

The field of data management is rapidly evolving as the volume and complexities of data continue to grow. In recent years, tools and technologies have revolutionized how organizations deal with data. There are certainly many concepts an organization needs to keep up with for efficient data analysis or management in general. One of the crucial concepts what is data stack.
A data stack is an infrastructure that makes data management possible. In this article, you will learn everything you need to get started with Modern Data Stack.
Table of Contents
What is a Data Stack?
A data stack refers to the tools and technologies that help organizations collect, process, store, and draw insights from data. Traditionally, there are various layers in a data stack working together, which can support every operation such as ingesting, storage, transformation, and then visualization or analysis.
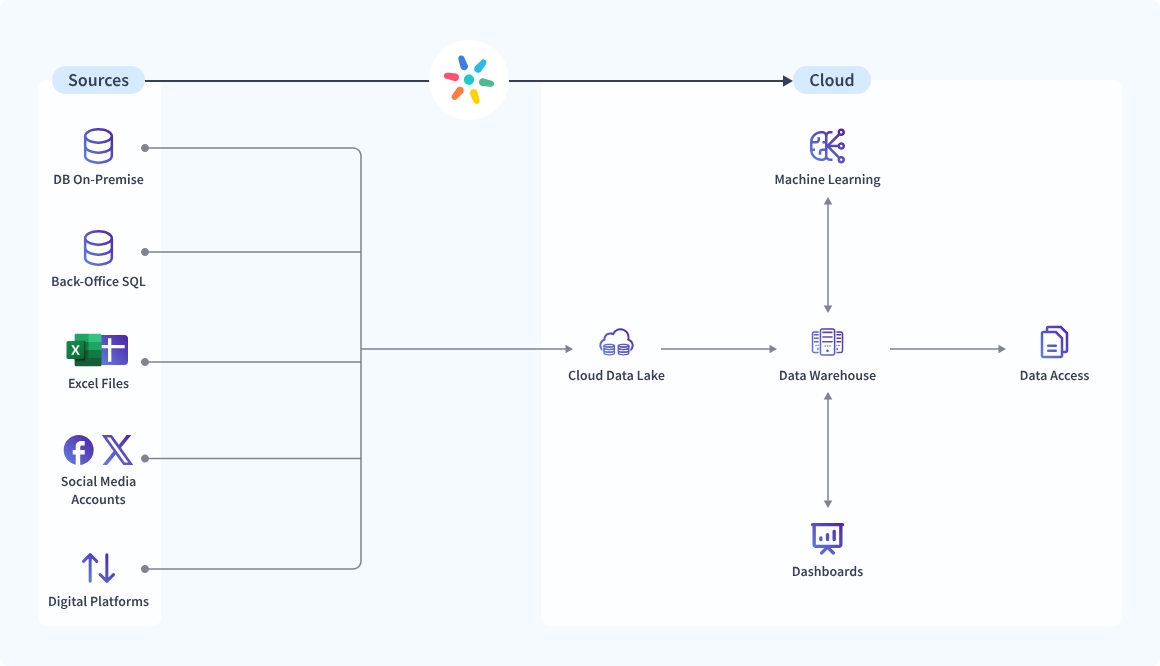
A majority of the Modern Data Stack comprises:
- Data Sources: Refers to places where data will originate from. These include data directly coming from within an application, database, or going through an external API.
- Data Ingestion Tools: The tools help bring data from numerous sources, such as Hevo, to the stack.
- Data Storage: Amazon Redshift, Google BigQuery, and Snowflake are data warehouses designed for storing data.
- Data Transformation: dbt, or Data Build Tool, which cleans, structures, and optimizes data for analysis.
- Data Visualization and Analytics: Looker, Tableau, Power BI, etc., allows anyone from the organization to explore and analyze data.
Learn about the difference between data modeling and data visualization.
Looking for a no-code platform to transform your data? Hevo is here to save you from the hectic tasks of manual coding and transformations. With more than 150 sources(60+ free) to a destination of your choice, here’s why you should give Hevo a try:
- Easy Integration: Connect and migrate data into Data Warehouses without any coding.
