



Are you trying to derive deeper insights from your Aurora Database by moving the data into a larger Database like Amazon Redshift? Well, you have landed on the right article. Now, it has become easier to replicate data from Aurora to Redshift.
This article will give you a comprehensive guide to Amazon Aurora and Amazon Redshift. You will explore how you can utilize AWS Glue to move data from Aurora to Redshift using 7 easy steps. You will also get to know about the advantages and limitations of this method in further sections. Let’s get started.
Table of Contents
What is Amazon Aurora?

Amazon Aurora is a fully managed relational database engine by AWS, designed for MySQL and PostgreSQL compatibility. Known for its high performance and scalability, it offers the speed and availability of high-end commercial databases at a fraction of the cost. Aurora is ideal for applications requiring resilience, efficiency, and scalability.
- Key Features:
- Automated Backups & Snapshots: Enables continuous backups to Amazon S3 with point-in-time recovery.
- High Performance: Delivers up to 5x the throughput of standard MySQL and 3x of PostgreSQL.
- Scalability: Automatically scales storage up to 128 TB as needed.
- High Availability: Provides fault-tolerant storage across multiple Availability Zones, ensuring low-latency failover in case of issues.
Before Finalizing Amazon aurora, check out how it compares to other tools like Snowflake to make an informed decision. Read about AWS Aurora vs Snowflake through our blog.
Looking to elevate your data analytics? Migrating from Amazon Aurora to Redshift opens up a world of advanced insights and scalable performance! With Hevo, you can:
- Automate Data Extraction: Effortlessly pull data from AWS Aurora MySQL(and other 60+ free sources).
- Transform Data effortlessly: Use Hevo’s drag-and-drop feature to transform data with just a few clicks.
- Seamless Data Loading: Quickly load your transformed data into your desired destinations, such as Redshift.
Try Hevo and join a growing community of 2000+ data professionals who rely on us for seamless and efficient migrations.
Get Started with Hevo for FreeWhat is Redshift?
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud, provided by Amazon Web Services (AWS). It allows you to run complex queries and analytics on massive datasets quickly, making it ideal for business intelligence, reporting, and data warehousing.
Key Features of Redshift
- Petabyte-scale data warehouse: Redshift can scale from a few hundred gigabytes to petabytes of data. You can easily resize clusters up or down as your data needs grow or shrink.
- Redshift uses a columnar storage format to store data, which drastically reduces the amount of I/O required to execute queries.
- Redshift employs Massively Parallel Processing (MPP) architecture, which distributes data and query execution across multiple nodes.
- Automated backups: Redshift automatically backs up your data to Amazon S3 (Simple Storage Service). You can configure backup retention periods, and it will retain snapshots for up to 35 days by default.
Prerequisites
You will have a much easier time understanding the method of connecting Aurora to Redshift if you have gone through the following aspects:
- An active account in AWS.
- Working knowledge of Database and Data Warehouse.
- Basic knowledge of the ETL process.
Introduction to AWS Glue

