

Unlock the full potential of your confluent cloud data by integrating it seamlessly with BigQuery. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
Organizations today rely on the Confluent Cloud to stream real-time data using Apache Kafka. They can use this real-time data with any popular data warehouse like Google BigQuery for further analysis. Google BigQuery can further combine with powerful BI tools such as PowerBI, Tableau, Google Data Studio, and more to gain meaningful insights into Confluent cloud data, which helps organizations make effective data-driven decisions. Organizations can connect Confluent Cloud data with Google BigQuery using Confluent BigQuery Sink Connector or third-party ETL (extract, transform and load) tools.
In this article, you will learn to connect Confluent Cloud to BigQuery using the Confluent BigQuery Sink connector.
Table of Contents
What is Confluent Cloud?

Confluent Cloud is a full-scale data streaming platform based on Apache Kafka, where businesses can access, store, and manage data in real time. It consists of a web interface, a local command-line interface, a schema Registry, a Rest proxy, and more than 100 in-built Kafka connectors and KsqlDB for administering streaming services.
With Confluent Cloud, organizations can drive business value from their data without worrying about manual processes like data transportation and data integration between different devices. Confluent Cloud simplifies processes such as connecting data sources to Kafka, building streaming applications, and securing, monitoring, and managing Kafka infrastructure.
Key Features of Confluent Cloud
- Confluent Control Center: Confluent Control Center is a GUI-based application to manage and monitor Kafka. It allows organizations to manage Kafka Connect and easily create, edit, and manage connections with other systems. Organizations can monitor data streams from producer and consumer, ensure every Kafka message is delivered, and measure how long it takes to deliver these messages. Organizations can use Control Center to build a production data pipeline based on Kafka without writing a single line of code.
- Self-Balancing: The Confluent Platform can deploy hundreds of brokers, manage thousands of Kafka topics, and handle millions of messages per hour. However, the brokers might sometimes be lost due to network issues. As a result, new topics are created, and partitions are reassigned to balance the workload. This results in generating more resource workload overhead.
- Confluent Cluster Linking: Cluster linking in Confluent Cloud is a fully managed service to move data from one Confluent cluster to another. Cluster linking creates perfect copies of your Kafka topics and programmatically keeps data in-sync across clusters. It can quickly build multi-data centers, multi-region, and hybrid cloud deployments.
Elevate your data analytics game by integrating Confluent Cloud with Google BigQuery! With Hevo, you can seamlessly move your streaming data into BigQuery for powerful insights and analysis. Ensure seamless data migration using features like:
- Seamless integration with your desired data warehouse, such as BigQuery.
- Transform and map data easily with drag-and-drop features.
- Real-time data migration to leverage AI/ML features of BigQuery.
Still not sure? See how Postman, the world’s leading API platform, used Hevo to save 30-40 hours of developer efforts monthly and found a one-stop solution for all its data integration needs.
Get Started with Hevo for FreeWhat is Google BigQuery?

With Google BigQuery, you can utilize the processing power of Google’s infrastructure to run quick SQL queries in a fully managed, serverless data warehouse. With features like exabyte-scale storage and petabyte-scale SQL queries, Google BigQuery satisfies your big data processing needs rapidly and performs incredibly well even when analyzing massive volumes of data.
Benefits of BigQuery
- It is simple to set up and use without worrying about infrastructure management.
- One can create machine learning models using basic SQL by simply using SQL queries.
- You can analyze streaming data sources in real-time using BigQuery.
- With BigQuery, users can perform analytics on real-time streaming data sources.
- You only pay for the volume of data processed, making this a relatively low-cost alternative for companies of different sizes.
Connecting Confluent Cloud to BigQuery
- Method 1: Using Hevo to Set Up Confluent Cloud to BigQuery
- Method 2: Using Custom Code to Move Data from Confluent Cloud to BigQuery
Method 1: Using Hevo to Set Up Confluent Cloud to BigQuery
Step 1: Configure Confluent Cloud as your source.
