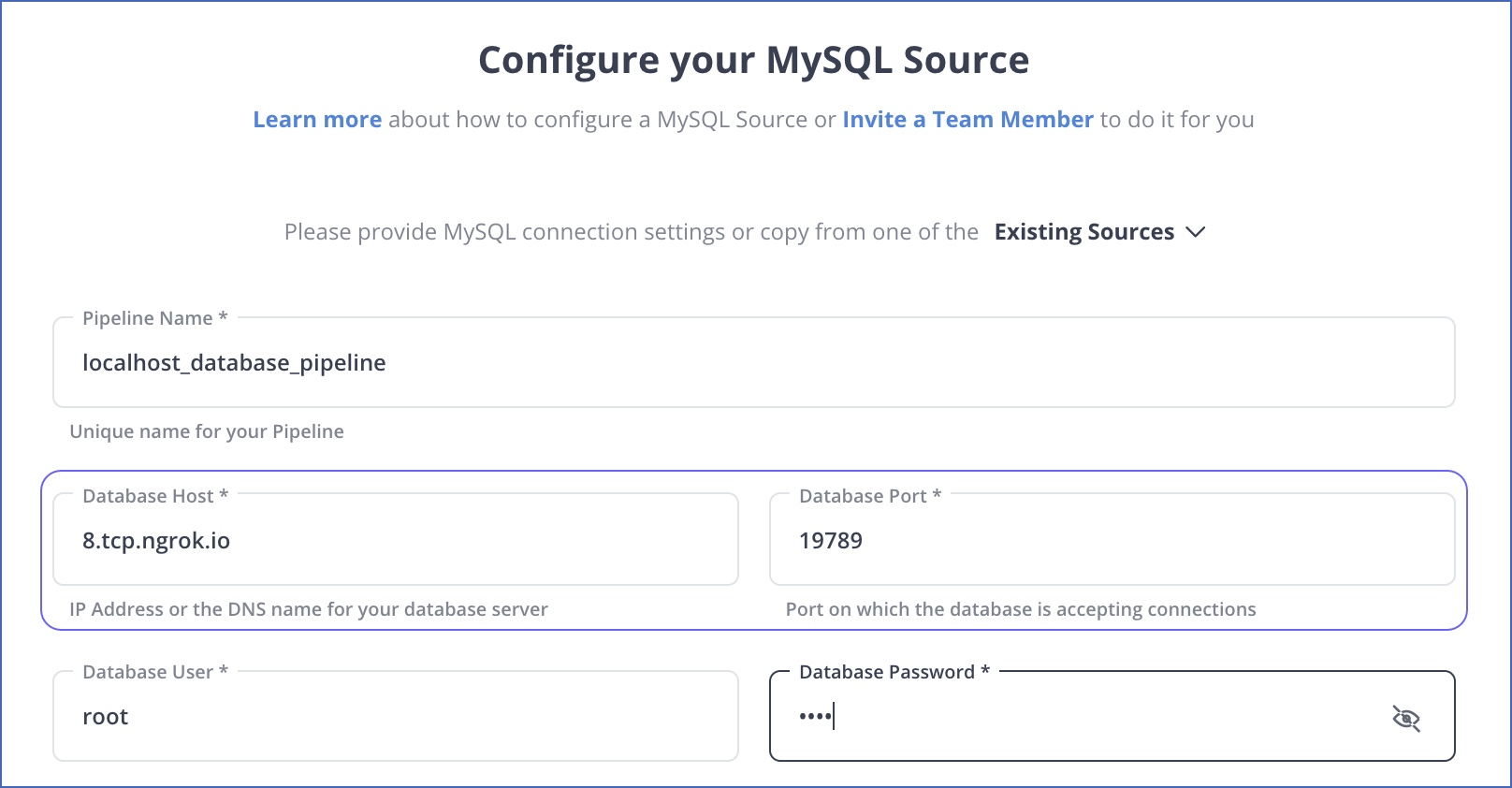
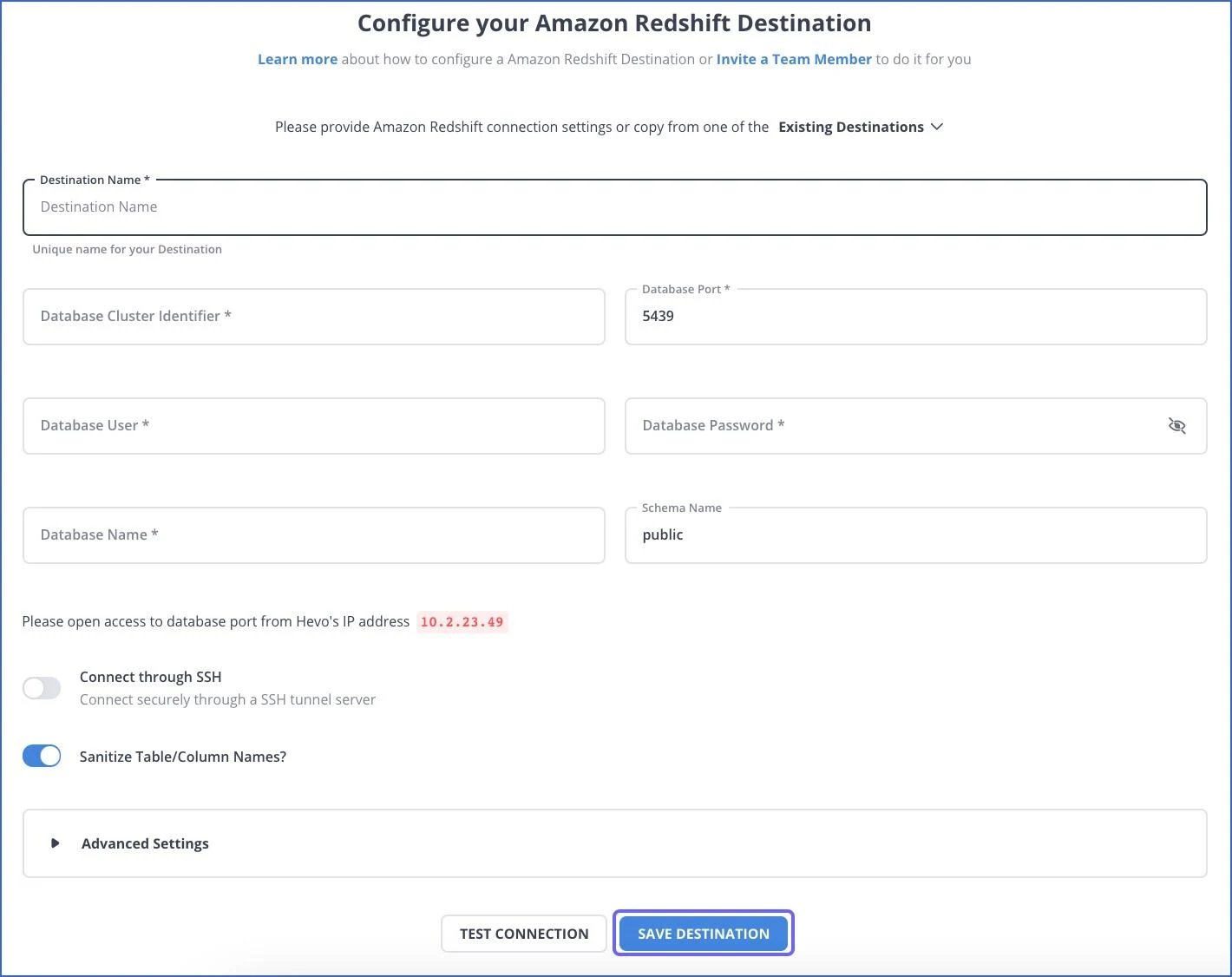
Migrate data from MySQL to Redshift using Hevo Data for no-code, real-time transfer. Alternatively, use AWS DMS or export to S3 and load via Redshift's COPY command
Method 1: Incremental Load for MySQL to Redshift Integration
Step 1: Dump the Data into Files
The most efficient way to load data into Amazon Redshift is using the COPY command with CSV/JSON files. Therefore, the first step is to convert data from a MySQL database into CSV/JSON files.