- Auto-Schema Mapping: Automatically map schemas to ensure smooth data transfer.
- In-Built Transformations: Transform your data on the fly with Hevo’s powerful transformation capabilities.
You can see it for yourselves by looking at our 2000+ happy customers, such as Airmeet, Cure.Fit, and Pelago.
Get Started with Hevo for FreeBenefits of Data Stack
Below are some of the key benefits of data stack:
- Modularity: Modularity is the key feature of a data stack. It allows you to separate a product into different standalone but interchangeable components. You can build a stack layer by layer and continue adding technologies and tools according to your business requirements and growth. It is most useful when changing a technology on a data stack without disrupting the whole data layer architecture.
- Documentation: With the help of a well-documented data stack, you can quickly access the information of different tools and technologies organizations use. This promotes collaboration and increases productivity within an organization.
- Enhanced Decision Making: The main objective of the data stack is to facilitate data-driven decision-making. Effective data organizing, processing, and analyzing allows organizations to make result-based decisions rather than going intuitively.
- Scalability: A data stack is not rigid, meaning you can add as much data layering in the stack as your business grows. Usually, the 4 or 5 mentioned above can be a good start for your data management. However, big organizations can use more components to efficiently handle huge volumes of data.
Use Cases of Data Stack
Marketing Attribution
- Data stacks can merge data from ad platforms, social media, and email campaigns to identify which channels create the most engagement and conversions. This might help marketers optimize their spending and strategy.
Fraud Detection
- Data stacks, by collating transactional data and using the help of machine learning models can highlight unusual patterns that help businesses prevent and detect fraud in real time.
Supply Chain Optimisation
- By using the data from logistics, inventory and sales, data stacks can hone its operations. They thereby enable business cost-cutting and proper handling of inventory besides faster deliveries.
Product Analytics
- A data stack can help teams leading the product understand user interaction, feature adoption, and usage of the product in a much deeper way. It will also offer a more profound understanding of user needs and make it easier to make product decisions informed by a lot more data.
Financial Forecasting
- A data stack may aid in extracting data from your accounting, sales, or market sources and then implementing your forecasting models. This will help your business budget financially and do financial planning besides predicting revenues for the near future.
Machine Learning and AI
- One key feature of data stacks is that they allow the training and deployment of machine learning models on large datasets. They are used in a variety of applications, including predictive maintenance, customer segmentation, and recommendation systems.
Best Practices for Building a Data Stack
Here are some of the best practices to make the most out of your data stack:
Start with Fewer Components
- Generally, there are four components: data source, data integration, data storage, and data analytics if you want to build a basic to intermediate data stack.
- However, businesses tend to add more and more components as data layering to their data stack from the beginning. Having 7-8-9 layers is good, but that makes data management a complex process.
- The bottom line is to start with fewer layers and gradually increase over time.
Choose Modern Data Stack Over Legacy Data Stack
The modern data stack is way better than the legacy one because of its features, functionalities, and ease of use. Below are some of the factors that explain why you should consider a modern data stack over a legacy data stack:
- Cloud Architecture: Modern data stacks have a cloud-based architecture. Using this, you can benefit from the cloud computing resources of Google, Microsoft, Amazon, and other industry leaders. On the contrary, legacy stacks are built on-premises and require hardware and maintenance investments.
- ELT: Modern stacks follow the ELT process for integrating data from different sources to the destination. The Extract, Load, Transform (ELT) approach allows raw data to load quickly in the centralized storage system without being transformed. This makes data processing more flexible and scalable.
