

For decades, traditional on-premises data Warehouses have been tightly coupled with Data Storage and Computing, making them difficult to scale. However, today’s businesses must store and analyze massive amounts of Structured and Unstructured data from disparate services & sources, necessitating a service like Snowflake that can handle large data volumes as well as variable compute requirements for applications like visualization. One of the first things you’ll do while setting up your Snowflake environment establishes a Snowflake Virtual Warehouse.
Upon a complete walkthrough of this article, you will gain a holistic understanding of Snowflake Virtual Warehouses along with the advantages offered by its architecture. You will also learn about the steps involved in creating a Snowflake Virtual Warehouse. This article will further provide you with some key points that can help you manage the cost of your Snowflake Virtual Warehouse.
Table of Contents
What is Snowflake?
Snowflake is one of the most popular Cloud Data Warehouses that offers a plethora of features without compromising simplicity. It scales automatically, both up and down, to offer the best Performance-to-Cost ratio. The distinguishing feature of Snowflake is that it separates Compute from Storage. This is significant as almost every other Data Warehouse, including Amazon Redshift, combines the two, implying that you must consider the size for your highest workload and then incur the costs associated with it.
Snowflake requires no hardware or software to be chosen, installed, configured, or Managed, making it ideal for organizations that do not want to dedicate resources to the Setup, Maintenance, and Support of In-house Servers. It allows you to store all of your data in a centralized location and size your Compute independently. For example, if you require real-time data loads for complex transformations but only have a few complex queries in your reporting, you can script a massive Snowflake Warehouse for the data load and then scale it back down after it’s finished – all in real-time. This will save you a significant amount of money without jeopardizing your solution goals.
Key Features of Snowflake
Some of the key features of Snowflake are as follows:
- Scalability: The Compute and Storage resources are separated in Snowflakes’ Multi-Cluster Shared Data Architecture. This strategy gives users the ability to scale up resources when large amounts of data are required to be loaded quickly and scale back down when the process is complete without disrupting any kind of operation.
- No Administration Required: It enables businesses to set up and manage a solution without requiring extensive involvement from Database Administrators or IT teams. It does not necessitate the installation of software or the commissioning of hardware.
- Security: Snowflake houses a wide range of security features, from how users access Snowflake to how the data is stored. To restrict access to your account, you can manage Network Policies by whitelisting IP addresses. Snowflake supports a variety of authentication methods, including Two-Factor Authentication and SSO via Federated Authentication.
- Support for Semi-Structured Data: Snowflake’s warehouse architecture enables the storage of Structured and Semi-Structured data in the same location by utilizing the VARIANT schema on the Read data type. VARIANT can store both Structured and Semi-structured data. Once the data is loaded, Snowflake automatically parses it, extracts the attributes out of it, and stores it in a Columnar Format.
- Environment Separation: Warehouses in Snowflake can be used to maintain separate development and testing environments, isolating them from the production environment for enhanced operational efficiency and control.
What is a Snowflake Virtual Warehouse?

