



Asana is a Work Management Platform available as a Cloud Service that helps users to organize, track and manage their tasks. Asana helps to plan and structure work in a way that suits organizations. All activities involved in a typical organization, right from Project Planning to Task Assignment, Risk Forecasting, Assessing Roadblocks, and changing plans can be handled on the same platform. All this comes at a very flexible pricing plan based on the number of users per month.
There is also a free version available for teams up to a size of 15. Almost 70000 organizations worldwide use asana for managing their work. Since the platform is closely coupled with the day-to-day activities of the organizations, it is only natural that the organizations will want to have the data imported into their Data Warehouse for analysis and building insights. This is where Amazon Redshift comes into play.
In this blog post, you will learn to load data from Asana to Redshift Data Warehouse which is one of the most widely used completely managed Data Warehouse services.
Table of Contents
Introduction to Asana

Asana is a project management software that provides a comprehensive set of APIs to build applications using its platform. Not only does it allow access to data, but it also has APIs to insert, update, and delete data related to any item in the platform. It is important to understand the object hierarchy followed by Asana before going into detail on how to access the APIs. Learn how to use Asana CRM to streamline your projects.
Asana Object Hierarchy
Objects in Asana are organized as the below basic units.
- Tasks: Tasks represent the most basic unit of action in Asana.
- Projects: Tasks are organized into projects. A project represents a collection of tasks that can be viewed as a Board, List, or Timeline.
- Portfolio: A portfolio is a collection of projects.
- Sections: Tasks can also be grouped as sections. Sections usually represent something lower in the hierarchy than projects.
- Subtasks: Tasks can be represented as a collection of subtasks. Subtasks are similar to the task, except that they have a parent task.
Users in Asana are organized as workspaces, organizations, and teams. Workspaces are the highest-level units. Organizations are special workspaces that represent an actual company. Teams are a group of users who collaborate on projects.
Asana API Access
Asana allows API access through two mechanisms.
- OAuth: This method requires an application to be registered in the Asana admin panel and user approval to allow data access through his account. This is meant to be used while implementing applications using the Asana platform.
- Personal Access Token: A personal access token can be created from the control panel and used to successfully execute API calls using an authorization header key. This is meant to be used while implementing simple scripts. We will be using this method to access Asana data.
Asana API Rate Limits
Asana API enforces rate limits to maintain the stability of its systems. Free users can make up to 150 requests per minute and premium users can make up to 1500 requests per minute. There is also a limit to the concurrent number of requests. Users can make up to 50 read requests and 15 write requests concurrently.
There is also a limit based on the cost of a request. Some of the API requests may be costly at the back end since Asana will have to traverse a large nested graph to provide the output. Asana does not explicitly mention the exact cost quota but emphasizes that if you make too many costly requests, you could get an error as a response.
Introduction to Amazon Redshift

Amazon Redshift is a completely managed database offered as a cloud service by Amazon Web Services (AWS). It offers a flexible pricing plan with the users only having to pay for the resources they use. AWS takes care of all the activities related to maintaining a highly reliable and stable Data Warehouse. The customers can thus focus on their business logic without worrying about the complexities of managing a large infrastructure.
Amazon Redshift is designed to run complex queries over large amounts of data and provide quick results. It accomplishes this through Massively Parallel Processing (MPP) architecture. Amazon Redshift works based on a cluster of nodes. One of the nodes is designated as a Leader Node, and others are known as Compute Nodes. Leader Node handles client communication, query optimization, and task assignment.
Redshift can be scaled seamlessly by adding more nodes or upgrading existing nodes. Redshift can handle up to a PB of data. Redshift’s concurrency scaling feature can automatically scale the cluster up and down during high load times while staying within the customer’s budget constraints. Users can enjoy a free hour of concurrency scaling for every 24 hours of a Redshift cluster staying operational.
Method 1: Build a Custom Code to Replicate Data from Asana to Redshift
You will invest engineering bandwidth to hand-code scripts to get data from Asana’s API to S3 and then to Redshift. Additionally, you will also need to monitor and maintain this setup on an ongoing basis so that there is a consistent flow of data.
Method 2: Replicate Data from Asana to Redshift using Hevo Data
Bringing data from Asana works pretty much out of the box while using a solution like the Hevo Data Integration Platform. With minimal tech involvement, the data can be reliably streamed from Asana to Redshift in real-time.