AWS Glue is a serverless ETL service provided by Amazon. Using AWS Glue, you pay only for the time you run your query. In AWS Glue, you create a metadata repository (data catalog) for all RDS engines including Aurora, Redshift, and S3, and create connection, tables, and bucket details (for S3). You can build your catalog automatically using a crawler or manually. Your ETL internally generates Python/Scala code, which you can customize as well. Since AWS Glue is serverless, you do not have to manage any resources and instances. AWS takes care of it automatically.
What’s the Quickest Way to Migrate Data from AWS Aurora to Redshift?
If you are looking for a simple, fast, and hassle-free way to migrate your data from sources like AWS Aurora PostgreSQL to Redshift, we have the best solution. Try Hevo, a simple, reliable, no-code platform that migrates your data to your desired destination within minutes in just two simple steps.
Step 1: Configure AWS Aurora PostgreSQL as your source.
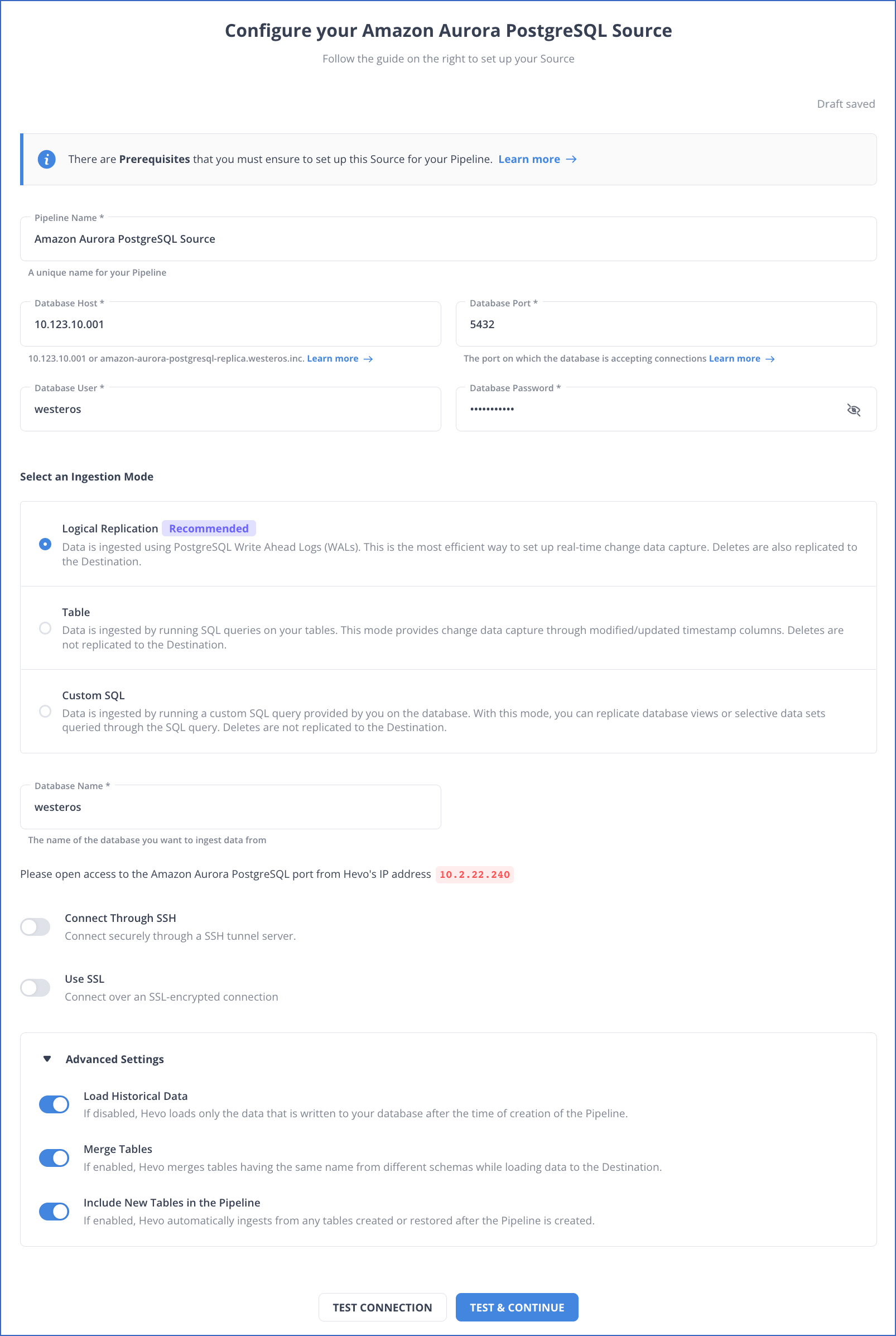
Step 2: Configure Redshift as your destination.
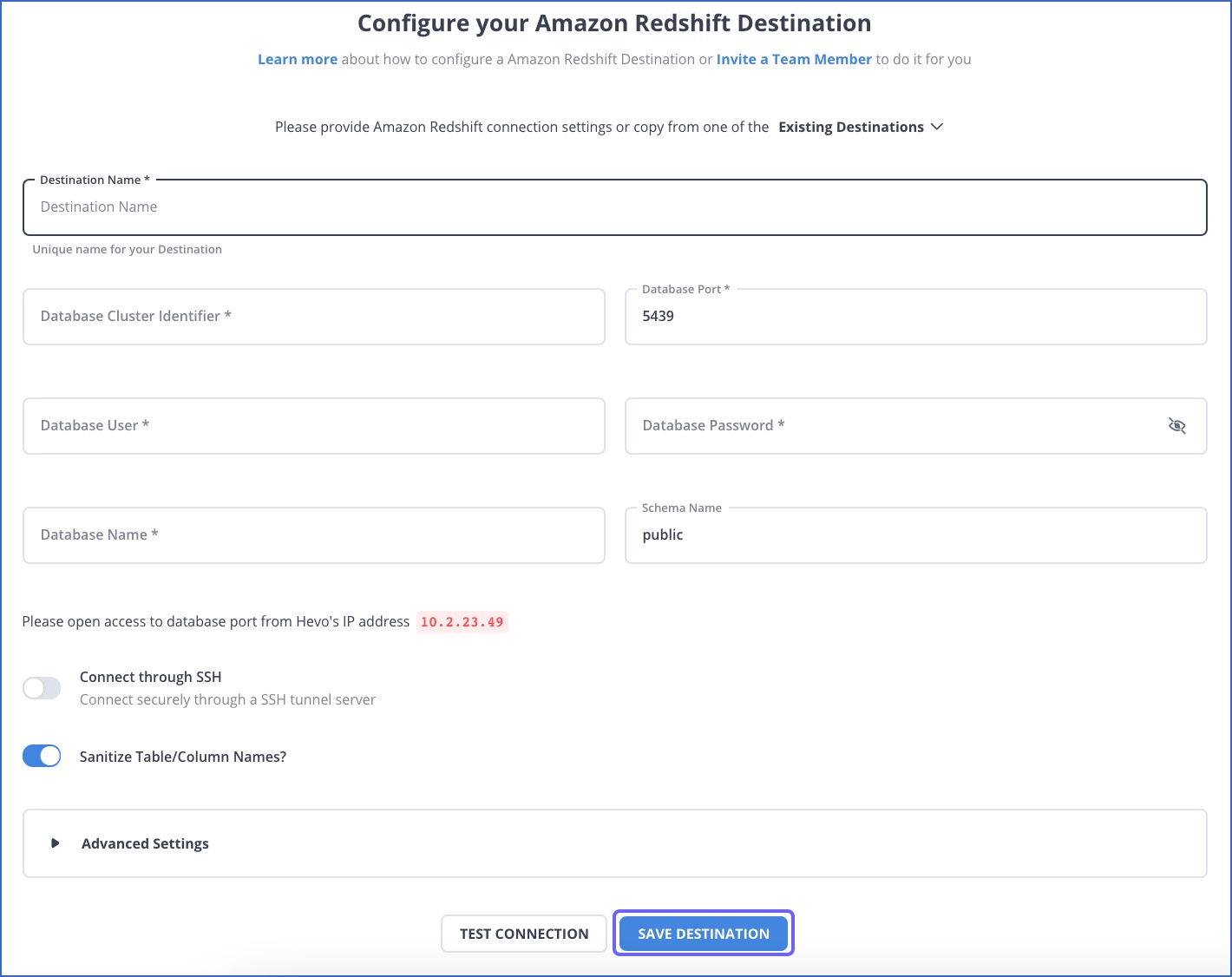
You can perform more such migrations easily within 1-minute through Hevo. Don’t just take our word for it, Try hevo and experience seamless data migration yourself.
What are the Steps to Move Data from Aurora to Redshift using AWS Glue?
You can follow the below-mentioned steps to connect Aurora to Redshift using AWS Glue:
Step 1: Select the data from Aurora as shown below.

