



Databricks is a platform that provides powerful analytics and flexibility, making it a top choice for data-driven teams. But as data needs grow more complex, exploring alternatives and finding tools that may be an even better fit would make more sense. Databricks competitors offer unique features that can cater to your specific tasks or workflows.
This guide will walk you through some of the top Databricks alternatives and use cases for each platform, along with their pros and cons, helping you choose the right platform for your data strategy.
Table of Contents
Overview of Databricks

Databricks is an open analytics platform for analyzing and maintaining data. It provides analytics tools and services, ranging from data ingestion to deployment of machine learning models. Databricks seamlessly combines elements of the best data lakes and warehouses to perform effective data analysis.
A fully managed No-code Data Pipeline platform like Hevo Data helps you integrate and load data from 150+ different sources (including 60+ free sources) to Data Warehouses such as Databricks, Snowflake, BigQuery, Redshift, or Destination of your choice in real-time in an effortless manner. Ensure seamless data migration using features like:
- Seamless integration with your desired data warehouse, such as Databricks.
- Transform and map data easily with drag-and-drop features.
- Real-time data migration to leverage AI/ML features of your data warehouse.
Still not sure? See how Postman, the world’s leading API platform, used Hevo to save 30-40 hours of developer efforts monthly and found a one-stop solution for all its data integration needs.
Get Started with Hevo for FreeKey Features of Databricks
- Scalability: Databricks provide high scalability with auto-scaling features, where the system will automatically adjust to accommodate the increased load.
- Optimized Performance: This platform is optimized for advanced querying, processing millions of records within a few seconds. This helps you receive your data analysis results in no time.
- Real-time Data Processing: Using Databricks Runtime is one of the best ways of processing real-time data from multiple sources by using Apache Spark Streaming.
Check out how Databricks works in detail to get a deeper understanding of how this platform works
Top 10 Databricks Alternatives List
Let’s explore some of the most popular Databricks alternatives, their key features, pros and cons, pricing options, and how each of these options compares with Databricks.
1. Snowflake

Snowflake is the first Cloud Data Warehouse solution in the world, based on the infrastructure of the customer’s choice of Cloud Provider (AWS, Azure, or GCP). The IDE used by Snowflake is fully web-based. Visit XXXXXXXX.us-east-1.snowflakecomputing.com. Once you log in, you will be automatically taken to the main Online GUI, which acts as an IDE, which is an IDE for you to start interacting with your Data Assets.
Refer to the official website of Snowflake for more detailed information about how this platform works.
Pros
- SQL Support: Snowflake wants its users to easily access and manipulate data; it offers SQL language support, including DDL, DML, and the most complex commands.
- Data Import and Export: It supports bulk import and export of data, including character encoding, compressed files, delimited data files, etc.
- Integrations: Snowflake easily integrates with many third-party apps and services that companies use. This service makes it easy for users to synchronize the data of the platform and Snowflake.
- Semi-Structured Data Support: Using the VARIANT schema on the Read data type, Snowflake’s architecture supports Structured and Semi-Structured data in one location. VARIANT supports storage for both structured and semi-structured data storage. Once loaded, Snowflake will automatically parse the data, extract the attributes, and store it in Columnar Format.
Still confused about moving to Snowflake? Get a better understanding of Snowflake by observing how the platform works and some of its major features.
Cons
- Substantially Higher Cost for Extremely High Compute Loads: This will rapidly become expensive if you have high compute requirements, as Snowflake will charge both for compute and storage independently.
- Fewer Features for Advanced ML Use Cases: Snowflake is also relatively less strong in machine learning compared to Databricks. Teams with a very intense focus on data science might find that it limits their capabilities.
Use Cases
- Best for Data Warehousing: Suitable for organizations whose focus lies in data warehousing with large amounts of data and who need high performance and scalability.
- Data Integration Needs: Excellent for you if you have a seamless integration need from a variety of sources and cloud providers.
- Business Intelligence: Best suited for organizations who focus on BI and analytics rather than deep analytics or machine learning.