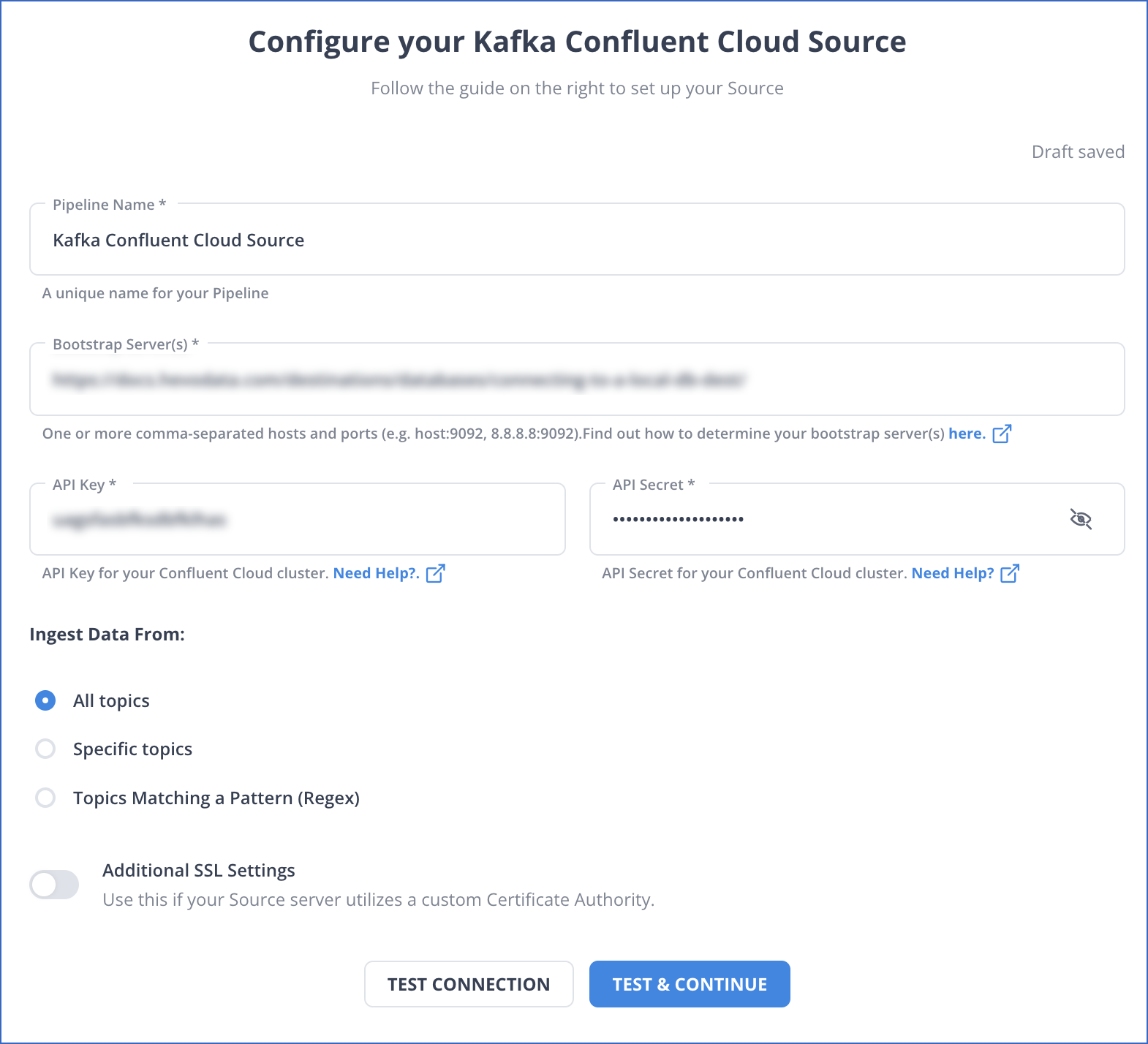
Step 4: Configure BigQuery as your Destination.

Method 2: Using Custom Code to Move Data from Confluent Cloud to BigQuery
This method of connecting Confluent Cloud to BigQuery uses a custom code approach. This method would be time-consuming and somewhat tedious to implement. Users will have to write custom codes to enable Confluent Cloud to BigQuery migration. This method of connecting Confluent Cloud to BigQuery is suitable for users with a technical background. You can use the Confluent Cloud to BigQuery Sink connector for exporting Confluent Cloud to BigQuery.
Confluent Cloud allows businesses to store their real-time data by automating processes like creating clusters and Kafka topics. The Sink connector can create BigQuery tables with the appropriate BigQuery table schema when streaming data from Confluent Cloud with registered schemas. Follow the below steps to connect Confluent Cloud to BigQuery.
- Install the BigQuery Connector
This is the first step to connecting Confluent Cloud to BigQuery. Install the BigQuery Connector using the Confluent hub client or download the zip file manually using the below command.
confluent-hub install wepay/kafka-connect-bigquery:latestYou can install a dedicated version of the connector by replacing “latest” with a version number. For example:
confluent-hub install wepay/kafka-connect-bigquery:1.1.2The Confluent Cloud to BigQuery Sink connector can stream table records from Kafka topics to Google BigQuery. The table records are streamed at high throughput rates to facilitate analytical queries in real-time. In this tutorial, you need to run the Confluent platform locally.
Go to your Confluent platform installation directory and enter the below command.
confluent-hub install wepay/kafka-connect-bigquery:latestAdding a new connector plugin for the Confluent Cloud to BigQuery Sink connector requires restarting Kafka Connect. Using the below command, you can use the Confluent CLI to restart Kafka Connect.
confluent local stop connect && confluent local start connect
Using CONFLUENT_CURRENT: /Users/username/Sandbox/confluent-snapshots/var/confluent.NuZHxXfq
Starting zookeeper
zookeeper is [UP]
Starting kafka
kafka is [UP]
Starting schema-registry
schema-registry is [UP]
Starting kafka-rest
kafka-rest is [UP]
Starting connect
connect is [UP]Verify that the installed BigQuery Sink connector plugin is installed correctly, using the below command.
curl -sS localhost:8083/connector-plugins | jq .[].class | grep BigQuerySinkConnector
"com.wepay.kafka.connect.bigqueryl.BigQuerySinkConnector"- Setting up the Google Cloud Platform BigQuery Connector
- Ensure that you have the below prerequisites for setting up the connector.