Step 2: Go to AWS Glue and add connection details for Aurora as shown below.




Similarly, add connection details for Redshift in AWS Glue using a similar approach.
Step 3: Once connection details are created create a data catalog for Aurora and Redshift as shown by the image below.



Once the crawler is configured, it will look as shown below:

Step 4: Similarly, create a data catalog for Redshift, you can choose schema name in the Include path so that the crawler only creates metadata for that schema alone. Check the content of the Include path in the image shown below.

Step 5: Once both the data catalog and data connections are ready, start creating a job to export data from Aurora to Redshift as shown below.




Step 6: Once the mapping is completed, it generates the following code along with the diagram as shown by the image below.

Once the execution is completed, you can view the output log as shown below.

Step 7: Now, check the data in Redshift as shown below.

Advantages of Moving Data using AWS Glue
AWS Glue has significantly eased the complicated process of moving data from Aurora to Redshift. Some of the advantages of using AWS Glue for moving data from Aurora to Redshift include:
- The biggest advantage of using this approach is that it is completely serverless and no resource management is needed.
- You pay only for the time of query and based on the data per unit (DPU) rate.
- If you moving high volume data, you can leverage Redshift Spectrum and perform Analytical queries using external tables. (Replicate data from Aurora and S3 and hit queries over)
- Since AWS Glue is a service provided by AWS itself, this can be easily coupled with other AWS services i.e., Lambda and Cloudwatch, etc to trigger the next job processing or for error handling.

Limitations of Moving Data using AWS Glue
Though AWS Glue is an effective approach to move data from Aurora to Redshift, there are some limitations associated with it. Some of the limitations of using AWS Glue for moving Data from Aurora to Redshift include:
- AWS Glue is still a new AWS service and is in the evolving stage. For complex ETL logic, it may not be recommended. Choose this approach based on your Business logic
- AWS Glue is still available in the limited region. For more details, kindly refer to AWS documentation.
- AWS Glue internally uses Spark environment to process the data hence you will not have any other option to select any other environment if your business/use case demand so.
- Invoking dependent job and success/error handling requires knowledge of other AWS data services i.e. Lambda, Cloudwatch, etc.
Conclusion
The approach to use AWS Glue to set up Aurora to Redshift integration is quite handy as this avoids doing instance setup and other maintenance. Since AWS Glue provides data cataloging, if you want to move high-volume data, you can move data to S3 and leverage features of Redshift Spectrum from the Redshift client. However, unlike using AWS DMS to move Aurora to Redshift, AWS Glue is still in an early stage.
Learn how to transfer data from AWS Glue to Redshift to enhance your data integration. Our guide provides clear steps for efficient data migration.
Job and multi-job handling or error handling requires a good knowledge of other AWS services. On the other hand in DMS, you just need to set up replication instances and tasks, and not much handling is needed. Another limitation with this method is that AWS Glue is still in a few selected regions. So, all these aspects need to be considered in choosing this procedure for migrating data from Aurora to Redshift.
If you are planning to use AWS DMS to move data from Aurora to Redshift then you can check out our article to explore the steps to move Aurora to Redshift using AWS DMS.
Businesses can use automated platforms like Hevo Data to set this integration and handle the ETL process. It helps you directly transfer data from a source of your choice to a Data Warehouse, Business Intelligence tools, or any other desired destination in a fully automated and secure manner without having to write any code and will provide you a hassle-free experience.
Sign up for a 14-day free trial and experience the feature-rich Hevo suite first hand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
Frequently Asked Questions
1. Is Aurora OLAP or OLTP?
Amazon Aurora is designed as an OLTP (Online Transaction Processing) database, optimized for high-transaction, low-latency operations.
2. What is aurora zero ETL?
Aurora Zero ETL enables near-real-time data replication from Aurora to Amazon Redshift without ETL processing, facilitating seamless analytics.
3. How is Redshift different from RDS?
Amazon Redshift is an OLAP (analytical) database suited for data warehousing and large-scale analytics, whereas Amazon RDS supports OLTP databases (like Aurora) for transaction processing.
Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