Pricing
Snowflake charges a monthly fee for your data stored in the platform. The charge is computed as an average storage used monthly, after compression, for the data ingested into your Snowflake warehouse.
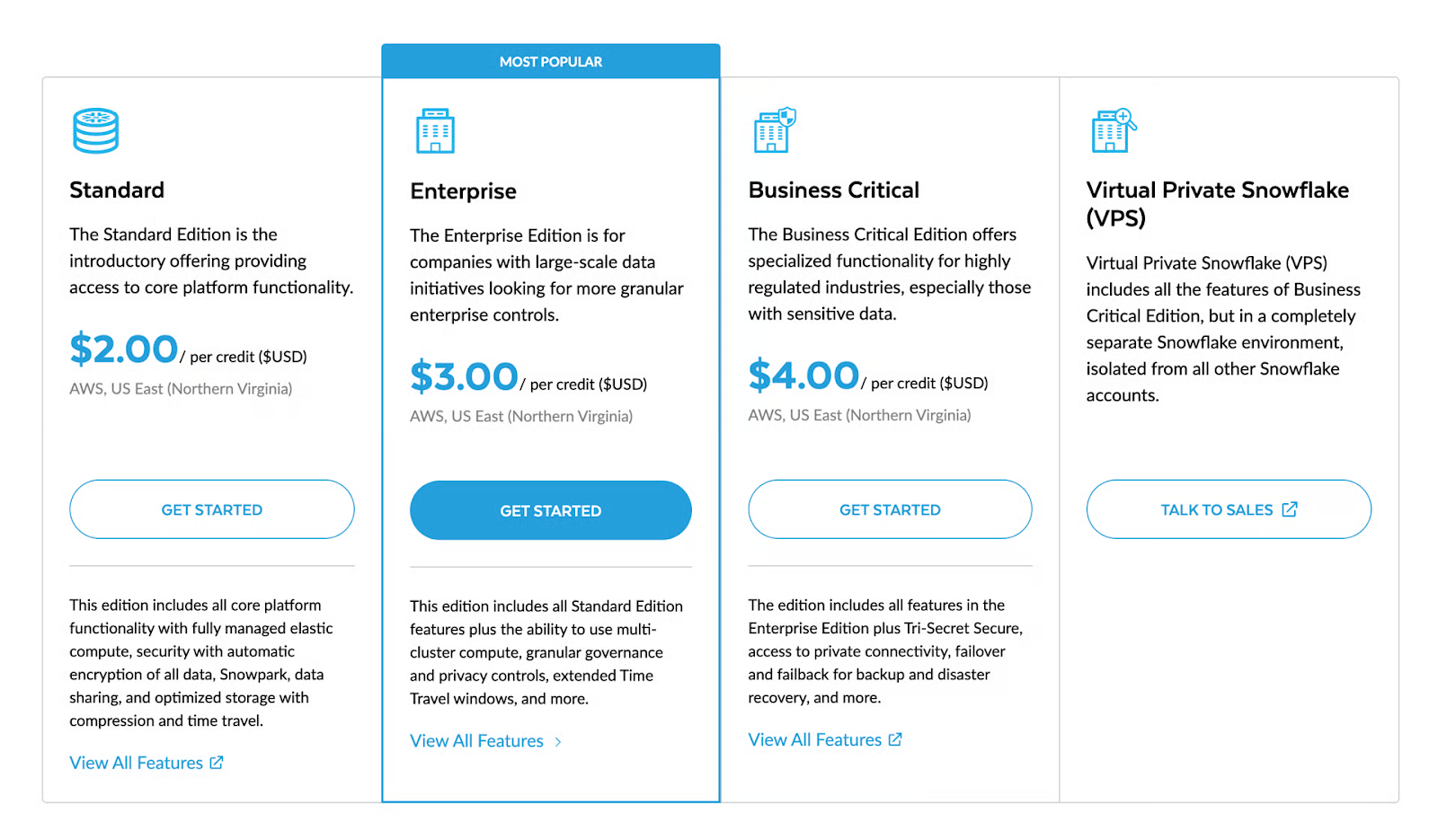
Refer to the official Snowflake website for detailed pricing plans.
