the current credit price, see the Snowflake pricing guide.
There are three types of compute resources that consume credits within Snowflake:
1. Virtual Warehouses
These are a set of servers called a compute cluster that can carry out operations like query execution and data loading. Snowflake offers the following set of computing clusters, categorized by their sizes (the number of servers in the cluster):
| Type | # of servers |
| X-Small | 1 |
| Small | 2 |
| Medium | 4 |
| Large | 8 |
| X-Large | 16 |
| 2X-Large | 32 |
| 3X-Large | 64 |
| 4X-Large | 128 |
The usage activity for these servers is tracked and converted to what is known as Snowflake credits. Hence, to avail of these warehouse-related services, one has to purchase a bunch of credits that can then be used to keep the servers operational and utilize the services described in the upcoming sections – data storage and cloud services. There are two different ways to purchase credits; this will be covered in a later section.
Regarding virtual warehouses, the cluster size is directly related to the usage credits. For example – the size 2 cluster requires 0.0006 credits per second (or two credits per hour), and the size 32 cluster requires 0.0089 credits per second (or 32 credits per hour). Billing is done at the second level. Hence, a warehouse operational for 37 minutes and 12 seconds is only billed for those 37.12 minutes.
| Did You Know? Warehouses are only billed for credit usage while running. When a warehouse is suspended, it does not use any credits. |
The warehouse activity can be monitored in a couple of ways:
- Using the web interface: Account -> Billing & Usage
- Using the SQL table function WAREHOUSE_METERING_HISTORY
2: Data Storage
Serverless credit usage results from features relying on compute resources provided by Snowflake rather than user-managed virtual warehouses. Snowflake automatically resizes and scales these compute resources up or down as required for each workload.
Charges for serverless features are calculated based on the total usage of snowflake-managed compute resources, measured in computing hours. Compute hours are calculated per second and rounded to the nearest whole second. The number of credits consumed per compute hour varies depending on the serverless feature.
For serverless features, Snowflake-managed computing is billed at the rate of one credit per compute hour, multiplied by the applicable feature multiplier.
3: Cloud Services
These are a set of administrative services to ensure the smooth handling and coordination of a bunch of Snowflake tasks. These tasks include:
- Authentication
- Infrastructure management
- Metadata management
- Query parsing and optimization
- Access control
Cloud services require a certain amount of computing and consume some credits for their operations. However, 10% of the actual compute (compute from the warehouse operations) is discounted from the daily compute credits used by the cloud services. So, for instance, if the compute from the operational clusters = 100 credits and cloud services compute = 15, then the final compute of cloud services for that day = 15 – (10% of 100) = 5.
Cloud services are generally not monitored for optimizing usage as much as they are done with data storage and virtual data warehouses. However, Snowflake provides for a couple of methods to do the same :
- Query History
- Warehouse History
1) Query History
To understand the specific queries (by their type) that are consuming cloud service credits, the following SQL can be used –
select
query_type,
sum(credits_used_cloud_services) as cloud_services_credits
from snowflake.account_usage.query_history
where
start_time >= '2020-01-01 00:00:01'
group by 1;2) Warehouse History
To find out the virtual warehouses that use up cloud service credits, the following query can be used –
select warehouse_name, sum(credits_used_cloud_services) credits_used_cloud_services, sum(credits_used_compute) credits_used_compute, sum(credits_used) credits_used from snowflake.account_usage.warehouse_metering_history where start_time >= ‘2020-01-01 00:00:01’ group by 1;Storage Resources
The monthly cost for storing data in Snowflake is based on a flat rate per terabyte (TB). For the current rate, which varies depending on your type of account (Capacity or On Demand) and region (US or EU), see the Snowflake Pricing Guide.
Storage is calculated monthly based on the average number of on-disk bytes stored daily in your Snowflake account. Storage cost represents the cost of:
- Files staged for bulk data loading/unloading (stored compressed or uncompressed).
- Database tables, including historical data for Time Travel.
- Fail-safe for database tables.
- Clones of database tables that reference data deleted in the table that owns the clones.
Data Transfer Resources
Snowflake does not charge data ingress fees to bring data into your account but does charge for data egress.
Snowflake charges a per-byte fee when you transfer data from a Snowflake account into a different region on the same or completely different cloud platform. This per-byte fee for data egress depends on the region where your Snowflake account is hosted. The actions that incur data transfer costs are:
- Unloading Data: Transferring data to cloud storage in a different region or platform using COPY INTO <location>, with associated stage costs.
- Replicating Data: Replicating databases to another Snowflake account in a different region or platform, incurring extra charges.
- External Network Access: Accessing external network locations through procedures or UDF handlers.
- Writing External Functions: Transferring data via external functions to AWS, Azure, or Google Cloud.
- Cross-Cloud Auto-Fulfillment: Offering listings in other cloud regions via auto-fulfillment.
Understanding Overall Cost
The costs for Snowflake are mainly based on three components: compute, storage, and data transfer.
- Calculate Costs: Prices are based on the consumption in Snowflake credits, which are issued for running virtual warehouses, serverless features, and cloud services. Virtual warehouses charge per second, with a minimum of 60 seconds. Serverless features, such as Snowpipe, automatically scale up or down depending on demand. Only usage above 10% of the daily warehouse credits initiates extra cloud services layer charges.
- Storage Costs: These will be a per-month charge that leverages a fixed terabyte rate. The rate is dependent on the type of account and region. Overall, the amount is therefore considered based on an average daily amount of storage.
- Data Transfer Fees: Data ingress, meaning the importation of data into Snowflake, does not have a charge; however, any data egress or data export will have a charge per byte, depending on the destination region or cloud platform.
Check out our Snowflake Pricing Calculator to learn more about Snowflake’s pricing.