Using mysqldump command
mysqldump -h mysql_host -u user database_name table_name --result-file table_name_data.sql
The above command will dump data from a table table_name to the file table_name_data.sql. But, the file will not be in CSV/JSON format required for loading into Amazon Redshift. This is how a typical row may look like in the output file:
mysql -B -u user database_name -h mysql_host
-e "SELECT * FROM table_name;" |
sed "s/'/'/;s/t/","/g;s/^/"/;s/$/"/;s/n//g"
> table_name_data.csv
You will have to do this for all tables:
for tb in $(mysql -u user -ppassword database_name -sN -e "SHOW TABLES;"); do echo ..... done
Step 2: Clean and Transform
There might be several transformations required before you load this data into Amazon Redshift. e.g. ‘0000-00-00’ is a valid DATE value in MySQL but in Redshift, it is not.
Redshift accepts ‘0001-01-01’ though. Apart from this, you may want to clean up some data according to your business logic, you may want to make time zone adjustments, concatenate two fields, or split a field into two. All these operations will have to be done over files and will be error-prone.
Step 3: Upload to S3 and Import into Amazon Redshift
Once you have the files to be imported ready, you will upload them to an S3 bucket. Then run copy command:
for tb in $(mysql -u user -ppassword database_name -sN -e "SHOW TABLES;"); do
echo .....;
done
Again, the above operation has to be done for every table.
Once the COPY has been run, you can check the stl_load_errors table for any copy failures. After completing the aforementioned steps, you can migrate MySQL to Redshift successfully.
In a happy scenario, the above steps should just work fine. However, in real-life scenarios, you may encounter errors in each of these steps. e.g. :
Network failures or timeouts during dumping MySQL data into files.
Errors encountered during transforming data due to an unexpected entry or a new column that has been added
Network failures during S3 Upload.
Timeout or data compatibility issues during Redshift COPY. COPY might fail due to various reasons, a lot of them will have to be manually looked into and retried
Challenges of Connecting MySQL to Redshift using Custom ETL Scripts
The custom ETL method to connect MySQL to Redshift is effective. However, there are certain challenges associated with it. Below are some of the challenges that you might face while connecting MySQL to Redshift:
In cases where data needs to be moved once or in batches only, the custom script method works. This approach fails if you have to move data from MySQL to Redshift in real-time.
Incremental load (change data capture) becomes tedious as there will be additional steps that you need to follow to achieve the connection.
Often, when you write code to extract a subset of data, those scripts break as the source schema keeps changing or evolving. This can result in data loss.
The process mentioned above is brittle, error-prone, and often frustrating. These challenges impact the consistency and accuracy of the data available in your Amazon Redshift in near real-time. These were the common challenges that most users find while connecting MySQL to Redshift.
Method 2: Change Data Capture With Binlog
The process of applying changes made to data in MySQL to the destination Redshift table is called Change Data Capture (CDC).
You need to use the Binary Change Log (binlog) in order to apply the CDC technique to a MySQL database. Replication may occur almost instantly when change data is captured as a stream using Binlog.
Binlog records table structure modifications like ADD/DROP COLUMN in addition to data changes like INSERT, UPDATE, and DELETE. Additionally, it guarantees that Redshift also deletes records that are removed from MySQL.
Getting Started with Binlog
When you use CDC with Binlog, you are actually writing an application that reads, transforms, and imports streaming data from MySQL to Redshift.
You may accomplish this by using an open-source module called mysql-replication-listener. A streaming API for real-time data reading from MySQL bBnlog is provided by this C++ library. For a few languages, such as python-mysql-replication (Python) and kodama (Ruby), a high-level API is also offered.
Drawbacks using Binlog
Building your CDC application requires serious development effort.
Apart from the above-mentioned data streaming flow, you will need to construct:
Transaction management: In the event that a mistake causes your program to terminate while reading Binlog data, monitor data streaming performance. You may continue where you left off, thanks to transaction management.
Data buffering and retry: Redshift may also stop working when your application is providing data. Unsent data must be buffered by your application until the Redshift cluster is back up. Erroneous execution of this step may result in duplicate or lost data.
