

Trello lets you bring Kanban-style project management with any team: engineering, HR, marketing, or even sales. An intuitive board and card system makes it easy to plan, manage, and track tasks. Trello takes the capabilities a few steps further by integrating seamlessly into data storage solutions such as Amazon Redshift to consolidate and analyze project data from a single location.
In this blog, I will explain the process of setting up the Trello Redshift connection through a manual and automated method with key features in each approach.
Table of Contents
What is Trello?
Trello is a Kanban-style collaboration tool developed by Trello Enterprise in 2011 to organize project management processes into boards. It allows you to manage tasks among team members, collaborate for discussion, and keep an eye on the progress of the projects. Trello consists of boards, lists, and cards that help users manage tasks in projects.
1) Boards
Boards in Trello are like processes in project management or any other business operations. Every board consists of lists, which can be a list of to-do tasks. Every list consists of cards – you can add members, comments, labels, checklists, attachments, due dates, and more to your cards.
2) Workspace
You can start working in Trello initially by creating a workspace. Trello has a huge library of templates for a wide range of categories like Education, Human operations, Engineering-IT, Marketing, Sales, and more. You can either share your workspace with your team members by inviting them or keeping it private.
3) Templates
There are free templates available for each type of workspace. Users can also start with an empty board and design it according to their requirements.
A few suggestions:
What is Amazon Redshift?

Amazon Redshift is a fully managed, petascale, and cloud-based data warehousing service owned by AWS. It allows users to store and analyze their data with various business intelligence tools and acquire insights into business operations and customers.
Amazon clusters consist of one lead node and one or more compute nodes. The size of your data will decide the exact number of nodes in your clusters. You can create a data warehouse in Redshift by launching a set of nodes called Amazon Redshift clusters. Then, Redshift will perform the queries and analyze the data query performance.
There are several ways to manage clusters in Redshift, like the Amazon Redshift console or the AWS Command Line Interface. You can also use Amazon Redshift Query API or the AWS Software Development Kit (SDK) if you are an application developer to manage clusters programmatically.
Read about the Architecture of Redshift in detail and its components.
Looking for an automated solution for transferring your data? Hevo is here to save you from the hectic tasks of manually setting up data pipelines by providing more than 150+ sources (60+ free), including Trello, to data warehouses, such as Redshift. Here’s why you should give Hevo a try:
- A simple Python-based drag-and-drop data transformation technique that allows you to transform your data for analysis.
- Hevo eliminates the tedious task of schema management by automatically detecting the schema of incoming data and mapping it to the destination schema.
- Hevo provides real-time data migration, so you can always have analysis-ready data.
Try Hevo today to experience seamless data transformation and migration.
Get started for Free with Hevo Data!Prerequisites
- Set up Amazon Redshift Cluster in AWS.
- Fundamental knowledge of Integration.
- An active Trello account with access to the necessary boards.
- Trello API Key and Token for authentication.
How to Replicate Data From Trello to Amazon Redshift?
Method 1: Trello Redshift Integration Manually
Step 1: Export Data from Trello
- Log into Trello: Open your Trello account and go to the board whose data you would like to export.
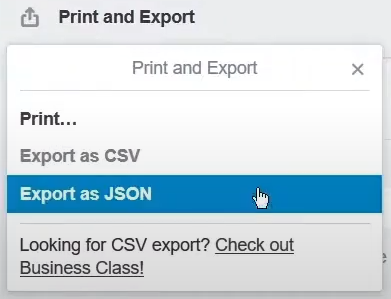
- Export Data: You can export board data of Trello in JSON format. Menu >> More >> Print and Export and then click on Export as JSON.
- Save the JSON File Locally: Save this JSON file locally on your system.
Step 2: Converting Trello Data into Redshift
- Parse JSON Data: Use a scripting language like Python to parse the JSON file to get relevant data points such as card names, descriptions, due dates, labels, and much more.
import json
import pandas as pd
# Load JSON file
with open('trello_board.json') as file:
data = json.load(file)
# Extract relevant data (customize this part based on Trello's JSON structure)
cards_data = []
for card in data['cards']:
cards_data.append({
'id': card['id'],
'name': card['name'],
'desc': card['desc'],
'due': card['due']
})
# Convert to DataFrame for easier handling
df = pd.DataFrame(cards_data)
# Save to CSV
df.to_csv('trello_data.csv', index=False)- Format Data for Redshift: Convert the DataFrame to CSV since it is one of the easier file formats to load into Redshift.