Sign up here for a 14-day Free Trial!Method 1: Build a Custom Code to Replicate Data from Asana to Redshift
The objective here is to import a list of projects from Asana to Redshift. You will be using the project API in Asana to accomplish this. To access the API, you will first need a personal access token. Let us start by learning how to generate the personal access token. Follow the steps below to build a custom code to replicate data from Asana to Redshift:
- Step 1: Access the Personal Access Token
- Step 2: Access the API using Personal Access Token
- Step 3: Convert JSON to CSV
- Step 4: Copy the CSV File to AWS S3 Bucket
- Step 5: Copy Data to Amazon Redshift
Step 1: Access the Personal Access Token
Follow the steps below to access the Personal Access Token:
- Go to the “Developer App Management” page in Asana and click on the “My Profile” settings.
- Go to “Apps” and then to “Manage Developer Apps” and then click on “Create New Personal Access Token”.

- Add a description and click on “Create”.
- Copy the token that is displayed.
Note: This token will only be shown once and if you do not copy it, you will need to create another one.
Step 2: Access the API using Personal Access Token
With the Personal Access Token that you copied in your last step, access the API as follows.
curl -X GET https://app.asana.com/api/1.0/projects -H 'Accept: application/json' -H 'Authorization: Bearer {access-token}'
The response will be a JSON in the following format.
{ "data": [ { "gid": "12345", "resource_type": "project", "name": "Stuff to buy", "created_at": "2012-02-22T02:06:58.147Z", "archived": false, "color": "light-green", … }, {....}
The response will contain a key named data. The value for the “data”. Key will be a list of project details formatted as a nested JSON. Save the file as “projects.json”.
Step 3: Convert JSON to CSV
Use the command-line JSON processor utility jq to convert the JSON to CSV for loading to MySQL. For simplicity, you will only convert the name, created_at, and due_date attributes of project details.
jq -r '.data[] | [.name, .start_on, .due_on] | @csv' projects.json > projects.csv
Note: name, start_on, and due_on are fields contained in the response JSON. If you need different fields, you will have to modify the above code as per your requirement.
Step 4: Copy the CSV File to AWS S3 Bucket
Copy the CSV file to an AWS S3 Bucket location using the following code.
aws s3 cp projects.csv s3://my_bucket/projects/
Step 5: Copy Data to Amazon Redshift
Login to “AWS Management Console” and type the following command in the Query Editor in the Redshift console and execute.
copy target_table_name from ‘s3://my_bucket/projects/ credentials access_key_id <access_key_id> secret_access_key <secret_access_key>
Note: access_key_id and secret_access_key represent the IAM credentials.
Drawbacks of Building a Custom Code to Replicate Data from Asana to Redshift
Listed below are the drawbacks of building a custom code to replicate data from Asana to Redshift:
- Asana provides some of the critical information related to objects like authors, workspaces, etc are available inside nested JSON structures in the original JSON. These can only be extracted by implementing a lot of custom logic.
- In most cases, the import function will need to be executed periodically to maintain a recent copy. Such jobs will need mechanisms to handle duplicates and scheduled operations.
- The above method uses a complete overwrite of the Redshift table. This may not be always practical. In case incremental load is required, the Redshift INSERT INTO command will be required. But this command does not manage duplicates on its own. So a temporary table and related logic to handle duplicates will be required.
- The current approach does not have any mechanism to handle the rate limits by Asana.
- Any further improvement to the current approach will need the developers to have a lot of domain knowledge in Asana and their object hierarchy structure.

Method 2: Replicate Data from Asana to Redshift using Hevo Data
Are you also tired of reading hundreds of blogs using the same long and tedious methods and long lines of code for migrating data from Asana to Redshift? Don’t worry, we got you covered. Here is a simple, no-code method that migrates your data from Asana to Redshift in under 1 minute with just a few clicks!