Table schema change support: A modification to the table schema The ALTER/ADD/DROP TABLE Binlog event is a native MySQL SQL statement that isn’t performed natively on Redshift. You will need to convert MySQL statements to the appropriate Amazon Redshift statements in order to enable table schema updates.
Method 3: Using custom ETL scripts
Step 1: Configuring a Redshift cluster on Amazon
Make that a Redshift cluster has been built, and write down the database name, login, password, and cluster endpoint.
Step 2: Creating a custom ETL script
Select a familiar and comfortable programming language (Python, Java, etc.).
Install any required libraries or packages so that your language can communicate with Redshift and MySQL Server.
Step 3: MySQL data extraction
Connect to the MySQL database.
Write a SQL query to extract the data you need. You can use this query in your script to pull the data.
Step 4: Data Transformation
You can perform various data transformations using Python's data manipulation libraries like 'pandas'.
Step 5: Redshift Data loading
With the received connection information, establish a connection to Redshift.
Run the required instructions in order to load the data. This might entail establishing schemas, putting data into tables, and generating them.
Step 6: Error handling, scheduling, testing, deployment, and monitoring
Try-catch blocks should be used to handle errors. Moreover, messages can be recorded to a file or logging service.
To execute your script at predetermined intervals, use a scheduling application such as Task Scheduler (Windows) or `cron` (Unix-based systems).
Make sure your script handles every circumstance appropriately by thoroughly testing it with a variety of scenarios.
Install your script on the relevant environment or server.
Set up your ETL process to be monitored. Alerts for both successful and unsuccessful completions may fall under this category. Examine your script frequently and make any necessary updates.
Don't forget to change placeholders with your real values (such as `}, `}, `}, etc.). In addition, think about enhancing the logging, error handling, and optimizations in accordance with your unique needs.
Disadvantages of using ETL scripts for MySQL Redshift Integration
Error Handling and Recovery: It can be challenging to create effective mistake management and recovery procedures. Handling various errors is crucial for ensuring the reliability of the ETL process.
Lack of GUI: Without a Graphical User Interface (GUI), the ETL flow could be more difficult to understand and debug.
Dependencies and environments: Custom scripts might not function correctly across all operating systems without specific modifications.
Timelines: Developing a custom script could be more time-consuming compared to building ETL processes using a visual tool.
Complexity and maintenance: Creating, testing, and maintaining custom-made (bespoke) scripts requires a greater amount of effort.
Restricted Scalability: Performance problems could emerge due to the scripts' inability to manage intricate data transformations or very large quantities of data.
Security issues: Careful supervision is necessary when handling sensitive data and login credentials within scripts to ensure security.
Method 1: Incremental Load for MySQL to Redshift Integration
Step 1: Dump the Data into Files
The most efficient way to load data into Amazon Redshift is using the COPY command with CSV/JSON files. Therefore, the first step is to convert data from a MySQL database into CSV/JSON files.
Using mysqldump command
mysqldump -h mysql_host -u user database_name table_name --result-file table_name_data.sql
The above command will dump data from a table table_name to the file table_name_data.sql. But, the file will not be in CSV/JSON format required for loading into Amazon Redshift. This is how a typical row may look like in the output file:
mysql -B -u user database_name -h mysql_host
-e "SELECT * FROM table_name;" |
sed "s/'/'/;s/t/","/g;s/^/"/;s/$/"/;s/n//g"
> table_name_data.csv
You will have to do this for all tables:
for tb in $(mysql -u user -ppassword database_name -sN -e "SHOW TABLES;"); do echo ..... done
Step 2: Clean and Transform
There might be several transformations required before you load this data into Amazon Redshift. e.g. ‘0000-00-00’ is a valid DATE value in MySQL but in Redshift, it is not.
Redshift accepts ‘0001-01-01’ though. Apart from this, you may want to clean up some data according to your business logic, you may want to make time zone adjustments, concatenate two fields, or split a field into two. All these operations will have to be done over files and will be error-prone.