- An active Google Cloud Platform account.
- A BigQuery project. You can build the project using the Google Cloud Console.
- A BigQuery dataset.
- A service account to access the BigQuery project containing the dataset. While creating the service account, you can create and download a key as a JSON file, as shown in the example below.
- Ensure that you have the below prerequisites for setting up the connector.
{
"type": "service_account",
"project_id": "confluent-842583",
"private_key_id": "...omitted...",
"private_key": "-----BEGIN PRIVATE ...omitted... =\n-----END PRIVATE KEY-----\n",
"client_email": "confluent2@confluent-842583.iam.gserviceaccount.com",
"client_id": "...omitted...",
"auth_uri": "https://accounts.google.com/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/metadata/confluent2%40confluent-842583.iam.gserviceaccount.com"
}
According to `GCP specifications
<https://cloud.google.com/bigquery/docs/access-control>`__, the service
account will either need the **BigQueryEditor** primitive IAM role or the
**bigquery.dataEditor** predefined IAM role. The minimum permissions are as
follows:
.. code-block:: text
bigquery.datasets.get
bigquery.tables.create
bigquery.tables.get
bigquery.tables.getData
bigquery.tables.list
bigquery.tables.update
bigquery.tables.updateData- Starting the BigQuery Sink Connector
- Follow the below steps to start the BigQuery Sink Connector.
- Create the file named register-kcbd-connect-bigquery.json for storing the connector configuration.
- Start the connector with the below command.
- Follow the below steps to start the BigQuery Sink Connector.
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @register-kcbd-connect-bigquery.json- Start your Kafka Producer
- Follow the below steps to start your Kafka producer.
- Go to the Kafka bin folder and start the Kafka producer in a new terminal.
- Type the below commands on the terminal.
- Follow the below steps to start your Kafka producer.
./kafka-avro-console-producer --broker-list localhost:9092 --topic kcbq-quickstart1 --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}'- Enter the text of two records and press enter after each line.
./kafka-avro-console-producer --broker-list localhost:9092 --topic kcbq-quickstart1 --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}'
{"f1":"Testing the Kafka-BigQuery Connector!"}
{"f1":"Testing the Kafka-BigQuery Connector for a second time!"}- Check Results in BigQuery
- Follow the below steps to check results in BigQuery.
- Navigate to the BigQuery editor in Google Cloud Platform.
- Enter the below SQL select statement.
- Follow the below steps to check results in BigQuery.
SELECT * FROM ConfluentDataSet.quickstart1;- Clean Up Resources
- Follow the below steps to clean up the resources.
- Delete the connector.
- Follow the below steps to clean up the resources.
curl -X DELETE localhost:8083/connectors/kcbq-connect1- Stop Confluent services.
confluent local stop
Why Do We Need To Connect Confluent Cloud And Bigquery?
Connecting Confluent Cloud to bigquery has various advantages such as:
- Real-time Data Ingestion: Stream data instantly from Confluent Cloud to BigQuery for immediate analysis, enhancing decision-making.
- Scalable Analytics: Leverage BigQuery’s ability to handle large datasets and complex queries, allowing for scalable data analysis.
- Improved Data Freshness: Maintain up-to-date datasets by streaming real-time data, ensuring analytics reflect the latest information.
- Enhanced Data Integration: Combine real-time streaming data with historical data for comprehensive analytics and insights.
Conclusion
This article talks about connecting Confluent Cloud to BigQuery. Confluent Cloud helps organizations to use their real-time data streams and leverage the functionalities of Apache Kafka. It enables organizations to view and create environments, clusters, and Kafka topics more quickly, without worrying about its mechanism. Organizations can store their real-time data streams in a data warehouse like Google BigQuery to analyze the data and gain meaningful insights for better decisions.
Sign up for a 14-day free trial to reliably integrate data with Hevo’s Fully Automated No Code Data Pipeline. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
Frequently Asked Questions
1. How do I migrate from Cloud SQL to BigQuery?
-Use the built-in service to set up a transfer from Cloud SQL to BigQuery.
-Export data from Cloud SQL as CSV, JSON, or Avro files to Google Cloud Storage, then load these files into BigQuery using the BigQuery web UI or the bq command-line tool.
2. Is it possible to make a federated query from Cloud SQL to BigQuery?
Yes, it’s possible. You can use BigQuery’s federated queries to access data directly in Cloud SQL without moving it. To do this, you’ll need to configure a connection to your Cloud SQL instance from BigQuery and write SQL queries that reference the Cloud SQL tables.
3. How do I sync Cloud SQL with BigQuery?
Scheduled Queries: Use scheduled queries in BigQuery to pull data from Cloud SQL at regular intervals.
Change Data Capture (CDC): Implement CDC by using a data pipeline tool (like Dataflow) that captures changes in Cloud SQL and writes them to BigQuery.
Cloud Functions: Set up Cloud Functions to trigger on changes in Cloud SQL and push data to BigQuery as needed.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