Step 1: Configure Asana as a Source
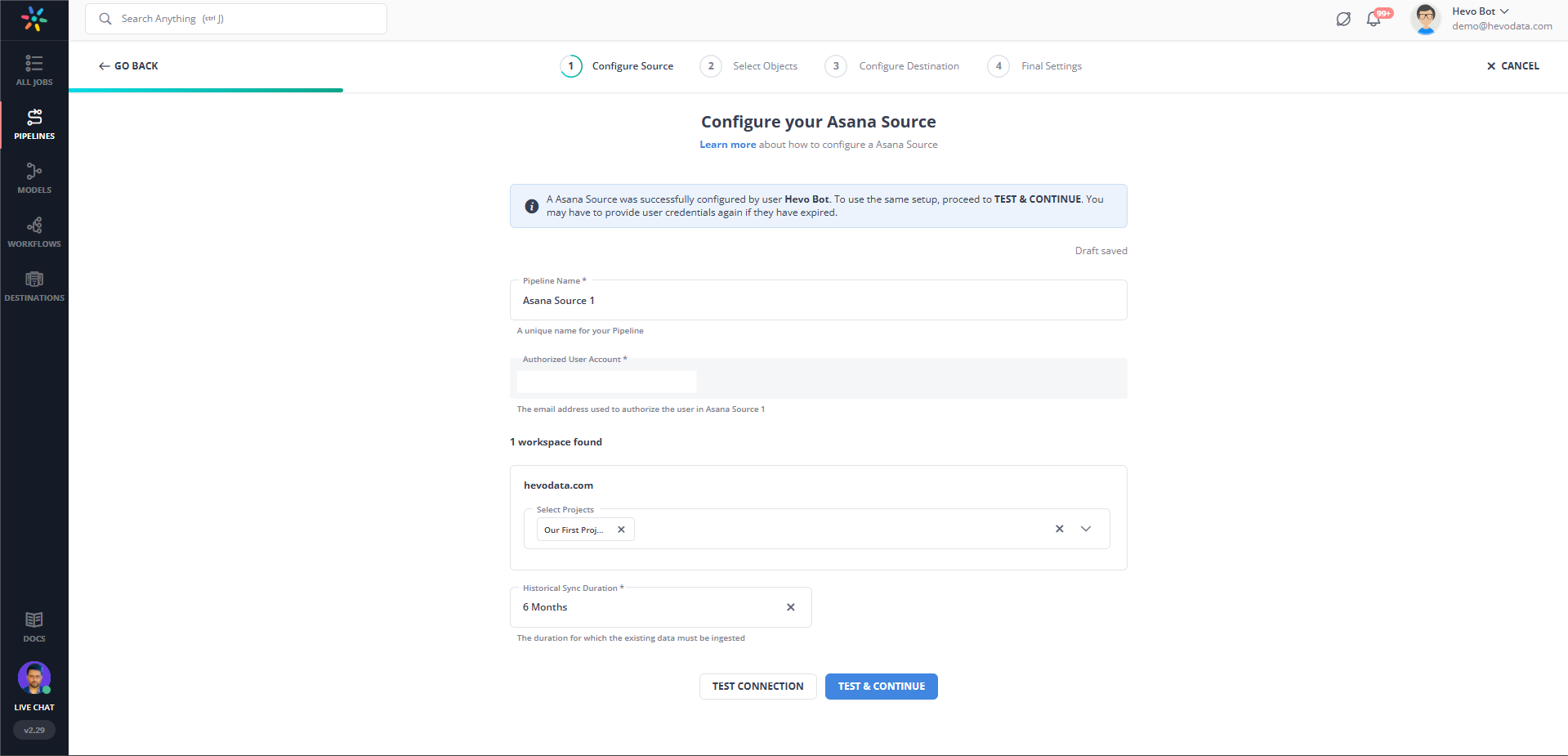
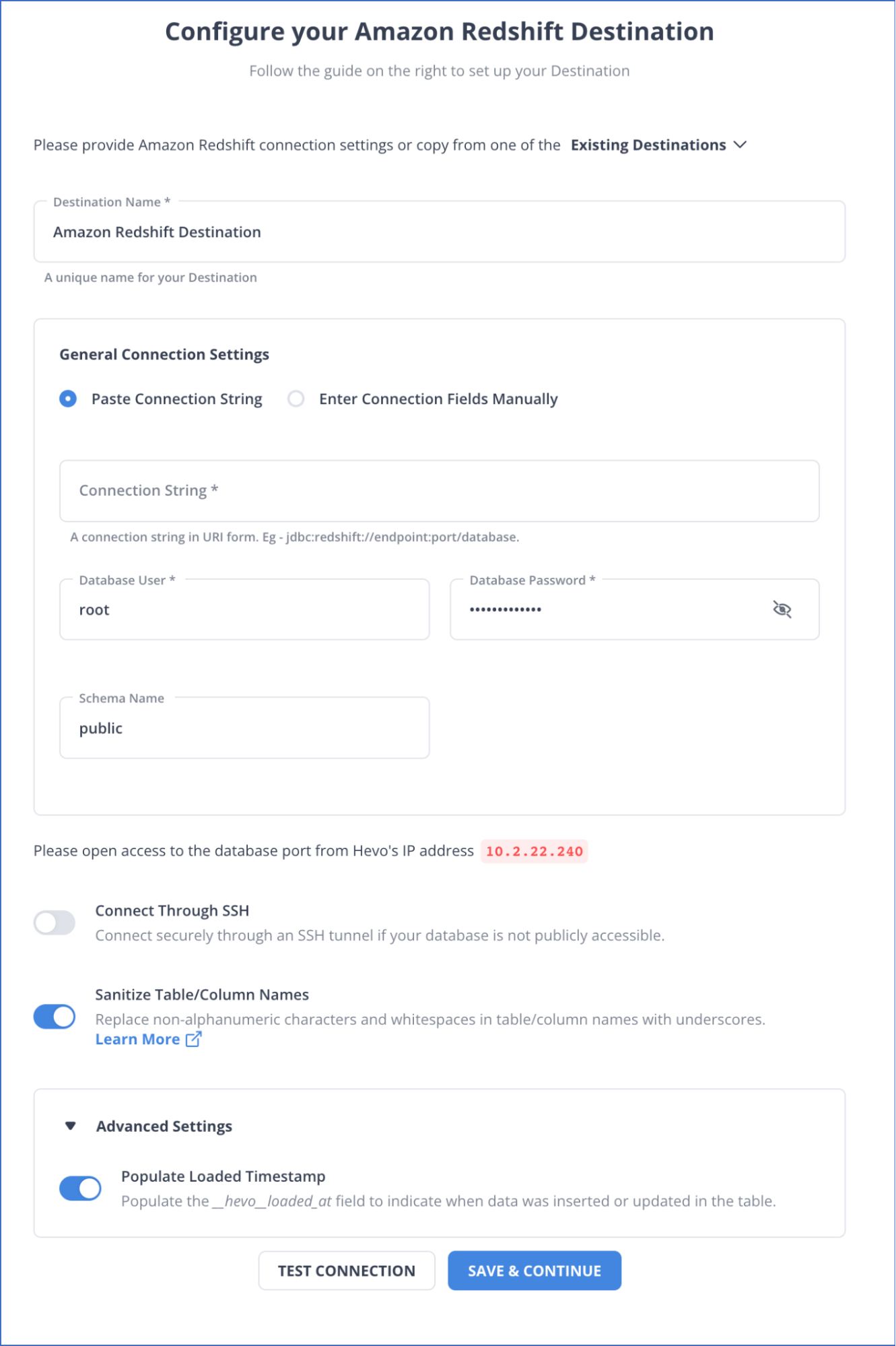
Step 2: Configure Redshift as the destination.
Check out why Hevo is the Best:
- Secure: Hevo has a fault-tolerant architecture that ensures that the data is handled in a secure, consistent manner with zero data loss.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Minimal Learning: Hevo, with its simple and interactive UI, is extremely simple for new customers to work on and perform operations.
- Hevo Is Built To Scale: As the number of sources and the volume of your data grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
- Live Monitoring: Hevo allows you to monitor the data flow and check where your data is at a particular point in time.
Learn More About:
Load Data from Asana to Snowflake
Conclusion
The article introduced you to Asana and Amazon Redshift. It also provided 2 methods that you can use to replicate data from Asana to Redshift. The 1st method involves Manual Integration while the 2nd method involves Automated Continous Integration.
With the complexity involves in Manual Integration, businesses are leaning more towards Automated Integration. This is not only hassle-free but also easy to operate and does not require any technical proficiency. In such a case, Hevo Data is the right choice for you! It will help simplify the Web Analysis process by setting up Asana to Redshift Integration.
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite first hand.
Share your experience setting up Asana to Redshift Integration in the comments section below!
FAQs
1. What data from Asana can be transferred to Redshift?
You can transfer task details, project updates, team member activities, and timelines for comprehensive analysis.
2. How often should Asana data be synced with Redshift?
Sync frequency depends on your needs; commonly, data is updated daily or hourly for real-time insights.
3. Are there any limitations to Asana to Redshift integration?
Limitations include API rate limits from Asana, data formatting requirements, and potential ETL tool costs.
Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