2. BigQuery

Google BigQuery is a Cloud Datawarehouse developed by Google. It can be used to analyze terabytes of data in seconds. If you know how to write SQL Queries, you already know how to query it. In fact, there are plenty of interesting public data sets shared in BigQuery that are ready to be queried by you.
BigQuery can be accessed either by using the GCP console or the classic web UI, by using a command-line tool, or by making calls to BigQuery Rest API using a variety of Client Libraries such as Java, .Net, or Python.
Visit the official BigQuery website to understand how the platform functions.
Pros
- Ease of Implementation: Creating your own is costlier, time-consuming, and difficult to scale. With BigQuery, you upload your data up front, and pay only for what you consume.
- Speed: Process billions of rows in seconds and manage the real-time analysis of the Streaming data.
- Real-Time Analytics: Google BigQuery offers real-time analytics on a high-speed streaming insertion API. The user just has to include the real-time data, and Google BigQuery will analyze it at once.
- Automatic Backup and Restore: Google BigQuery enables users to enable auto Backup and Restore. It tracks the changes made over a period of 7 days such that it can be compared with the previous versions if needed, and any changed elements can be recalled in that respect.
Also, check out in detail how BigQuery functions to get a clear understanding of how you can use this destination as your alternative.
Cons
- Complex Pricing Structure: The pricing model is based on data processed, and one can be taken aback by surprise costs that are not too vigilantly kept under control.
- Limited Data Science Tools: It does not offer much more comprehensive support to advanced ML and custom data science compared with Databricks.
Use Cases
- Best for Real-Time Data Analytics: This is most suited for companies that need very quick querying and reporting over large volumes of data.
- Google Cloud Users: Most suited for users who rely much on Google’s overall ecosystem as it can be easily integrated with other tools within Google Cloud.
- Cost-Conscious Workloads: Suitable for users who want flexible, scalable querying without heavy upfront costs or infrastructure management.
Pricing
BigQuery pricing falls into two primary categories:
- Compute pricing: Cost in terms of processing queries in BigQuery SQL, User-Defined Functions, Scripts, etc.
- Storage pricing: cost in terms of the amount of storage of the data you will be loading into Bigquery.
BigQuery has other types of charges too, which include BigQuery Omni, BigQuery ML, BI Engine, as well as streaming reads and writes. BigQuery also has free operations; it comes with a free usage tier and free operations.
You may check out the prices in detail from the BigQuery official website.



3. Alteryx

Alteryx is an end-to-end data analytics and visualization software that helps businesses access, process, analyze, report, and present large and complex datasets from multiple sources. The application can clean, transform, and analyze big data from different sources without requiring any coding or programming skills.
Want to know more about how this platform works? Visit the Alteryx official website.
Pros
- User-Friendly, No-Code Interface: Drag-and-drop Workflow Designer allows data preparation, blending, and analysis with just the most basic form of information and technology skills.
- Extensive Data Preparation: The capabilities of Alteryx towards data cleansing, transformation, and blending from multiple sources are very strong, thus ideal for users with a data prep-centric approach.
- Advanced Analytics and Machine Learning: Built-in functionalities such as statistical analysis and predictive modeling without necessarily requiring deep coding.
- Broad Integration: Integrates smoothly with different types of databases, data lakes, and third-party tools, allowing flexible data integration.
Cons
- Licensing Cost is High: Alteryx can be costly, especially for small business teams or teams with limited budgets.
- Not Scalable with Big Data: Alteryx will be powerful with smaller or medium-sized datasets. Alteryx is not designed for massive scale such as Databricks and BigQuery.
Use Cases
- Best for Data Preparation and Transformation: Alteryx is perfect for data preparation and transformation where most teams want an efficient process of data preparation, blending, and cleaning.
- Analysts using No-Code Tools: This is suitable for analysts who prefer no-code or low code since they’re usually performing analyses they do not have intensive coding skills.
