



 Key Takeaways
Key TakeawaysChoose a no-code pipeline or a custom AWS Glue process for connecting BigQuery to S3
Method 1: Using Hevo
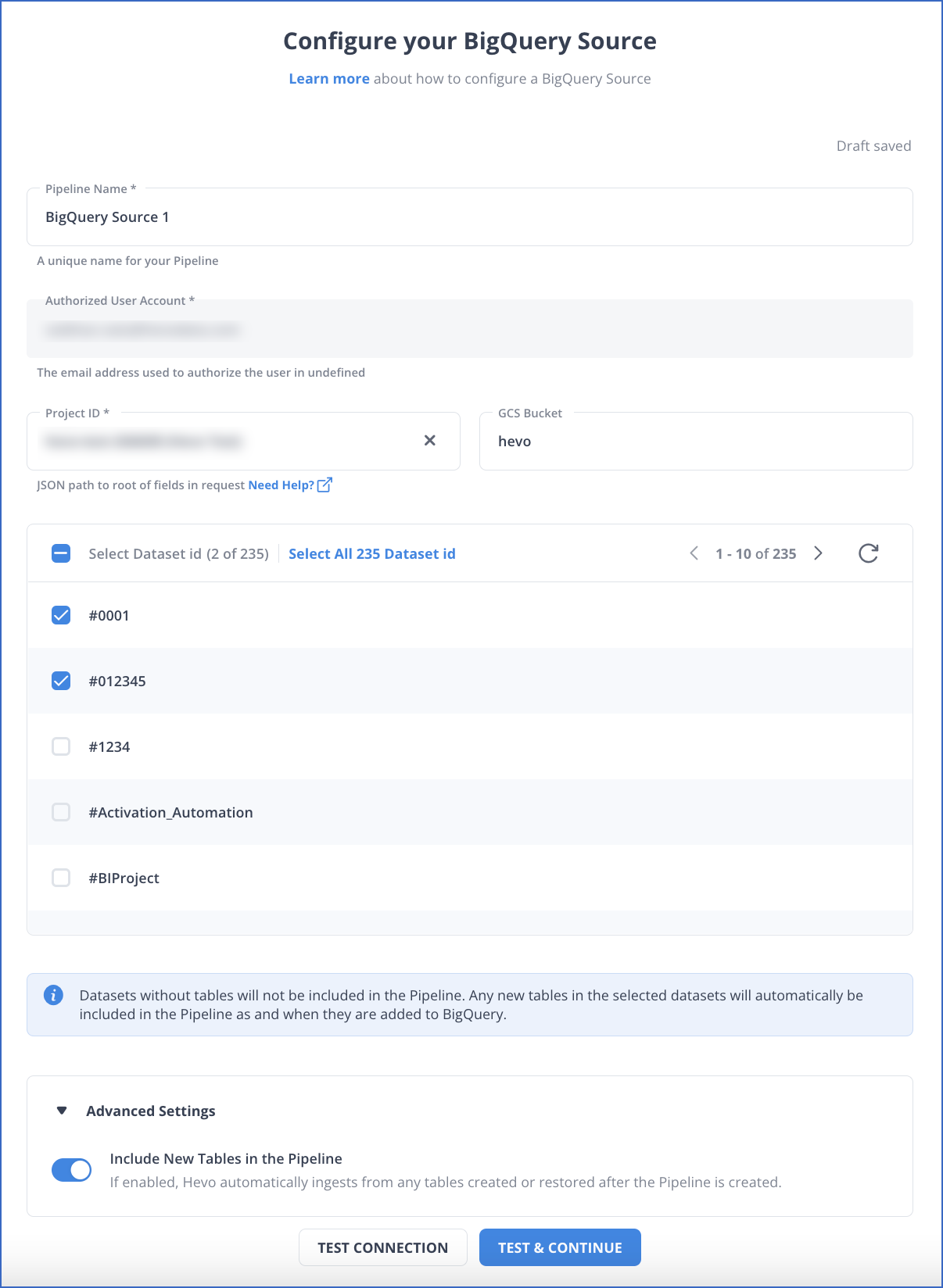
Configure BigQuery as your source in Hevo with project, dataset, and table details
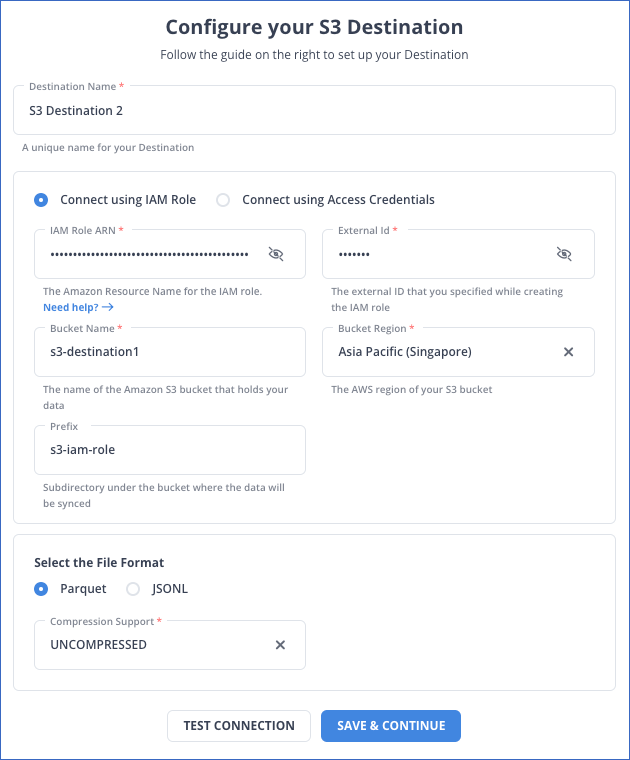
Set Amazon S3 as your destination and provide bucket name and credentials
Method 2: Using AWS Glue
Store your BigQuery service account JSON in AWS Secrets Manager
Create an IAM role for AWS Glue with S3 and Secrets Manager permissions
Subscribe to and activate the AWS Glue BigQuery connector in Glue Studio
Build and run a Glue job that reads from BigQuery and writes to your S3 bucket
With the passage of time, data has evolved into one of the most valuable assets and it is considered an important part of decision-making for any organization. Today, most of the organizations’ data is scattered across multiple public clouds. They are constantly on the lookout for solutions that make it simple to ingest data from multiple sources while also allowing them to customize the data ingestion process to their specific needs.
This article will guide you through the process of setting up BigQuery to S3 Integration using 4 simple steps. It will provide you with a brief overview of Google BigQuery and Amazon S3 along with their key features. You will also explore how to query data after setting up BigQuery to S3 Integration in further sections. Let’s get started.
Table of Contents
Introduction to Google BigQuery