- Analytical Capabilities: Modern data stacks are typically better equipped to use advanced analytical tools. This includes Python for machine learning and artificial intelligence, SQL for efficient querying, and data warehouse for managing data and supporting real-time analytics.
| Feature | Modern Data Stack | Legacy Data Stack |
| Architecture | Cloud-based, using services like Google, Microsoft, and Amazon. | On-premises needs hardware and upkeep. |
| Data Integration (ELT) | Follows ELT, loading raw data quickly before transforming. | Uses ETL, transforming data before loading, which is slower. |
| Analytical Capabilities | Supports advanced tools like Python, SQL, and real-time analytics. | Limited to basic SQL and traditional BI tools. |

Leverage Best Platforms for Every Component
While building a data stack, each of its components has a variety of tools available. Choosing the right tools with detailed stack analysis will decide the efficiency of your data management. Below are some of the recommendations for different data stack components.
- Data Integration: Hevo Data provides both real-time and batch data integrations.
- Data Warehouse: Redshift, Google BigQuery, and Microsoft Azure are some cloud-based data warehouses known for scalability and cost-effectiveness. You can choose any data warehouse provided by a known organization.
- Data Lake: AWS S3 is the go-to option for data lake for those who prefer open-source options. Tools like Google Cloud Storage and Azure Blob Storage are also widely used.
- Data Visualization: Power BI and Tableau are two of the most popular tools for data visualization.
- Data Analytics: Python is a widely known tool for data analytics.
Data Governance
- Data Governance ensures the overall data quality across an organization. Practices included in data governance make sure the data is protected from any misuse. Two of its critical practices are data security and data sanity.
- Data security covers measures such as encryption, network security, and access controls to safeguard data from unauthorized access. However, data sanity checks if the data is consistent, reliable, and ready to work with.
- Above all, data governance verifies that your stack complies with data privacy rules and regulations relevant to your industry.
- This helps avoid unnecessary data breaches, maintain trust with your customers, and even comply with laws such as GDPR, HIPAA, and CCPA.
- Defining data policies and standards, data classification, regular audit trails, and monitoring are some of the best practices you can perform to ensure data governance.
Regular Review and Update
- Data is dynamic, and business needs are evolving in nature. To manage both effectively, regularly reviewing and updating your data stack is the key.
- It involves reviewing data quality, considering new tools, monitoring performance with stack analysis, and updating the data stack as needs change.
- For instance, based on growing data volumes, advanced analytical requirements, and technological advancement, you might need to upgrade your data warehouse or business intelligence tools.
- This practice will ensure you keep up with the trends, such as including data stacks that can support generating insights into unstructured data through AI and ML and staying competitive in the data-driven industry.
Conclusion
Every organization dealing with data needs a personalized data stack. It’s the infrastructure that converts inedible data (data that you can not work with) to edible data (data you can work with) in the most efficient way.
By having the right knowledge of data stacking and following the best practices mentioned above, you can make the most out of the data assets of your organization. And if you are struggling with layer configurations in a data stack. There are a plethora of tools and services you can choose to add to your stack that offer services to automate each layer of the data stack in cost-effective and scalable ways.
Overall, the data stack is an exciting space with many new trends and technologies entering the market daily. Staying updated with these developments is key to making a data stack that serves your business requirements well. This includes trying out automated platforms like Hevo Data.
Hevo is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs. With integration with 150+ Data Sources (40+ free sources), we help you not only export data from sources & load data to the destinations but also transform & enrich your data, & make it analysis-ready.
Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. Check out the Hevo pricing details.
FAQs
1. What is the difference between a data platform and a data stack?
A data platform is a complete environment that supports data storage, processing, and analysis. A data stack refers to coupling numerous tools to handle forms of data that start from ingestion to visualization.
2. How do you create a data stack?
Define and build a data stack with the tools to be set up at each step of the data lifecycle, starting from ingestion of that data, then putting it somewhere in storage, transforming it, and then having it analyzed. So, that’s a combination of cloud services with tools such as Snowflake for storage.
3. What does a modern data stack look like?
A modern data stack is cloud-based, where storage is either Snowflake or BigQuery, transformed with dbt and BI tools like Looker for visualization. The ELT approach makes it efficient and agile to process data, among other things.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