- Companies with Small to Medium Data: Suitable for companies dealing with moderate data volumes as it is not optimized for big data.
Pricing
Alteryx has two editions and a pricing plan for each version.
- Designer Cloud, priced at $4,950 USD
- Designer Desktop, priced at $5,195 USD
You can find the detailed pricing plans from the official Alteryx website.
4. Amazon Redshift

Redshift is a part of Amazon Web Service, a cloud-based data warehouse service developed by Amazon to handle huge data and allows you to discover new insights from them. Its operations allow you to query and combine exabytes of structured and semi-structured data across different Data Warehouses, Operational Databases, and Data Lakes.
To get detailed information of how the platform works, visit the official site of Amazon Redshift.
Pros
- Redshift is built on industry-standard SQL, with functionalities to manage huge datasets, support high-performance analysis, provides reports, and large scaled database migration.
- Redshift also lets you save your queried result to your S3 data lake using open formats like Apache Parquet from which additional analysis can be done on your data from other Amazon Web Services such as EMR, Athena, and SageMaker.
You can take a look in detail at the Amazon Redshift Architecture to get a better understanding of this platform.
Cons
- Pricing can get steep if you are running high workloads continuously, as storage and compute are charged differently.
- Not as flexible in dealing with unstructured data compared to other platforms like Databricks, which may be a limitation for some projects.
- Built-in machine learning features are limited which can be a constraint in case you are looking for full-on strength in data science functionality.
Use Cases
- Best suited for businesses who are seeking a data warehouse managing heavy analytics, and integrates effortlessly within AWS.
- Ideal if you want a simple scale-out for increasing data loads without much overhead.
- The best solution for analytic workloads on structured data if you are much more interested in BI and not much into data science-intensive applications.
Pricing
Amazon Redshift pricing starts at $0.25 per hour, depending on usage and based on petabytes of data and thousands of concurrent users.
You can check the pricing details in detail from the official Redshift website.
5. Teradata Vantage

Teradata Vantage is a multi-cloud data platform designed for enterprise analytics. It aims to help users address all data challenges from the initial stage to full-scale deployments. Using this platform, organizations worldwide across industries can reach business goals through a modern open ecosystem.
To get additional information about the working of the platform, visit the official website of Teradata.
Pros
- Can handle big data analytics in high performance, hence being a good solution for enterprise companies dealing with large data sets.
- It supports the multi-cloud environment, which means it can be deployed on all three platforms such as AWS, Google Cloud, and Azure. Businesses requiring a connected, cloud-agnostic platform will benefit from it.
- For all their structured requirements, it offers well-honed data management and integration capabilities, allowing users to integrate various sources of data for holistic insights.
- Advanced analytics tools enable complex data processing and analysis that prove to be important for industries seeking deep, granular insights.
Cons
- It can be costly as it is targeted at enterprise-level data processing, especially for small businesses or those with limited budgets.
- May require technical know-how on how to best utilize its advanced analytics features. It may challenge teams who lack in-house data specialists.
- Not as instinctively easy-to-use an interface as more user-friendly platforms, and may take some time to get new users up to speed.
Use Cases
- Best for big enterprise-oriented deployments requiring deep analytics from humongous amounts of data spread across multiple cloud environments.
- Ideal for organizations looking for advanced capability in managing data and integration with various cloud providers.
- Useful for industries requiring deep analytics of complex natures to deliver business outcomes, such as finance, telecom, and healthcare.
Pricing
Teradata Vantage offers two plans:
- VantageCloud Lake – starting at $4800/month
- VantageCloud Enterprise – starting at $9000/month.
You can check the official Teradata website for all the detailed pricing plans.
6. Qubole

Qubole is a secure and accessible data lake platform designed for machine learning, streaming, and ad-hoc analytics. Its whole set of services makes it easier to run data pipelines, streaming analytics, and machine learning jobs across any cloud environment. Open architecture and flexibility in support of diverse data workloads have enabled Qubole to differentiate itself with very substantial savings on cloud data lakes.