Snowflake Pricing Purchase Plans
Now that you have an idea as to how the costs are incurred based on the credits accrued depending on the usage of the different Snowflake services, this section talks about the options for choosing a pricing plan:
- On-Demand : This is similar to the pay-as-you-go pricing plans of other cloud providers, such as Amazon Web Services, where you only pay for what you consume. At the end of the month, a bill with the usage details for that month is generated. There is a $25 minimum for every month, and for data storage, the rates are typically set to $40 per TB.
- Pre-Purchased Capacity : With this option, a customer can purchase Snowflake resources in advance in a set amount or capacity. The significant advantage of this plan is that the packaged pre-purchase rates will be available at a lower price than the corresponding On-Demand option.
A popular way of going about the pricing strategy, especially when you are new and unsure about this, is to first opt for the On-demand and then switch to Pre-purchased. Once the On-Demand cycle starts, monitor the resource usage for a month or two, and once you have a good idea of your monthly data warehousing requirements, switch to a pre-purchased plan to optimize the recurring monthly charges.
Optimizing Snowflake Pricing
As pointed out in the previous sections, many things must be dealt with in terms of understanding the usage of different Snowflake resources and how that translates into costs.
Here are a few things to be kept in mind that will help optimize these incurred costs:
- Depending on your location, it is essential to choose the cloud region (like US East, US West, etc., depending on the cloud provider) wisely to minimize latency, access the required set of features, etc. If you move your data to a different region later on, data transfer costs are associated with it on a per-terabyte scale. So, the larger your data store, the more expenses you incur.
- It can make quite a difference to the costs incurred by optimally managing the operational status of your compute clusters. The features such as ‘auto suspension’ and ‘auto-resume’ should be used unless there is a better strategy to address this.
- The workload/data usage monitoring at an account level, warehouse level, database, or table level is necessary to ensure there aren’t unnecessary query operations or data storage contributing to the overall monthly costs.
- Make sure to compress the data as much as possible before storage. There are instances, such as storing database tables, where Snowflake automatically does a data compression. However, this is not always the case, so this is something to be mindful of and monitored regularly.
- Snowflake works better with the date or timestamp columns stored as such rather than storing them as type varchar.
- Try to make more use of transient tables as they are not maintained in the history tables, which, in turn, reduces the data storage costs.
Total Cost Calculation Example
Consider an organization that processes data continuously and has multiple departments (HR and Marketing) using the system at different times of the day. This organization runs monthly reports and stores substantial data for analysis. Here are the details:
- Snowflake Edition: Enterprise Edition
- Data Stored: 50 TB of compressed data (equivalent to 250 TB without compression)
- Data Loading: Runs 24×7 using a Medium Standard virtual warehouse
- HR Department: 10 users work 8 hours a day, 5 days a week, using a Medium Standard virtual warehouse.
- Marketing Department: 15 users in different time zones work 10 hours a day, 5 days a week, using a Large Standard virtual warehouse.
- Monthly Reports: A detailed report takes 3 hours to run on a 4X-Large standard warehouse every month.
Requirements:
| Parameter | Customer Requirement | Configuration | Cost |
| Loading Window | 24 x 7 x 365 | Medium Standard Virtual Warehouse (4 credits/hr) | 2,880 credits (4 credits/hr x 24 hours per day x 30 days per month) |
| Data Set Size (per month) | 50 TB (after compression) | – | Storage Cost: $1,150 ($23/TB x 50 TB) |
| HR Users | 10 Users, 8 hours/day (5 days/week) | Medium Standard Virtual Warehouse (4 credits/hr) | 1,600 credits (4 credits/hr x 8 hours/day x 20 days/month) |
| Marketing Users | 15 Users, 10 hours/day (5 days/week) | Large Standard Virtual Warehouse (8 credits/hr) | 4,000 credits (8 credits/hr x 10 hours/day x 20 days/month) |
| Monthly Reports | 1 User, 3 hours/month | 4X-Large Standard Virtual Warehouse (64 credits/hr) | 192 credits (64 credits/hr x 3 hours/month) |
Total Cost Incurred
| Usage Type | Monthly Cost | Total Billed Cost |
| Compute Cost | 7,792 credits (@ $2/credit) | $15,584 |
| Storage Cost | 50 TB (@ $23/TB) | $1,150 |
| Total Monthly Cost | – | $16,734 |
This example illustrates how Snowflake’s compute and storage costs accumulate based on user activity, data storage, and report generation. Leverage the power of a universal semantic layer to break down silos and enable seamless integration for data analytics and decision-making.
Conclusion
The article introduced you to Snowflake and explained in detail the factors on which Snowflake Pricing depends. Moreover, it discussed the various Snowflake Pricing models and how you can optimize them cost-effectively. You can have a good working knowledge of Snowflake by understanding Snowflake Create Table.
Sign Up for a 14-day free trial and experience the feature-rich Hevo suite first hand.
What are your thoughts on Snowflake Pricing? Let us know in the comments.w in the comments.
FAQs
1. How much does Snowflake really cost?
Snowflake’s cost varies based on compute, storage, and data transfer fees. Compute is charged based on credits used, while storage is billed at a fixed rate per terabyte per month. Data transfer fees apply for data exported to other regions or cloud platforms.
2. What is Snowflake price?
Snowflake pricing includes credit-based compute costs and fixed-rate storage fees. The exact prices depend on the chosen plan (Standard, Enterprise, etc.) and your region.
3. How does pricing work in Snowflake?
Snowflake’s pricing model is pay-as-you-go, charging for compute by credits used, storage by average monthly data size, and data transfer when moving data out of Snowflake. This structure allows flexible scaling based on your needs.
Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