Snowflake Virtual Warehouse is a cluster of Database Servers that are deployed on-demand to handle user queries. It is equivalent to an MPP (Massively Parallel Processing) Server for an On-Premise database and is a dynamic cluster of virtual Database Servers made up of CPU Cores, Memory, and SSD that is kept in a hardware pool and deployed in milliseconds. This process is completely transparent to the end-user.
In Snowflake, a warehouse consists of a group of database servers that supply the necessary resources to carry out tasks such as running SQL queries and performing DML operations.
Snowflake Virtual Warehouse comes in a variety of T-shirt sizes ranging from Extra Small to 4XL, with each representing an increase in the hardware resources available to the user. The users always connect to Snowflake via a URL that initiates a process in the Cloud Services layer. Any SQL query that requires data access is executed on a Virtual Warehouse, and data is retrieved from Cloud Storage.
Following are the advantages of the architecture of a Snowflake Virtual Warehouse:
- Dynamic Sizing: Since the Storage and Compute hardware are completely independent, and the fast SSD storage in the Virtual Warehouse is entirely temporary, a variety of Virtual Warehouse sizes can be allocated and adjusted on the fly as needed. This means that you can start with a single XSMALL server and scale up to a 3XLARGE monster machine in milliseconds.
- Zero Contention: Any number of Virtual Warehouses (each sized to the specific demands of the task) can be deployed, and each is completely independent of the others. When compared to traditional database architecture, where multiple groups share the same machine resources, this results in Zero Resource Contention. Each team has dedicated hardware with a Snowflake Virtual Warehouse.
- Automatic Suspension: When queries on a Snowflake Virtual Warehouse is no longer running, it can automatically suspend and resume within milliseconds if a new SQL query needs to be executed. To the end-user, this entire process is transparent.
- Pay as you go: Snowflake charges per second after the first minute, unlike other Cloud-based Services that charge for a machine for an hour. This means that you only pay for the compute resources you use.
- Regulatory Compliance: Snowflake includes native features designed to help organizations comply with various regulatory requirements, including HIPAA, FedRAMP, SOC 1, and SOC 2, making it easier for businesses to meet their compliance obligations.
Hevo Data is now available on Snowflake Partner Connect, making it easier than ever to integrate your data seamlessly. With Hevo’s powerful data integration capabilities, Snowflake users can connect to Hevo directly from their Snowflake environment and streamline their data pipelines effortlessly. Hevo offers:
- More than 150 source connectors from databases, SaaS applications, etc.
- A simple Python-based drag-and-drop data transformation technique that allows you to transform your data for analysis.
- Automatic schema mapping to match the destination schema with the incoming data. You can also choose between Full and Incremental Mapping.
- Proper bandwidth utilization on both the source and destination allows for the real-time transfer of modified data.
- Transparent pricing with no hidden fees allows you to budget effectively while scaling your data integration needs.
Try Hevo today to seamlessly integrate data into Snowflake.
Get Started with Hevo for FreeHow to Determine the Size of the Snowflake Virtual Warehouse?
Snowflake Warehouse T-Shirts are available in a variety of sizes, as shown below:
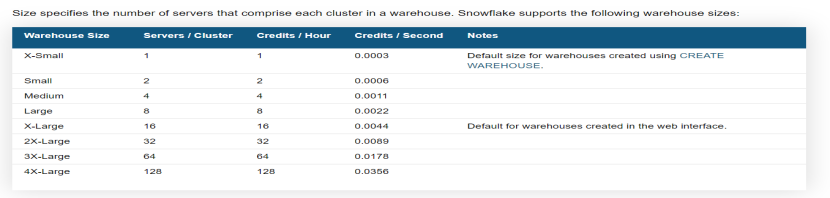
An increase in T-Shirt size (XS-4XL) corresponds to a proportional increase in CPU, Memory, and Temporary Storage. You don’t have control over individual sizes, but you can change your warehouse size by selecting one of the T-Shirt sizes. Because Snowflake storage and computing are loosely coupled, you can start and stop the warehouse at any time.
You can specify the size, multi-cluster attribute (Enterprise & above), and scaling policy at the time of creation. See the list below.

Because there are a variety of workloads in any organization, you can’t choose just one or two to cover the entire workload. Also, in Snowflake, creating multiple warehouses is free; you can create as many as you want and only pay for what you use. For instance, we have the following groups in any high-level IT project:
- Development Team
- ETL Team
- Test Team
- Reporting Team
Each group of people is assigned a different amount of work. Let’s say the ETL team is constantly busy loading data, while the reporting team is only working on query reports. While the development team is busy writing code, they may try a variety of activities.
Similarly, a test team will run the entire flow from beginning to end or module by module to ensure the program’s sanity. As a result, each group of people has a different workload, necessitating the use of different warehouses.
So the best option is to set up a separate warehouse for each team with some initial sizing and monitor whether you need to adjust the size as they require.
A Snowflake-native app to monitor Fivetran costs

What is Snowflake’s Scaling Policy?
You can choose between two types of scaling policies in Snowflake:
- Standard(default)
- Economy

What are the 2 modes to Define Warehouse in Snowflake?
Warehouses can be provisioned in two different ways in Snowflake. It can be set to either maximized or Auto-Scale mode.
Auto-Scale Mode
You select auto-scale mode when you enter different values for Minimum and Maximum clusters, as shown below. Snowflake uses this mode to dynamically manage the warehouse load by starting and stopping clusters as needed. The warehouse scales out/in as the number of concurrent users or query load increases or decreases.