Step 3: Load Data into Amazon Redshift
- Upload CSV into Amazon S3:
- Log in to the AWS Management Console and go to the S3 service. Upload your trello_data.csv inside an S3 bucket
- Connect to Redshift: Open SQL client and connect to a cluster on Amazon Redshift
- Create a Table in Redshift: Define where you want your Trello data. Align the columns with the fields one can find in a CSV.
- Loading Data from S3 to Redshift: Use the COPY command to load data from S3 into Redshift.
COPY trello_cards
FROM 's3://your-bucket-name/trello_data.csv'
IAM_ROLE 'your-iam-role'
FORMAT AS CSV
IGNOREHEADER 1;- Verify Data Load: Once the COPY command runs successfully, execute a SELECT query to confirm that the data has been loaded into Redshift.
SELECT * FROM trello_cards LIMIT 10;Trello Redshift Connection works best when you have a flexible project timeframe and a pool of skilled engineering people to develop and manage the pipeline. However, the above-mentioned method requires a significant amount of time and maintenance.
Limitations of Manual Trello Redshift Integration
Keep an eye on these limitations of manual Trello Redshift Integration!
- Scalability: Indeed, scalability is critical! ETL systems can fail over time if processing conditions fail. For example, what if the volume of incoming data doubles? Can your processes handle such a significant rise in load? When using the manual ETL Code technique, a question like this necessitates careful consideration.
- Cost: The cost of engaging an ETL Developer to build a Trello Redshift ETL pipeline may be prohibitively expensive. Method 1 is not a low-cost alternative.
- Maintenance: Maintenance is critical for the data processing system; thus, your ETL programs must be updated on a regular basis as development tools improve their dependencies and industry standards change. Furthermore, maintenance wastes valuable engineering bandwidth that may be used elsewhere.

Method 2: Setting Up Trello Redshift Integration using Hevo Data
The following are the steps for loading data from Trello to Amazon Redshift using Hevo Data:
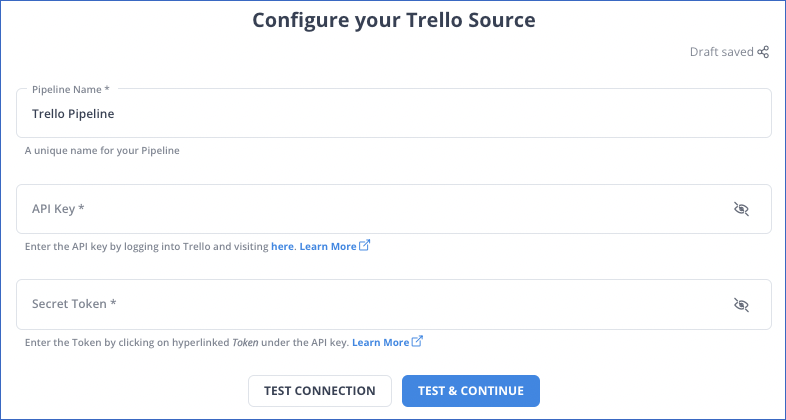
Step 1: Link your Trello account to the Hevo platform.
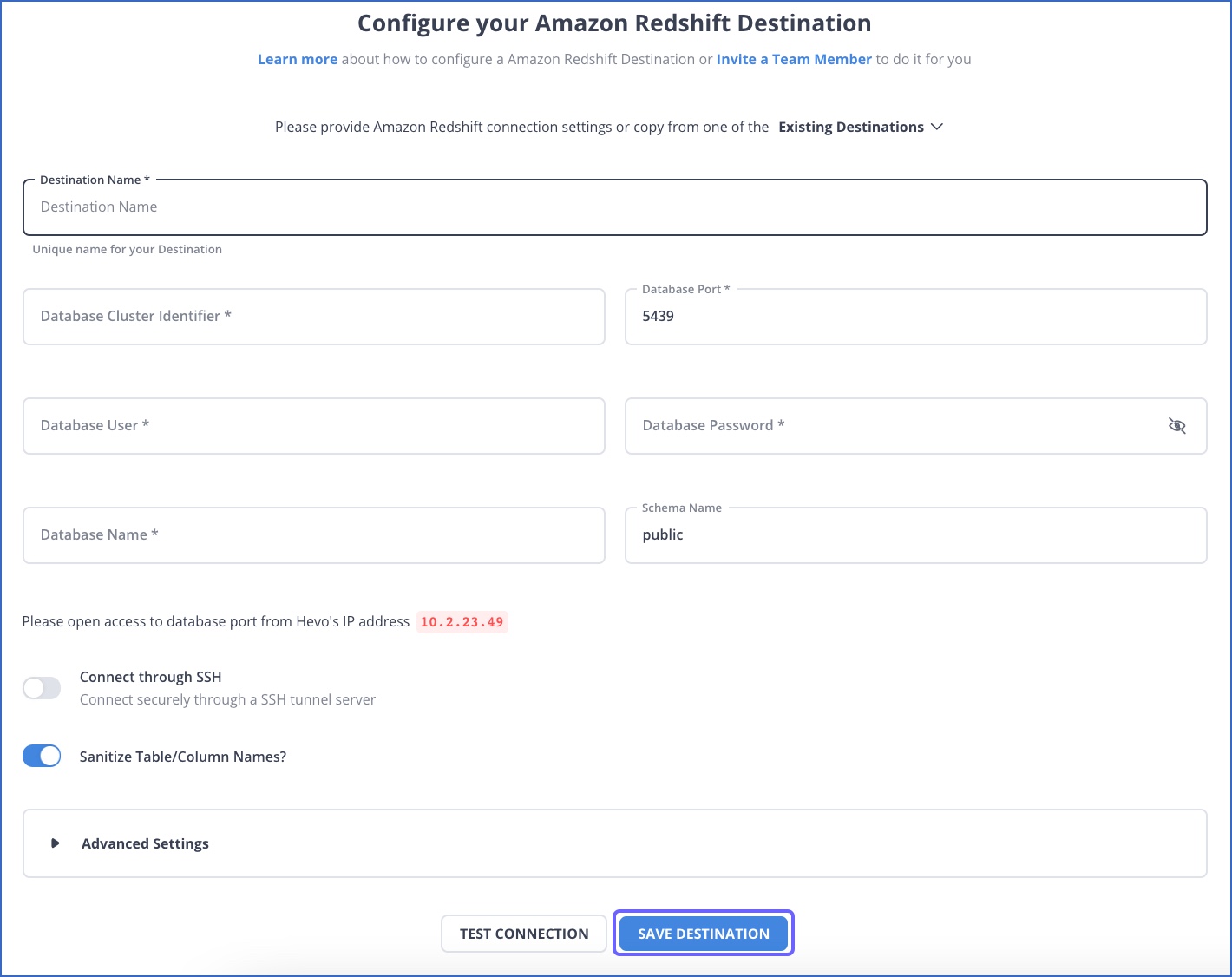
Step 2: Configure Redshift as your destination
You have now successfully configured Trello Redshift Integration with Hevo Data.
Check Out What Makes Hevo Amazing:
- Secure: Hevo has a fault-tolerant architecture that ensures that the data is handled in a secure, consistent manner with zero data loss.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Minimal Learning: Hevo, with its simple and interactive UI, is extremely simple for new customers to work on and perform operations.