- Today, most organizations are looking for ways to extract business insights from data. But it can be a challenge to ingest, store, and analyze that data when the volume and scope increase. Google’s enterprise Data Warehouse, BigQuery, has been designed to make large-scale data analysis accessible to everyone.
- Google BigQuery can handle massive amounts of data, e.g., logs from outlets of retail chains down to the SQL (Structured Query Language) level or IoT (Internet of Things) data from millions of utility meters, telecom usage, and vehicles across the globe.
- Powered by Google, BigQuery is certainly a Platform as a Service (PaaS) offering with a fully managed Data Warehouse as a serverless architecture. It enables organizations to focus on analytics instead of managing the infrastructure.
Method 1: Automatically Connect BigQuery to S3 using Hevo Data
Hevo Data provides a seamless BigQuery to S3 Integration without having to deal with lengthy pieces of code in just two steps. As Hevo is a centrally managed platform, there would be no need for manual interventions.
Method 2: Manual BigQuery S3 Integration using Custom Codes
This method involves manually setting up the BigQuery S3 connection using custom codes.
Get Started with Hevo for FreeKey Features of Google BigQuery
Some of the key features of Google BigQuery include:
- Real-Time Analytics: Google BigQuery offers Real-Time Analytics based upon high-speed streaming insertion API (Application Programming Interface). The user just needs to incorporate the real-time data and Google BigQuery can analyze it instantaneously.
- Fully Managed Platform: Being a fully managed provision, one doesn’t need to set up or install anything and even doesn’t need the Database Administrator. One can simply log in to the google cloud project from a browser and get started.
- Data Transfer Service: Google BigQuery also supports the Data Transfer Service via which users can get data from multiple sources on a scheduled basis e.g., Google Marketing Platform, Google Ads, YouTube, Partner SaaS applications to BigQuery, Teradata, and Amazon S3.
- Automatic Backup and Restore: Google BigQuery offers automatic Backup and Restore options. It keeps track of the performed changes on a 7-days basis so that comparison with previous versions can be done if necessary and recall any changes accordingly.
Learn more about Google BigQuery.
Introduction to Amazon S3