Visit the Qubole official website for detailed information on the way the platform works.
Pros
- It simplifies big data management making it possible to efficiently carry out data pipeline workloads, streaming analytics, and machine learning without hassle prior setups.
- It supports operations across multiple cloud environments; meaning you are not tied to a single provider, giving greater flexibility.
- Its cost-efficiency in handling data lake management often cuts expenses by as much as 50% which can be helpful for budget-conscious teams.
- Open architecture allows for various data processing tools and frameworks, therefore adapting to any kind of data needs.
Cons
- Limited in advanced capabilities related to data science compared with Databricks, therefore maybe a limitation for those teams that require many features from machine learning.
- The interface, as well as the configuration, are pretty overwhelming and quite intimidating, especially for some data lake beginners.
- It may not be capable of handling large scale complex workloads like that of dedicated data warehouses.
Use Cases
- It is good for teams seeking an efficient, versatile data lake solution for analytics, machine learning, and stream intake on cloud providers.
- It is ideal when you are searching for an open platform that integrates well with a range of tools and does not lock you into one cloud environment.
- Suitable for companies who are focused on data processing and analytics rather than advanced data science tasks, especially where saving on budgets is of priority.
Pricing
The pricing plans provided by Qubole can be seen in the below image.
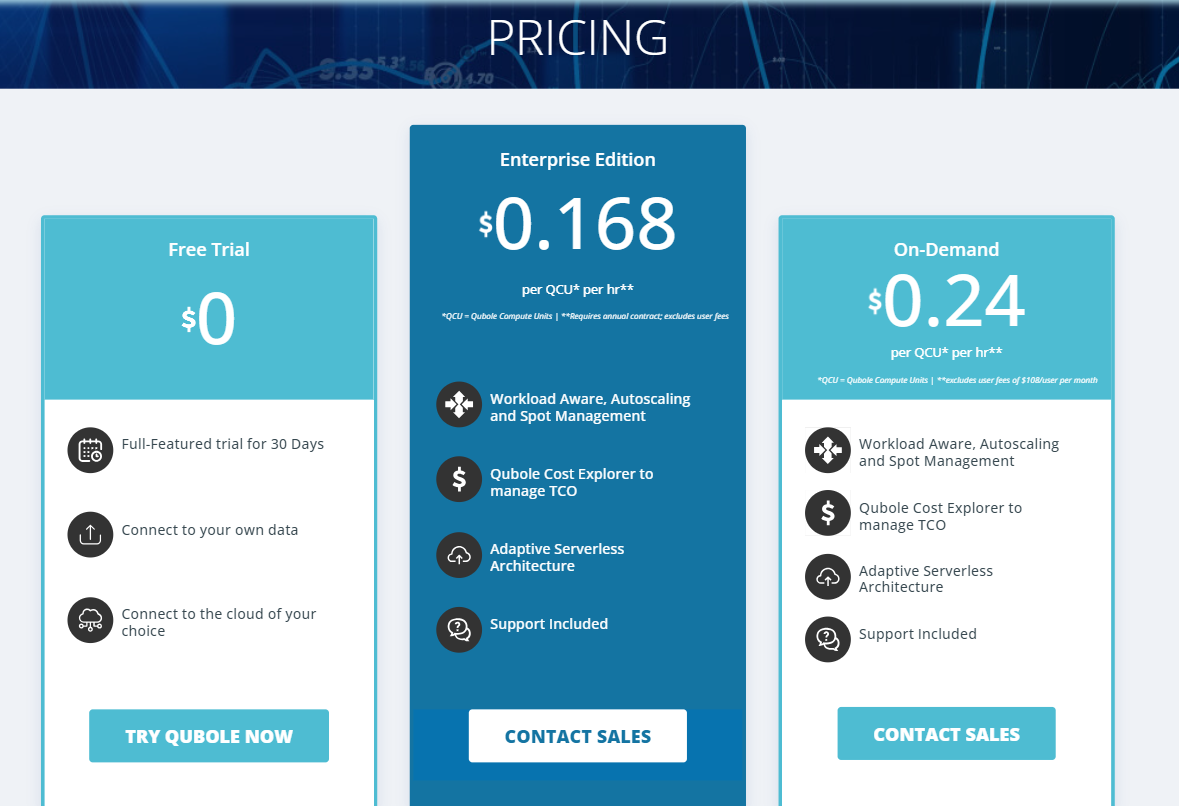
You could also check the official Qubole website to get a detailed view of the pricing plans.