Step 3: Upload to S3 and Import into Amazon Redshift
Once you have the files to be imported ready, you will upload them to an S3 bucket. Then run copy command:
for tb in $(mysql -u user -ppassword database_name -sN -e "SHOW TABLES;"); do
echo .....;
done
Again, the above operation has to be done for every table.
Once the COPY has been run, you can check the stl_load_errors table for any copy failures. After completing the aforementioned steps, you can migrate MySQL to Redshift successfully.
In a happy scenario, the above steps should just work fine. However, in real-life scenarios, you may encounter errors in each of these steps. e.g. :
Network failures or timeouts during dumping MySQL data into files.
Errors encountered during transforming data due to an unexpected entry or a new column that has been added
Network failures during S3 Upload.
Timeout or data compatibility issues during Redshift COPY. COPY might fail due to various reasons, a lot of them will have to be manually looked into and retried
Challenges of Connecting MySQL to Redshift using Custom ETL Scripts
The custom ETL method to connect MySQL to Redshift is effective. However, there are certain challenges associated with it. Below are some of the challenges that you might face while connecting MySQL to Redshift:
In cases where data needs to be moved once or in batches only, the custom script method works. This approach fails if you have to move data from MySQL to Redshift in real-time.
Incremental load (change data capture) becomes tedious as there will be additional steps that you need to follow to achieve the connection.
Often, when you write code to extract a subset of data, those scripts break as the source schema keeps changing or evolving. This can result in data loss.
The process mentioned above is brittle, error-prone, and often frustrating. These challenges impact the consistency and accuracy of the data available in your Amazon Redshift in near real-time. These were the common challenges that most users find while connecting MySQL to Redshift.
Method 2: Change Data Capture With Binlog
The process of applying changes made to data in MySQL to the destination Redshift table is called Change Data Capture (CDC).
You need to use the Binary Change Log (binlog) in order to apply the CDC technique to a MySQL database. Replication may occur almost instantly when change data is captured as a stream using Binlog.
Binlog records table structure modifications like ADD/DROP COLUMN in addition to data changes like INSERT, UPDATE, and DELETE. Additionally, it guarantees that Redshift also deletes records that are removed from MySQL.
Getting Started with Binlog
When you use CDC with Binlog, you are actually writing an application that reads, transforms, and imports streaming data from MySQL to Redshift.
You may accomplish this by using an open-source module called mysql-replication-listener. A streaming API for real-time data reading from MySQL bBnlog is provided by this C++ library. For a few languages, such as python-mysql-replication (Python) and kodama (Ruby), a high-level API is also offered.
Drawbacks using Binlog
Building your CDC application requires serious development effort.
Apart from the above-mentioned data streaming flow, you will need to construct:
Transaction management: In the event that a mistake causes your program to terminate while reading Binlog data, monitor data streaming performance. You may continue where you left off, thanks to transaction management.
Data buffering and retry: Redshift may also stop working when your application is providing data. Unsent data must be buffered by your application until the Redshift cluster is back up. Erroneous execution of this step may result in duplicate or lost data.
Table schema change support: A modification to the table schema The ALTER/ADD/DROP TABLE Binlog event is a native MySQL SQL statement that isn’t performed natively on Redshift. You will need to convert MySQL statements to the appropriate Amazon Redshift statements in order to enable table schema updates.
Method 3: Using custom ETL scripts
Step 1: Configuring a Redshift cluster on Amazon
Make that a Redshift cluster has been built, and write down the database name, login, password, and cluster endpoint.
Step 2: Creating a custom ETL script
Select a familiar and comfortable programming language (Python, Java, etc.).
Install any required libraries or packages so that your language can communicate with Redshift and MySQL Server.
Step 3: MySQL data extraction
Connect to the MySQL database.
Write a SQL query to extract the data you need. You can use this query in your script to pull the data.
Step 4: Data Transformation
You can perform various data transformations using Python's data manipulation libraries like 'pandas'.
Step 5: Redshift Data loading
With the received connection information, establish a connection to Redshift.
Run the required instructions in order to load the data. This might entail establishing schemas, putting data into tables, and generating them.
Step 6: Error handling, scheduling, testing, deployment, and monitoring
Try-catch blocks should be used to handle errors. Moreover, messages can be recorded to a file or logging service.