- Amazon Simple Storage Service generally referred to as Amazon S3, is a storage solution that is characterized by top-of-the-line Scalability, Performance, Security, and Data Availability as far as the evolving realm of Information Communication and Technology (ICT) is concerned.
- The enterprises may vary in the scale of their operations and the relevant industry sector, yet Amazon S3 can be used by all of them for storage and protection of data.
- The use-cases of data storage via Amazon S3 cover a wide array of dimensions which may include but aren’t limited to IoT Frameworks, Mobile Applications, Enterprise Applications, Big Data Analytics, Data Lakes, Backup and Restore archives, and Hosting of Websites, etc.
- It provides a sheer amount of control to the concerned management for organizing, optimizing, and configuring access to the stored data for meeting the outlined compliance, business, and organizational requirements.
- Ingesting data from amazon s3 to bigquery is a common pattern for building large-scale analytics and data warehousing solutions.
- A holistic overview of how Amazon S3 works is as follows:

Key Features of Amazon S3
Some of the key features of Amazon S3 include:
- Storage Classes: Based upon the user access frequency, Amazon S3 offers a variety of Storage Classes optimized for different use-cases. For example, for storing the mission-critical enterprise information which would require frequent access by concerned individuals, S3 Standard Access can be used.
- Storage Management: Amazon S3 offers a host of information Storage Management features that can be leveraged to optimize the cost, meet regulatory requirements, reduce latency, and save various copies of the concerned data sets, essential for compliance requirements.
- Data Processing: Not only does Amazon S3 allow for storage but also assists in Data Processing for transforming data and triggering workflows so that automation of processes can be enabled at a larger scale. For efficient management of objects at scale, S3 Batch Operations can perform actions on millions of items at once, each identified by its unique S3 key.
- Storage Logging and Monitoring: Many automated and manual account logging and monitoring features accompany the data storage in Amazon S3 which enable the efficient monitoring and control of data resources.
- Programmatic access to S3 is achieved through a well-documented Amazon S3 REST API integration, allowing for custom application development.
- Analytics and Insights: Getting visibility into the stored data can be done in Amazon S3 via a host of tools including Amazon S3 Storage Lens, Storage Class Analysis, and S3 Inventory with Inventory Reports.
Learn more about Amazon S3.
Prerequisites
You will have a much easier time connecting BigQuery to S3 if you have gone through the following prerequisites:
- An active Google Cloud Platform account.
- An active Amazon S3 account.
- You’ll need an AWS IAM (Identity and Access Management) user with an access key and a secret key to configure the AWS CLI (Command Line Interface).
Methods to Set Up BigQuery to S3 Integration
Method 1: Automatically Connect BigQuery to S3 using Hevo Data
Step 1.1: Configure BigQuery as Your Source
Step 1.2: Configure S3 as Your Destination
Why Use Hevo?
Here’s how Hevo challenges the normal to beget the new ‘exceptional.’
- Fully Managed: Hevo requires no management and maintenance as it is a fully automated platform.
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insight Generation: Hevo offers near real-time data replication, so you have access to real-time insight generation and faster decision making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Scalable Infrastructure: As your sources and the volume of data grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.

Method 2: Manual BigQuery S3 Integration using Custom Codes
Now that you have a basic grasp of both tools let’s try to understand the steps to take to set up BigQuery to S3 Integration. Extracting data from BigQuery to S3 is a very convenient process with the use of the tool named AWS Glue. The pictorial representation is given below:

Below are the steps you can follow to connect BigQuery to S3:
- Step 1: Configuring Google Account
- Step 2: Creating an AWS Glue IAM Role
- Step 3: Subscribing to Glue for BigQuery Connector
- Step 4: Building the ETL Jobs for BigQuery to S3
Step 2.1: Configuring Google Account
The first step in setting up BigQuery to S3 Integration is to configure the Google Account. The Google account needs to be configured for the subject transfer. You can follow the below-mentioned procedures to configure your Google account:
- Download the Service Account Credentials in the form of JSON files via Google Cloud.
- On the Secrets Manager console, choose Store a new secret.
- For Secret type, select Other type of secrets as shown below.