7. Cloudera

Cloudera is an open, secure data platform designed for data engineering, machine learning, and analytics at scale. It provides a whole set of tools to simplify data management and processing so that complex data tasks can be addressed by organizations in hybrid and multi-cloud environments. With its flexible architecture, it allows users to have diverse data workloads under one roof while providing them with high performance and cost optimization.
To learn more about the platform, go to Cloudera’s official website.
Pros
- Highly versatile and adaptable for all hybrid and multi-cloud environments, allowing you to manage data across on-premises, private, and public clouds.
- Strongly oriented towards strict compliance in data security and governance. This would be most suitable for very rigorous industries in terms of compliance.
- Supports a wide range of data processing, analytics, and machine learning tools, and thus having an all-in-one solution for data management.
- Scalable design to support the ever-increasing volumes of data and complex workloads of your business
Cons
- Installation and management might require an expert team, which can be challenging for smaller businesses.
- Installation and running costs are quite higher than other alternatives, especially on relatively small projects.
- Interface may be perceived as tough and laborious to learn for teams less experienced in managing data.
Use Cases
- Best for large organizations that require robust data protection, governance, and flexibility in hybrid and multi-cloud environments.
- Best for companies that require comprehensive data management involving data engineering, machine learning, and analytics at scale.
- An excellent solution for businesses in highly regulated industries, such as finance and healthcare, where privacy and data compliance come at the top of the list.
Pricing
Cloudera offers flexible pricing plans, oriented toward flexibility in cloud, hybrid, and on-premises deployments. Its plans let you pay by the workload need or resource usage. Custom pricing structures also exist, emphasizing enterprise scalability, security, and support for multi-cloud and on-premises data management.
You can check pricing plans in a detailed structure on the official Cloudera website.
8. Azure Synapse Analytics

Azure Synapse is a unified analytics service that has data integration, data warehousing, and data analytics capabilities. For integration purposes, Azure Synapse provides more than 95 native connectors through which you can collect information from different sources. Once you have collected the information, you can transform it and store it afterwards in a data warehouse. You can eventually use Azure Synapse for analysis and visualization.
Visit the Azure Synapse official website to know all about how it functions.
Pros
- Due to its numerous features to supervise end-to-end big data workflow, Synapse has gained immense popularity these days amongst analytics professionals.
- Its capability of storing unstructured data in the form of a data lake makes it all the more powerful. Synapse also supports analyst-friendly languages such as T-SQL, Python, Scala, Spark SQL, and .Net.
Not sure whether to select Azure Synapse or Snowflake? Check out the key differences between Azure Synapse Analytics and Snowflake.
Cons
- Pricing can become unpredictable, especially for large datasets or complex queries, as it charges based on resource usage.
- The user interface might feel complicated for beginners, requiring a learning curve to fully utilize the platform’s capabilities.
- While powerful for data analytics, it may not provide as specialized machine learning features as Databricks.
Use Cases
- Best for businesses already integrated into the Azure ecosystem, as it connects well with other Azure services.
- Ideally suited for organizations that need an all-in-one platform to control big data as well as data warehousing analytics
- Ideal for big teams operating in large analytics projects where they are in dire need of quicker insights and the availability of scalable resources.
Pricing
Azure Synapse has pay-as-you-go prices when you pre-purchase Azure Synapse Analytics Commit Units that may be consumed in any publicly available product in Azure Synapse except storage during the following 12 months. Your consumption of Azure Synapse will be charged to your pre-purchased SCUs at the retail price of the individual product until they are exhausted or till the end of 12 months.