To execute your script at predetermined intervals, use a scheduling application such as Task Scheduler (Windows) or `cron` (Unix-based systems).
Make sure your script handles every circumstance appropriately by thoroughly testing it with a variety of scenarios.
Install your script on the relevant environment or server.
Set up your ETL process to be monitored. Alerts for both successful and unsuccessful completions may fall under this category. Examine your script frequently and make any necessary updates.
Don't forget to change placeholders with your real values (such as `}, `}, `}, etc.). In addition, think about enhancing the logging, error handling, and optimizations in accordance with your unique needs.
Disadvantages of using ETL scripts for MySQL Redshift Integration
Error Handling and Recovery: It can be challenging to create effective mistake management and recovery procedures. Handling various errors is crucial for ensuring the reliability of the ETL process.
Lack of GUI: Without a Graphical User Interface (GUI), the ETL flow could be more difficult to understand and debug.
Dependencies and environments: Custom scripts might not function correctly across all operating systems without specific modifications.
Timelines: Developing a custom script could be more time-consuming compared to building ETL processes using a visual tool.
Complexity and maintenance: Creating, testing, and maintaining custom-made (bespoke) scripts requires a greater amount of effort.
Restricted Scalability: Performance problems could emerge due to the scripts' inability to manage intricate data transformations or very large quantities of data.
Security issues: Careful supervision is necessary when handling sensitive data and login credentials within scripts to ensure security.
Forums & Community Discussions
How do you transfer a MySQL database to Amazon Redshift?
Quora discussion on moving data from MySQL database to Amazon Redshift
MySQL is an open-source relational database management system (RDBMS) based on Structured Query Language (SQL). It is one of the most popular databases for web applications and is widely used for managing and storing data. MySQL is known for its reliability, scalability, and ease of use. It supports multi-user access and can handle large volumes of data.
2. What is Amazon Redshift?
Amazon Redshift is an Amazon Web Services-based petabyte-scale Data Warehousing solution. It's also utilized for massive database migrations because it simplifies Data Management.
Organizations turn to Amazon Redshift for valuable insights from their data to enhance decision-making and operational efficiency. It is built with features of scale, usability, and integrations with other AWS services, which makes it very popular with every size of business.
Why Do We Need to Move Data from MySQL to Redshift?
Every business needs to analyze its data to get deeper insights and make smarter business decisions. However, performing Data Analytics on huge volumes of historical data and real-time data is not achievable using traditional Databases such as MySQL.
MySQL can't provide high computation power that is a necessary requirement for quick Data Analysis. Companies need Analytical Data Warehouses to boost their productivity and run processes for every piece of data at a faster and efficient rate.
Amazon Redshift is a fully managed Could Data Warehouse that can provide vast computing power to maintain performance and quick retrieval of data and results.
Moving data from MySQL to Redshift allow companies to run Data Analytics operations efficiently. Redshift columnar storage increases the query processing speed.
Conclusion
This article provided you with a detailed approach using which you can successfully connect MySQL to Redshift. You also got to know about the limitations of connecting MySQL to Redshift using the custom ETL method. Big organizations can employ this method to replicate the data and get better insights by visualizing the data. Thus, connecting MySQL to Redshift can significantly help organizations make effective decisions and stay ahead of their competitors.
If you're looking for an efficient, cost-effective way to transfer MySQL data to Redshift without the complexity of custom ETL, try Hevo. With its automated, no-code platform, Hevo ensures seamless data integration, helping you focus on insights rather than infrastructure. Sign up for Hevo's 14-day free trial and experience seamless data migration.
Not directly. However, you can connect through ETL tools like Hevo or by exporting MySQL data to S3 and loading it into Redshift.
How to load data from SQL Server to Redshift?
You can export SQL Server data to Amazon S3, then use Redshift's COPY command or ETL tools like Hevo to load it into Redshift.
Is Redshift better than MySQL?
For large-scale analytics, Redshift is generally better. MySQL is optimized for transactional tasks, while Redshift is designed for complex data warehousing and analytics.
Are you sure?
You have unsaved changes, do you really want to confirm?