- Next, enter your key as credentials and the value as the base64-encoded string.
- Leave the rest of the options at their default.
- Click on Next.
- Give a name to the secret bigquery_credentials.
- Follow through the rest of the steps to store the secret.
Step 2.2: Creating an AWS Glue IAM Role
After you have successfully configured your Google account to set up BigQuery to S3 Integration, you can follow the below-mentioned procedures to create an AWS Glue IAM Role:
- Attach the relevant policies i.e., AmazonEC2ContainerRegistryReadOnly & AWSGlueServiceRole (AWS managed) for creation of IAM role, given the requisite permissions for the AWS Glue job.
- Sample policy in this regard is shown below:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GetDescribeSecret",
"Effect": "Allow",
"Action": [
"secretsmanager:GetResourcePolicy",
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret",
"secretsmanager:ListSecretVersionIds"
],
"Resource": "arn:aws:secretsmanager::<<account_id>>:secret:<<your_secret_id>>"
},
{
"Sid": "S3Policy",
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket",
"s3:GetBucketAcl",
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<<your_s3_bucket>>",
"arn:aws:s3:::<<your_s3_bucket>>/*"
]
}
]
}Step 2.3: Subscribing to Glue for BigQuery Connector
To subscribe to the connector, you can complete the following steps:
- Navigate to the AWS Glue Connector for Google BigQuery on AWS Marketplace.
- Select Continue to Subscribe as shown below.

- Review the terms and conditions, pricing, and other details.
- Click on Continue to Configuration.
- For Delivery Method, choose your delivery method.
- For Software Version, choose your software version.
- Next, click on Continue to Launch as shown below.

- Under Usage instructions, select Activate the Glue connector in AWS Glue Studio as shown below.

- For Name, enter a name for your connection (for example, bigquery) as shown below.

- Optionally, choose a VPC (Virtual Private Cloud), subnet, and security group.
- For AWS Secret, choose bigquery_credentials.
- Next, click on Create connection.
Step 2.4: Building the ETL Jobs for BigQuery S3 Integration
Now, you can build the ETL jobs for BigQuery to S3 integration using the below-mentioned procedures:
- On Glue Studio, choose Jobs.
- For Source, choose BigQuery.
- For Target, choose S3.
- Next, click on Create as shown below.

- Choose ApplyMapping and delete it.
- Choose BigQuery.
- For Connection, choose bigguery.
- Expand Connection options.
- Click on the Add new option button as shown below.

- Add following Key/Value.
- Key: parentProject, Value: <<google_project_id>>
- Key: table, Value: bigquery-public-data.covid19_open_data.covid19_open_data

- Choose S3 bucket.
- Choose format and Compression Type.
- Specify S3 Target Location.

- Choose Job details.
- For Name, enter BigQuery_S3.
- For IAM Role, choose the role you created.
- For Type, choose Spark.
- For the Glue version, choose Glue 2.0 – Supports Spark 2.4, Scala 2, Python3.
- Leave the rest of the options as defaults.
- Click on Save.
- To run the job, Click the Run button as shown below.

- Once the job run succeeds, check the S3 bucket for data.

With this, you have successfully set up your BigQuery S3 Integration. It’s as simple as that.
Also Check Out:
Querying Data after Setting Up BigQuery to S3 Integration
Once the integration of BigQuery to S3 is successful, Glue Crawlers can be used to get the data in the S3 bucket; a covid table is created and data can be queried accordingly. A sample demonstration is shown below:

Key Takeaways
- One can see that integrating BigQuery to S3 complements the processing power of the former while the latter serves as a catalyst in this regard.
- Given the increased dependence of enterprises on ICT, and as the threats of cybersecurity are also evolving, this integration adds a lot of value to business operations.
- It can surely be concluded that BigQuery to S3 Integration further complements the process of information storage and extraction, thus enabling the users to derive key insights which result in efficient and effective managerial decisions.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
FAQs
1. How do I connect Google BigQuery to AWS?
To connect Google BigQuery to AWS, you can use data transfer tools like Google Cloud Storage Transfer Service, AWS Data Transfer, or third-party tools such as Fivetran or Hevo to move data between BigQuery and AWS services like S3.
2. What is GCP equivalent to S3?
The GCP equivalent to AWS S3 is Google Cloud Storage, which offers scalable and secure object storage similar to S3.
3. What is the AWS equivalent of BigQuery?
The AWS equivalent of Google BigQuery is Amazon Redshift, which is a cloud-based data warehouse designed for large-scale data analytics.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