You can find the pricing tiers on the Azure Synapse Analytics website in full detail.


9. Apache Spark
Apache Spark is a versatile, multi-language engine that is used for data engineering, as well as data science and machine learning tasks, whether on a single node or across a cluster. It is powered by a sophisticated distributed SQL engine to gain efficient processing of large-scale data.
Visit the Apache Spark official website to learn more about the platform
Pros
- Scalable and fast, hence it can handle large data in real-time or batch processing.
- Broad Language Support: Apache Apex supports Java, Python, Scala, and R.
- Very extensively integrated with many data sources and tools and, therefore, versatile to suit diverse data workloads.
- It is open-source, meaning anyone can customize and even self-develop with the participation of the community.
Cons
- Needs technical know-how of a high order to set up and operate, especially for large-scale clusters.
- Optimization might prove tricky to accomplish especially for extremely large data sets or complex queries.
- Fewer analytics features are natively integrated within the platform compared to dedicated platforms like Databricks. In such cases, additional setup might be needed.
Use Cases
- Great for Big Data Processing and Analytics – especially for applications where real time streams or batch jobs are omnipresent.
- Suitable for teams already well-versed in the Spark ecosystem who need an open-source version of Databricks.
- This applies to data engineers and scientists who need flexibility in handling diversified data sources and large datasets.
Learn how you can easily build a Spark Data Pipeline for seamless data integration.
Databricks Leverages Apache Spark for Unified Analytics
Databricks is built on Apache Spark, extending its capabilities to offer a unified platform for big data analytics. It integrates powerful features such as collaborative notebooks, automated workflows, and optimized performance, making it easier for teams to manage large datasets. By using Spark under the hood, Databricks enhances its processing power while simplifying the management of Spark clusters. This enables data teams to efficiently handle data engineering, machine learning, and data science tasks in a collaborative and scalable environment.
10. Amazon Web Services (AWS)

Amazon Web Services (AWS) is one of the most adopted, highly integrated cloud-based platforms that provides a wide selection of services to manage data, applications, and workloads for businesses. It has flexible and scalable infrastructure so an organization can quite easily run applications, process big data, and use machine learning models across a wide network with ease.
To get detailed information of how the platform works, visit the official site of AWS.
Pros
- It provides a wide spectrum of cloud services from compute power to machine learning, making sure it is available for all types of business use.
- Scalable and flexible, scaling your resources up or down depending on your workload, so you only pay for what’s needed.
- Strong security and compliance features, which makes it well-suited for extreme data governance needs in many industries.
- Deep integration with other AWS services, driving seamless workflows and data management throughout the ecosystem.
Cons
- Pricing can be tricky and pretty unpredictable, especially as workloads scale, and it can really surprise you with extra costs.
- While powerful, it can also be very intimidating for a newcomer, and some services require a decent knowledge of cloud infrastructure.
- It doesn’t have all the specialized data science features and collaboration tools Databricks provides for teams working on machine learning.
Use Cases
- Its ideal for any organization already using AWS, or one building and scaling its infrastructure in the cloud.
- Appropriate for businesses that need a broad range of cloud services with the ability to scale up or down according to requirements.
- Suitable for teams requiring robust security, governance, and compliance capabilities across a spectrum of workloads.
Pricing
AWS gives you a pay-as-you-go approach to the pricing for most of its cloud services. You simply pay for the services you want, as long as you need them while using AWS.
Check out the full pricing options in more detail at the official Amazon Web Services website.