Maximized Mode
When you set the Minimum and Maximum clusters to the same value (Should be >1), you’re choosing maximized mode. When the warehouse is started in this mode, Snowflake starts all of the clusters, ensuring that the warehouse has the most resources available. This mode is appropriate when you know your workload will have multiple concurrent users and will require a provisioned server to support them.
How to Create a Snowflake Virtual Warehouse?
Creating a Snowflake Virtual Warehouse is a fairly simple process. Follow the steps given below to do so:
- The SQL script given below demonstrates how to create a SMALL Snowflake Virtual Warehouse that will automatically suspend after 10 minutes and resume immediately once queries are executed.
create warehouse PROD_REPORTING with
warehouse_size = SMALL
auto_suspend = 600
auto_resume = true
initially_suspended = true
comment = 'Sample Reporting Warehouse';- Once you have successfully created a Virtual Warehouse, use the following command to select a specific Virtual Warehouse:
use warehouse SAMPLE_REPORTING;- Any SQL Statements/Queries executed after this point will be executed on the specified Virtual Warehouse. Using this method, different teams can be assigned dedicated hardware, and each user can be assigned a default warehouse.
How to Manage the Cost of Your Snowflake Virtual Warehouse?

Depending on the size of your data and the number of users tasked with the Data Warehousing and Data Management operations, Snowflake offers a set of computing clusters categorized by their sizes. While running, a Snowflake Virtual Warehouse consumes Snowflake Credits. The number of credits consumed is determined by the size of the warehouse and the duration of the Virtual Warehouse. Managing credit consumption to ensure efficient usage is key to controlling your data warehouse cost, especially when using platforms like Snowflake Virtual Warehouse. There are some very simple things you can do to manage the cost of your Snowflake Virtual Warehouse. They are as follows:
1) Set up Resource Monitors
Snowflake Virtual Warehouse’s Compute Costs can be managed by triggering specific actions, such as sending notifications or suspending one or more warehouses. This can be done with the help of Resource Monitors. Hence, it is advisable to create Resource Monitors if you are an account administrator.
2) Query the Snowflake Database
The Account Administrator also has access to the Snowflake database, which is a read-only shared database provided by Snowflake. This database, among other things, can be queried to retrieve information about the Warehouses consuming the most credits. Once you’ve successfully determined the warehouses consuming the maximum credits, you can delve into further details using the History Tab.
3) Make Good Warehouse Auto-Suspension Choices
When you create a new Warehouse, the Auto-Suspend value is set to 600 seconds by default. This means that the Warehouse will automatically suspend after 10 minutes of inactivity. If your workload runs infrequently, you may want to reduce your default value to one minute (60 seconds). It is important to note that you should not set the Auto-Suspend value to NULL unless your query workloads necessitate a continuously running Warehouse, otherwise your consumption charges will be much higher than necessary. Since the Warehouse cache is lost every time a Warehouse is suspended, it may be cheaper and faster not to have the Warehouse Auto-Suspend if jobs are continuously executed.

What are Auto-resumption and Auto-suspension?
A warehouse can be programmed to resume or suspend operations based on activity:
- Auto-suspension is turned on by default. If the warehouse is inactive for an extended period of time, Snowflake suspends it automatically.
- Auto-resume is activated by default. When any statement that requires a warehouse is submitted, Snowflake automatically resumes the warehouse, and the warehouse becomes the session’s current warehouse.
- Only the entire warehouse is affected by auto-suspend and auto-resume, not individual clusters.
Learn More About:
Conclusion
This blog introduced you to Snowflake along with the salient features that it offers. Furthermore, it introduced you to Snowflake Virtual Warehouses and the pointers that you can leverage to manage its costs. As your business begins to grow, data is generated at an exponential rate across all of your company’s SaaS applications, Databases, and other sources.
To meet this growing storage and computing needs of data, you would require to invest a portion of your Engineering Bandwidth to Integrate data from all sources, Clean & Transform it, and finally load it to a Cloud Data Warehouse such as Snowflake for further Business Analytics. All of these challenges can be efficiently handled by a Cloud-Based ETL tool such as Hevo Data. Sign up for Hevo’s 14-day free trial and experience seamless data migration.
Frequently Asked Questions
What are Snowflake virtual warehouses?
Snowflake virtual warehouses are independent compute resources used for executing queries, loading data, and performing other operations in the Snowflake environment.
Why Snowflake is better than other warehouses?
Snowflake outperforms other data warehouses due to its unique architecture, which separates storage and computing, enabling efficient scalability.
Is Snowflake easy to learn?
Yes, Snowflake is considered easy to learn. Its intuitive interface, clear documentation, and SQL-based querying make it accessible for users familiar with relational databases.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