- Hevo Is Built To Scale: As the number of sources and the volume of your data grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
- Live Monitoring: Hevo allows you to monitor the data flow and check where your data is at a particular point in time.
Benefits of Replicating Data from Trello to Redshift
Here’s a little something for the data analyst on your team. We’ve mentioned a few core insights you could get by replicating data from Trello to Redshift. Does your use case make the list?
- Which opportunities can you unlock to increase your team’s efficiency?
- What metrics can you use to measure the performance of your team?
- Who are the stakeholders involved in a project?
- What is the lifecycle of your project?
Conclusion
In this tutorial, you learned about connecting Trello with Amazon Redshift, either through a manual process or by using an automated method as per your requirement. The manual method will be at your fingertips but takes up a lot of time, and the scalability is less. On the contrary, the Hevo method makes the whole process very streamlined with minimal effort. In this case, all the data could be synchronized automatically. In that regard, you can take advantage of Trello data in Redshift using a method most suitable for your workflow.
Hevo is a No-code Data Pipeline and has awesome 150+ pre-built integrations that you can choose from. Hevo can help you integrate your data from numerous sources and load them into a destination to analyze real-time data with a BI tool such as Tableau. It will make your life easier and data migration hassle-free. It is user-friendly, reliable, and secure. Watch this short overview video to get a sense of how Hevo works:
Check out the pricing details. Want to take Hevo for a spin? Sign Up for a 14-day free trial and see the difference! Experience the power of Hevo firsthand.
Share your learning experience of the Trello Redshift Integration in the comment section below!
FAQs
1. What is Butler automation in Trello?
Butcher uses automation natively via Trello. It will help to free up repetitive work because it can introduce rules, buttons, and scheduled commands for the management of boards and workflows.
2. Does Trello use AWS?
Yes, Trello uses AWS, or Amazon Web Services, to host and manage the data it contains. This ensures reliable storage, scalability, and security for user information.
3. Can the Trello data be visualized in Redshift?
Yes, once your Trello data is placed in Redshift, you can easily use business intelligence tools like Tableau, Looker, or Amazon QuickSight to make some beautiful visualizations of the data.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