Databricks Competitors Compared in One Place: Pros, Cons, Use Cases, and Pricing
| Platform | Pros | Cons | Use Cases | Pricing |
| Databricks | High scalability, advanced ML & AI tools, flexible pricing | Requires technical expertise, complex UI | Data Science, ML, Big Data Processing | Usage-based, scalable pricing |
| Snowflake | High integration, scalable, web-based GUI | Higher costs for heavy workloads, limited ML tools | Data Warehousing, Business Intelligence | Based on storage and compute usage |
| BigQuery | Real-time analytics, high scalability, Google ecosystem | Complex pricing, limited import/export options | Real-time data analytics, Google Cloud users | Based on data processed and stored |
| Alteryx | Easy to use, no-code drag-and-drop interface | Expensive, no SQL support | Data Preparation, Transformation for Analysts | Starting at $4,950 USD for Designer Cloud |
| Amazon Redshift | Scalable, SQL-based interface, integrates with AWS | Expensive for heavy workloads, limited ML tools | Data Warehousing, Integration with AWS | Starts at $0.25/hour, varies by usage |
| Teradata Vantage | Highly scalable, advanced analytics tools | Expensive, requires technical expertise | Large enterprises with complex analytics | From $4800/month (VantageCloud Lake) |
| Qubole | Flexible formats, cost-effective, supports ML | Moderate scalability | Cost-effective data lake, machine learning | Usage-based, typically reduces costs by 50% |
| Cloudera | Highly scalable, advanced ML & analytics tools | Expensive for small teams, requires expertise | Large organizations needing robust data management | Custom pricing based on enterprise needs |
| Azure Synapse Analytics | Azure ecosystem integration, scalable | Unpredictable pricing for large data | Big data analytics, Azure ecosystem integration | Pay-as-you-go, based on usage and pre-purchase SCUs |
| Apache Spark | Open-source, highly scalable, advanced ML tools | Requires technical setup | Large-scale data processing, machine learning | Open-source, cloud providers charge for usage |
| AWS | Highly scalable, flexible pricing, streaming & batch | Complex pricing, requires expertise | General-purpose cloud services, data processing | Pay-as-you-go pricing, varies by service and usage |
Why Should You Explore Other Databricks Alternatives?
- Cost-Effectiveness: Alternatives may be more cost-effective in pricing, and this shall benefit businesses that are very minimalist in budget or dealing with smaller projects.
- Advanced Features: These alternatives may carry special features you may want to exploit, which may include high performance in machine learning, advanced data security, or flexibility to integrate with other tools within the system.
- Easy setup: For those who want an easier setup or a friendlier platform, some alternatives might be the simplest to configure or provide better support for non-technically inclined users.
- Better integration with tools you already use: Many alternatives integrate better into the tools and services your company already uses, saving time and effort on setup and management.
- Scalability Requirements: Depending on the need to scale up at later times, a few options may serve well to give more scalability, such as upgrading more fluidly to cope with larger workloads without performance degradation.
Also, take a look at the Snowflake open source alternatives to broaden your choices when selecting an alternative.
Conclusion
Exploring Databricks alternatives gives you multiple possibilities for your tailored solution of data processing, analytics, and machine learning systems. Be it Snowflake’s seamless data warehousing or the flexible and scalable cloud services offered by AWS, every platform has its unique attractions.
Whether you have an interest in real-time analytics, sophisticated ML tools, or the cost-effectiveness of scalability, you now have a choice that is suited to your needs. Understanding the pros and cons and use cases for each alternative will ensure the right choice for the needs of your data infrastructure.
Take Hevo’s 14-day free trial to experience a better way to manage your data pipelines. You can also check out the unbeatable pricing, which will help you choose the right plan for your business needs.
FAQ on Databricks Competitors
Q1) Who is Databricks’ biggest competitor?
Databricks’ biggest competitor is Snowflake. Both are cloud-based data platforms used for big data analytics, but Snowflake focuses more on data warehousing while Databricks is known for its unified analytics and machine learning capabilities.
Q2) What is the AWS equivalent of Databricks?
The AWS equivalent of Databricks is Amazon EMR (Elastic MapReduce). It provides a platform for big data processing and analytics, similar to Databricks, but with a focus on Apache Spark, Hadoop, and other open-source tools.
Q3) Why is Databricks so popular?
Databricks is popular because it integrates data engineering, machine learning, and analytics into a unified platform. It simplifies big data processing and allows for easy collaboration across teams, which speeds up data-driven decision-making.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





